Creating a FeedbackDataset#
This tutorial is part of a series in which we will get to know the FeedbackDataset. Before starting this tutorial, you need to do the tutorial on configuring users and workspaces. In this step, we will show how to configure a FeedbackDataset and add FeedbackRecords to it. If you need additional context, consult our practical guide on creating a dataset.

We will start by creating a basic dataset using the ag_news dataset as an example and push it to Argilla and the Hugging Face hub.
Table of Contents#
Running Argilla#
For this tutorial, you will need to have an Argilla server running. There are two main options for deploying and running Argilla:
Deploy Argilla on Hugging Face Spaces: If you want to run tutorials with external notebooks (e.g., Google Colab) and you have an account on Hugging Face, you can deploy Argilla on Spaces with a few clicks:

For details about configuring your deployment, check the official Hugging Face Hub guide.
Launch Argilla using Argilla’s quickstart Docker image: This is the recommended option if you want Argilla running on your local machine. Note that this option will only let you run the tutorial locally and not with an external notebook service.
For more information on deployment options, please check the Deployment section of the documentation.
Tip
This tutorial is a Jupyter Notebook. There are two options to run it:
Use the Open in Colab button at the top of this page. This option allows you to run the notebook directly on Google Colab. Don’t forget to change the runtime type to GPU for faster model training and inference.
Download the .ipynb file by clicking on the View source link at the top of the page. This option allows you to download the notebook and run it on your local machine or on a Jupyter notebook tool of your choice.
First let’s install our dependencies and import the necessary libraries:
[ ]:
!pip install argilla
!pip install datasets
[1]:
import argilla as rg
from argilla._constants import DEFAULT_API_KEY
from datasets import load_dataset
In order to run this notebook we will need some credentials to push and load datasets from Argilla and 🤗hub, let’s set them in the following cell:
[2]:
# Argilla credentials
api_url = "http://localhost:6900" # "https://<YOUR-HF-SPACE>.hf.space"
api_key = DEFAULT_API_KEY # admin.apikey
# Huggingface credentials
hf_token = "hf_..."
Log to argilla:
[ ]:
#papermill_description=logging-to-argilla
rg.init(
api_url=api_url,
api_key=api_key
)
Enable Telemetry#
We gain valuable insights from how you interact with our tutorials. To improve ourselves in offering you the most suitable content, using the following lines of code will help us understand that this tutorial is serving you effectively. Though this is entirely anonymous, you can choose to skip this step if you prefer. For more info, please check out the Telemetry page.
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
Configure a FeedbackDataset#
For this tutorial we will use the ag_news dataset which can be downloaded from the 🤗hub. We will load only the first 1000 items from the training sample.
[6]:
ds = load_dataset("ag_news", split="train[:1000]")
ds
[6]:
Dataset({
features: ['text', 'label'],
num_rows: 1000
})
We will just load the first 1000 records for this tutorial, but feel free to test the full dataset.
This dataset contains a collection of news articles (we can see the content in the text column), which have been asigned one of the following classification labels: World (0), Sports (1), Business (2), Sci/Tech (3).
Let’s use the task templates to create a feedback dataset ready for text-classification.
[20]:
feedback_dataset = rg.FeedbackDataset.for_text_classification(
labels=["World", "Sports", "Business", "Sci/Tech"],
guidelines="Classify the articles into one of the four categories.",
)
feedback_dataset
[20]:
FeedbackDataset(
fields=[TextField(name='text', title='Text', required=True, type='text', use_markdown=False)]
questions=[LabelQuestion(name='label', title='Label', description='Classify the text by selecting the correct label from the given list of labels.', required=True, type='label_selection', labels=['World', 'Sports', 'Business', 'Sci/Tech'], visible_labels=None)]
guidelines=Classify the articles into one of the four categories.)
metadata_properties=[])
)
We could compare this dataset with the custom configuration we would use previously (we can take a look at the custom configuration for more information on the creation of a FeedbackDataset when we want a finer control):
[8]:
feedback_dataset_long = rg.FeedbackDataset(
guidelines="Classify the articles into one of the four categories.",
fields=[
rg.TextField(name="text", title="Text from the article"),
],
questions=[
rg.LabelQuestion(
name="label",
title="In which category does this article fit?",
labels={"World": "0", "Sports": "1", "Business": "2", "Sci/Tech": "3"},
required=True,
visible_labels=None
)
]
)
feedback_dataset_long
[8]:
FeedbackDataset(
fields=[TextField(name='text', title='Text from the article', required=True, type='text', use_markdown=False)]
questions=[LabelQuestion(name='label', title='In which category does this article fit?', description=None, required=True, type='label_selection', labels={'World': '0', 'Sports': '1', 'Business': '2', 'Sci/Tech': '3'}, visible_labels=None)]
guidelines=Classify the articles into one of the four categories.)
metadata_properties=[])
)
Add FeedbackRecords#
From a Hugging Face dataset#
The next step once we have our FeedbackDataset created is adding the FeedbackRecords to it.
