⏺️ Add and update records#
Feedback Dataset#
Note
The dataset class covered in this section is the FeedbackDataset. This fully configurable dataset will replace the DatasetForTextClassification, DatasetForTokenClassification, and DatasetForText2Text in Argilla 2.0. Not sure which dataset to use? Check out our section on choosing a dataset.

Define a FeedbackRecord#
After configuring a FeedbackDataset, as shown in the previous guide. The next step is to create records following Argilla’s FeedbackRecord format. You can check an example here. These are the attributes of a FeedbackRecord:
fields: A dictionary with the name (key) and content (value) of each of the fields in the record. These will need to match the fields set up in the dataset configuration (see Define record fields).external_id(optional): An ID of the record defined by the user. If there is no external ID, this will beNone.metadata(optional): A dictionary with the metadata of the record. Read more about including metadata.vectors(optional): A dictionary with the vector associated to the record. Read more about including vectors.suggestions(optional): A list of all suggested responses for a record e.g., model predictions or other helpful hints for the annotators. Read more about including suggestions.responses(optional): A list of all responses to a record. You will only need to add them if your dataset already has some annotated records. Read more about including responses.
# Create a single Feedback Record
record = rg.FeedbackRecord(
fields={
"question": "Why can camels survive long without water?",
"answer": "Camels use the fat in their humps to keep them filled with energy and hydration for long periods."
},
metadata={"source": "encyclopedia"},
vectors={"my_vector": [...], "my_other_vector": [...]},
suggestions = [
{
"question_name": "corrected-answer",
"value": "This is a *suggestion*.",
}
]
responses = [
{
"values":{
"corrected-text":{
"value": "This is a *response*."
}
}
}
]
external_id=None
)
Format metadata#
Record metadata can include any information about the record that is not part of the fields in the form of a dictionary. If you want the metadata to correspond with the metadata properties configured for your dataset so that these can be used for filtering and sorting records, make sure that the key of the dictionary corresponds with the metadata property name. When the key doesn’t correspond, this will be considered extra metadata that will get stored with the record (as long as allow_extra_metadata is set to True for the dataset), but will not be usable for filtering and sorting. As well as adding one metadata property to a single record, you can also add aggregate metadata values for the TermsMetadataProperty in the form of a list.
record = rg.FeedbackRecord(
fields={...},
metadata={"source": "encyclopedia", "text_length":150}
)
record = rg.FeedbackRecord(
fields={...},
metadata={"source": ["encyclopedia", "wikipedia"], "text_length":150}
)
Format vectors#
You can associate vectors, like text embeddings, to your records. This will enable the semantic search in the UI and the Python SDK. These are saved as a dictionary, where the keys correspond to the names of the vector settings that were configured for your dataset and the value is a list of floats. Make sure that the length of the list corresponds to the dimensions set in the vector settings.
Hint
Vectors should have the following format List[float]. If you are using numpy arrays, simply convert them using the method .tolist().
record = rg.FeedbackRecord(
fields={...},
vectors={"my_vector": [...], "my_other_vector": [...]}
)
Format suggestions#
Suggestions refer to suggested responses (e.g. model predictions) that you can add to your records to make the annotation process faster. These can be added during the creation of the record or at a later stage. Only one suggestion can be provided for each question, and suggestion values must be compliant with the pre-defined questions e.g. if we have a RatingQuestion between 1 and 5, the suggestion should have a valid value within that range.
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "relevant",
"value": "YES",
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "content_class",
"value": ["hate", "violent"]
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "preference",
"value":[
{"rank": 1, "value": "reply-2"},
{"rank": 2, "value": "reply-1"},
{"rank": 3, "value": "reply-3"},
],
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "quality",
"value": 5,
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "corrected-text",
"value": "This is a *suggestion*.",
}
]
)
Format responses#
If your dataset includes some annotations, you can add those to the records as you create them. Make sure that the responses adhere to the same format as Argilla’s output and meet the schema requirements for the specific type of question being answered. Also, make sure to include the user_id in case you’re planning to add more than one response for the same question. You can only specify one response with an empty user_id: the first occurrence of user_id=None will be set to the active user_id, while the rest of the responses with user_id=None will be discarded.
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"relevant":{
"value": "YES"
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"content_class":{
"value": ["hate", "violent"]
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"preference":{
"value":[
{"rank": 1, "value": "reply-2"},
{"rank": 2, "value": "reply-1"},
{"rank": 3, "value": "reply-3"},
],
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"quality":{
"value": 5
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"corrected-text":{
"value": "This is a *response*."