In order to create our records we can just loop over the items in the datasets.Dataset.
[9]:
records = []
for i, item in enumerate(ds):
records.append(
rg.FeedbackRecord(
fields={
"text": item["text"],
},
external_id=f"record-{i}"
)
)
# We can add an external_id to each record to identify it later.
From a pandas.DataFrame#
If we had our data in a different format, let’s say a csv file, maybe it’s more direct to read the data using pandas for that.
We will transform our dataset to pandas format for this example, and the remaining FeedbackRecord creation remains just the same:
[10]:
df_dataset = ds.to_pandas()
df_dataset.head()
[10]:
| text | label | |
|---|---|---|
| 0 | Wall St. Bears Claw Back Into the Black (Reute... | 2 |
| 1 | Carlyle Looks Toward Commercial Aerospace (Reu... | 2 |
| 2 | Oil and Economy Cloud Stocks' Outlook (Reuters... | 2 |
| 3 | Iraq Halts Oil Exports from Main Southern Pipe... | 2 |
| 4 | Oil prices soar to all-time record, posing new... | 2 |
[ ]:
records_pandas = []
for i, item in df_dataset.iterrows():
records_pandas.append(
rg.FeedbackRecord(
fields={
"text": item["text"],
},
external_id=f"record-{i}"
)
)
Let’s add our records to the dataset:
[21]:
feedback_dataset.add_records(records)
By now we have our dataset with the texts ready to be labeled, let’s push it to Argilla.
Save and load a FeedbackDataset#
From Argilla#
[ ]:
#papermill_description=push-dataset-to-argilla
try:
# delete old dataset
remote_dataset = feedback_dataset.from_argilla(name="end2end_textclassification", workspace="argilla")
remote_dataset.delete()
except:
pass
remote_dataset = feedback_dataset.push_to_argilla(name="end2end_textclassification", workspace="argilla")
If we go to our Argilla instance we should see a similar screen like the following.
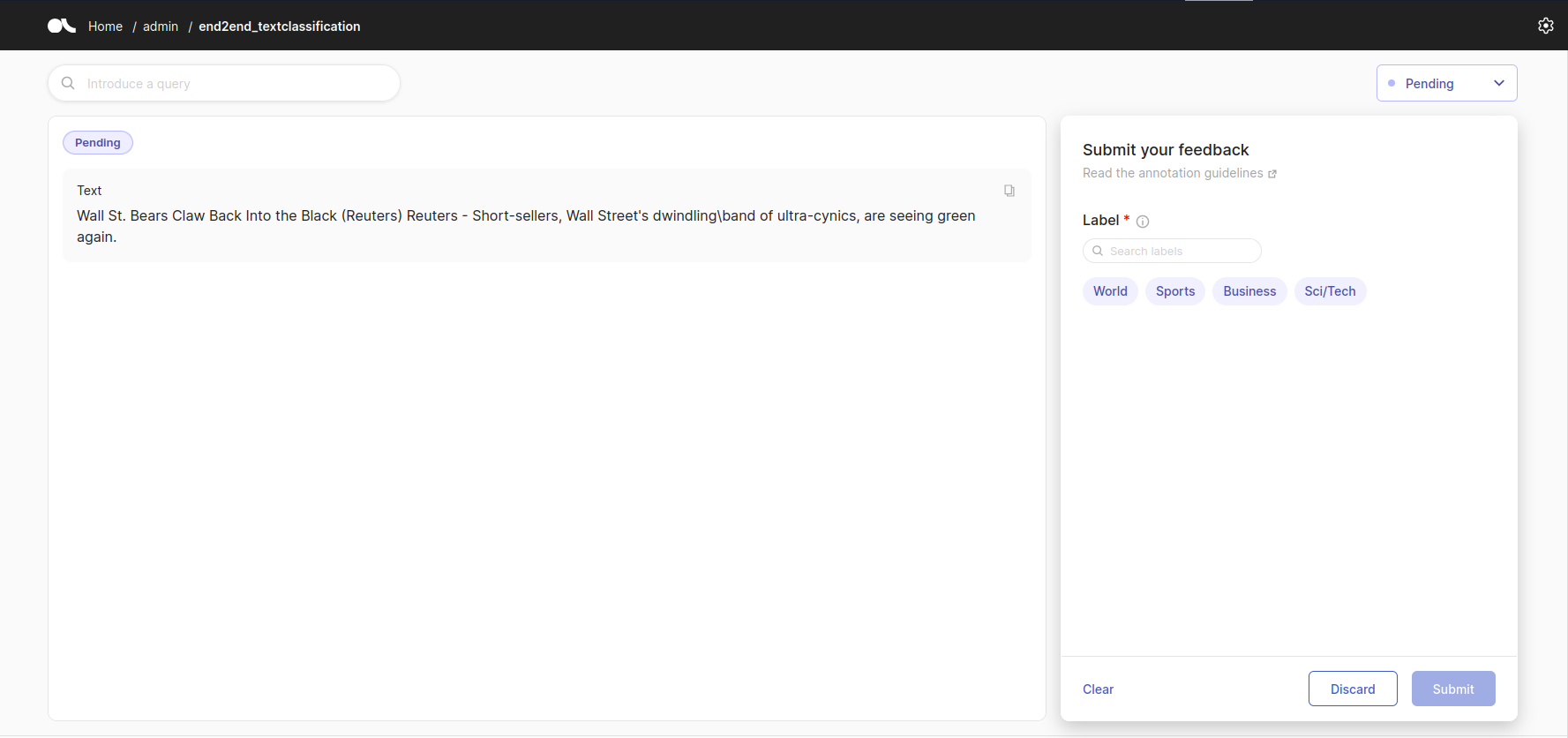
Where we can see the Text from the article we wanted, and the different labels to choose from.
We can now download the dataset from Argilla just to check it:
[15]:
remote_dataset = rg.FeedbackDataset.from_argilla("end2end_textclassification", workspace="argilla")
remote_dataset