}
}
}
]
)
Add records#
We can add records to our FeedbackDataset. Take some time to explore and find data that fits the purpose of your project. If you are planning to use public data, the Datasets page of the Hugging Face Hub is a good place to start.
Tip
If you are working with a public dataset, remember to always check the license to make sure you can legally use it for your specific use case.
from datasets import load_dataset
# Load and inspect a dataset from the Hugging Face Hub
hf_dataset = load_dataset('databricks/databricks-dolly-15k', split='train')
df = hf_dataset.to_pandas()
df
Hint
Take some time to inspect the data before adding it to the dataset in case this triggers changes in the questions or fields.
Once you have a list of configured FeedbackRecords, you can add those to a local or remote FeedbackDataset using the add_records method.
dataset = rg.FeedbackDataset.from_argilla(name="my_dataset", workspace="my_workspace")
records = [
rg.FeedbackRecord(
fields={"question": record["instruction"], "answer": record["response"]}
)
for record in hf_dataset if record["category"]=="open_qa"
]
dataset.add_records(records)
Note
As soon as you add records to a remote dataset, these should be available in the Argila UI. If you cannot see them, try hitting the Refresh button on the sidebar.
Update records#
It is possible to add, update and delete attributes of existing records such as metadata or suggestions by simply modifying the records and saving the changes with the update_records method. To learn more about the format that these should have check the section “Define a FeedbackRecord” above or the corresponding guides or end2end tutorials.
This is an example of how you would do this:
# Load the dataset
dataset = rg.FeedbackDataset.from_argilla(name="my_dataset", workspace="my_workspace")
modified_records = []
# Loop through the records and make modifications
for record in dataset.records:
# e.g. adding/modifying a metadata field and vectors
record.metadata["my_metadata"] = "new_metadata"
record.vectors["my_vector"] = [0.1, 0.2, 0.3]
# e.g. removing all suggestions and responses
record.suggestions = []
record.responses = []
modified_records.append(record)
dataset.update_records(modified_records)
Note
As soon as you update the records in a remote dataset, the changes should be available in the Argila UI. If you cannot see them, try hitting the Refresh button on the sidebar.
Note
Only fields and external_id cannot be added, modified or removed from the records once they have been added to a dataset, as this would compromise the consistency of the dataset.
Delete records#
From v1.14.0, it is possible to delete records from a FeedbackDataset in Argilla. Remember that from 1.14.0, when pulling a FeedbackDataset from Argilla via the from_argilla method, the returned instance is a remote FeedbackDataset, which implies that all the additions, updates, and deletions are directly pushed to Argilla, without having to call push_to_argilla for those to be pushed to Argilla.
The first alternative is to call the delete method over a single FeedbackRecord in the dataset, which will delete that record from Argilla.
# Load the dataset
dataset = rg.FeedbackDataset.from_argilla(name="my_dataset", workspace="my_workspace")
# Delete a specific record
dataset.records[0].delete()
Otherwise, you can also select one or more records from the existing FeedbackDataset (which are FeedbackRecords in Argilla) and call the delete_records method to delete them from Argilla.
# Load the dataset
dataset = rg.FeedbackDataset.from_argilla(name="my_dataset", workspace="my_workspace")
# List the records to be deleted
records_to_delete = list(dataset.records[:5])
# Delete the list of records from the dataset
dataset.delete_records(records_to_delete)
Other datasets#
Note
The records classes covered in this section correspond to three datasets: DatasetForTextClassification, DatasetForTokenClassification, and DatasetForText2Text. These will be deprecated in Argilla 2.0 and replaced by the fully configurable FeedbackDataset class. Not sure which dataset to use? Check out our section on choosing a dataset.
Add records#
The main component of the Argilla data model is called a record. A dataset in Argilla is a collection of these records. Records can be of different types depending on the currently supported tasks:
TextClassificationRecordTokenClassificationRecordText2TextRecord
The most critical attributes of a record that are common to all types are:
text: The input text of the record (Required);annotation: Annotate your record in a task-specific manner (Optional);prediction: Add task-specific model predictions to the record (Optional);metadata: Add some arbitrary metadata to the record (Optional);
Some other cool attributes for a record are:
vectors: Input vectors to enable semantic search.explanation: Token attributions for highlighting text.
In Argilla, records are created programmatically using the client library within a Python script, a Jupyter notebook, or another IDE.
Let’s see how to create and upload a basic record to the Argilla web app (make sure Argilla is already installed on your machine as described in the setup guide).
We support different tasks within the Argilla eco-system focused on NLP: Text Classification, Token Classification and Text2Text.
import argilla as rg
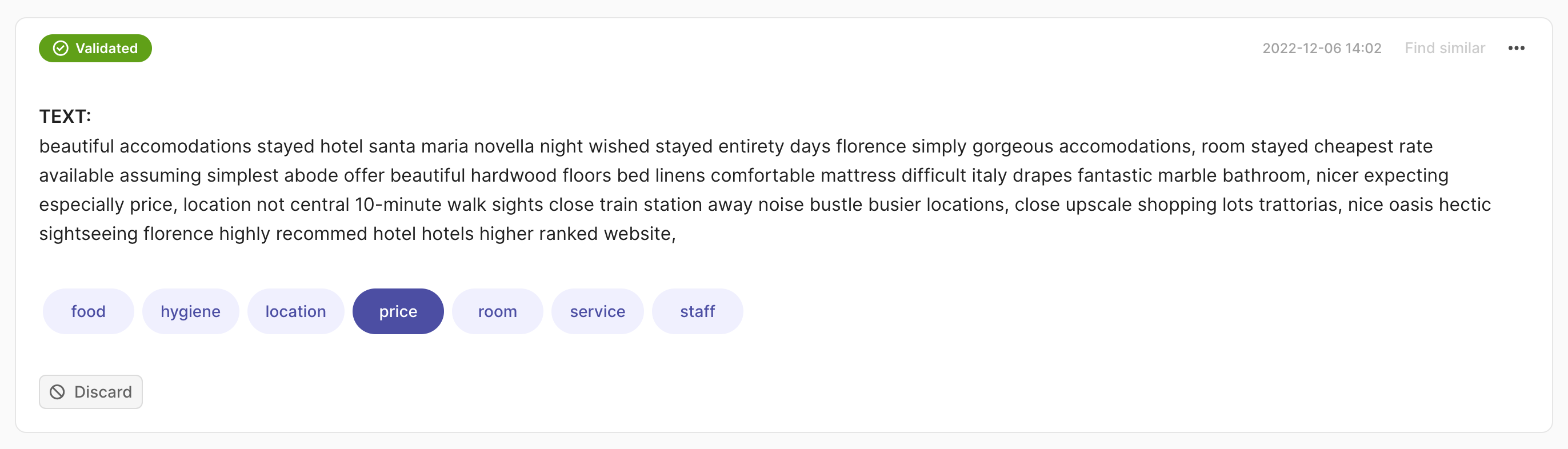
rec = rg.TextClassificationRecord(
text="beautiful accommodations stayed hotel santa... hotels higher ranked website.",
prediction=[("price", 0.75), ("hygiene", 0.25)],
annotation="price"
)
rg.log(records=rec, name="my_dataset")
import argilla as rg
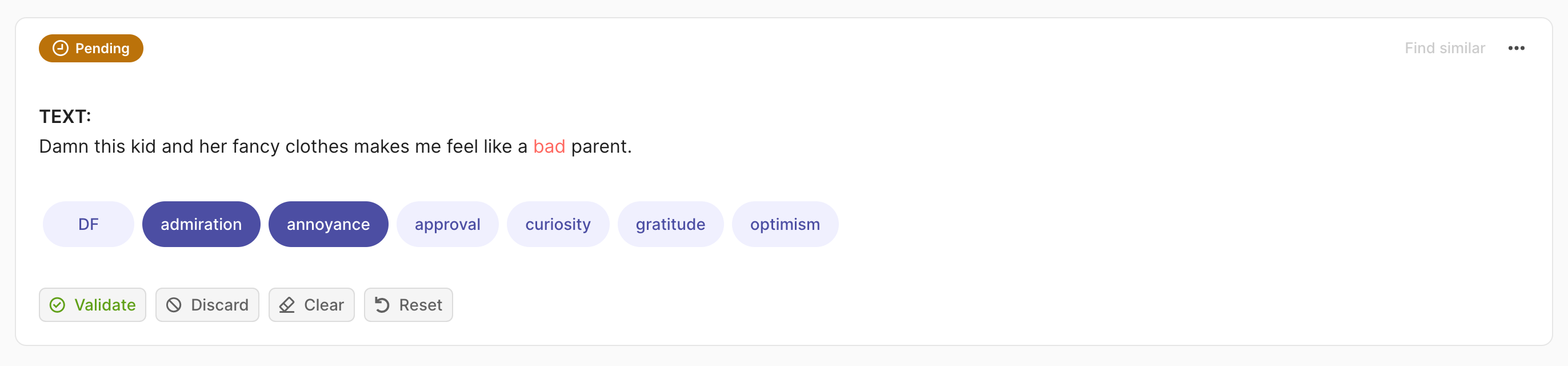