[15]:
RemoteFeedbackDataset(
id=52b0dfc2-ed85-4805-923c-5d51b51ec4c9
name=end2end_textclassification
workspace=Workspace(id=ce760ed7-0fdf-4d79-b9b7-1c0e4ea896cd, name=argilla, inserted_at=2023-11-23 09:46:05.591993, updated_at=2023-11-23 09:46:05.591993)
url=http://localhost:6900/dataset/52b0dfc2-ed85-4805-923c-5d51b51ec4c9/annotation-mode
fields=[RemoteTextField(id=UUID('2835bf0e-1259-45b9-a97c-f9b671395563'), client=None, name='text', title='Text', required=True, type='text', use_markdown=False)]
questions=[RemoteLabelQuestion(id=UUID('bb6fc4f0-e4b7-480c-84a1-df717de4ac97'), client=None, name='label', title='Label', description=None, required=True, type='label_selection', labels=['World', 'Sports', 'Business', 'Sci/Tech'], visible_labels=None)]
guidelines=Classify the articles into one of the four categories.
metadata_properties=[]
)
From Hugging Face hub#
If we wanted to share our dataset with the world, we could use the Huggingface hub for it.
First we need to login to huggingface. The following cell will log us with our previous token.
If we don’t have one already, we can obtain it from here (remember to set the write access).
[ ]:
from huggingface_hub import login
login(token=hf_token)
And now we can just call the method on the FeedbackDataset.
[ ]:
#papermill_description=push-dataset-to-huggingface
remote_dataset.push_to_huggingface("argilla/end2end_textclassification")
We can now download the dataset from Hugging Face just to check it:
[ ]:
local_dataset = rg.FeedbackDataset.from_huggingface("argilla/end2end_textclassification")
Conclusion#
In this tutorial we created an Argilla FeedbackDataset for text classification, starting from ag_news.
We created a FeedbackDataset for text classification with a LabelQuestion, from data stored as a datasets.Dataset and a pandas.DataFrame. This dataset was pushed both to Argilla where we can curate and label the records, and finally pushed it to the 🤗hub.
To learn more about how to work with the FeedbackDataset check the cheatsheet. To continue with assigning records to annotators, you can refer to the next tutorial.