rec = rg.TextClassificationRecord(
text="damn this kid and her fancy clothes make me feel like a bad parent.",
prediction=[("admiration", 0.75), ("annoyance", 0.25)],
annotation=["price", "annoyance"],
multi_label=True
)
rg.log(records=rec, name="my_dataset")
import argilla as rg
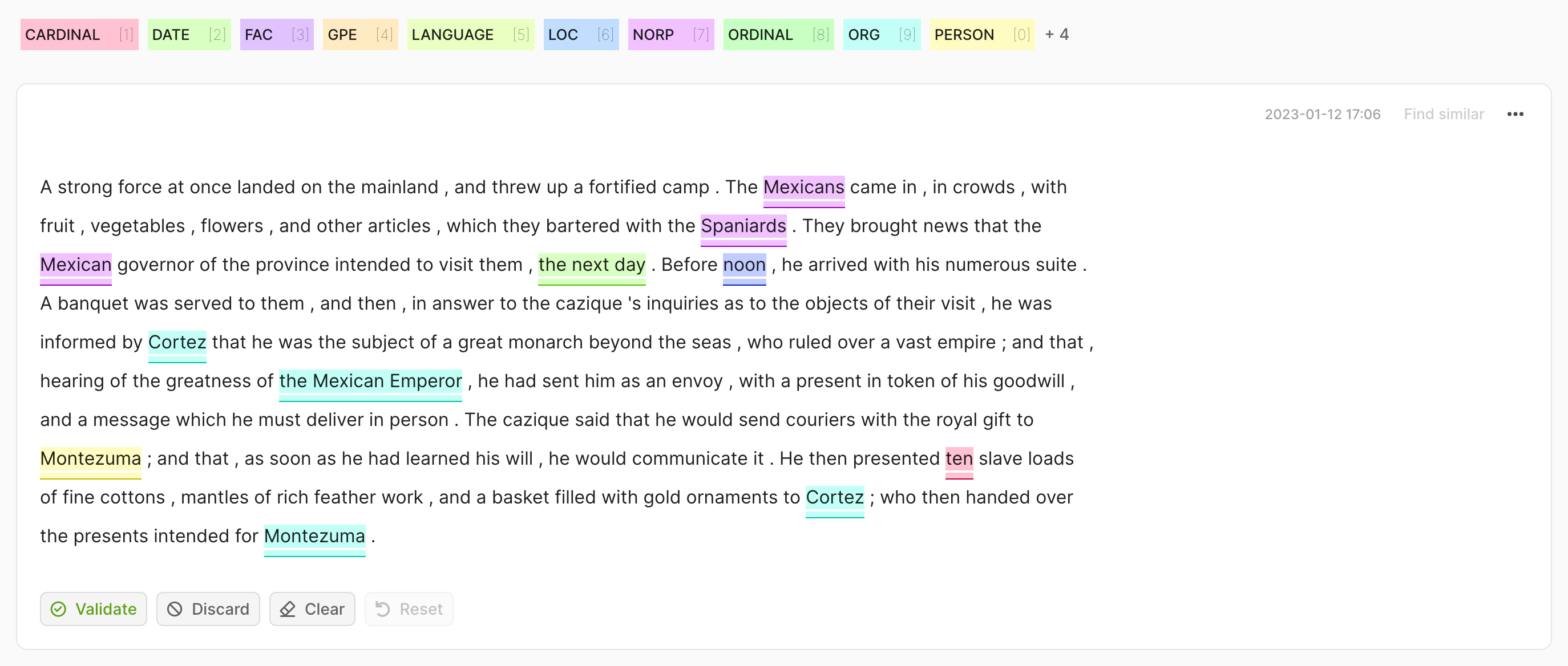
rec = rg.TokenClassificationRecord(
text="Michael is a professor at Harvard",
tokens=["Michael", "is", "a", "professor", "at", "Harvard"],
prediction=[("NAME", 0, 7, 0.75), ("LOC", 26, 33, 0.8)],
annotation=[("NAME", 0, 7), ("LOC", 26, 33)],
)
rg.log(records=rec, name="my_dataset")
import argilla as rg
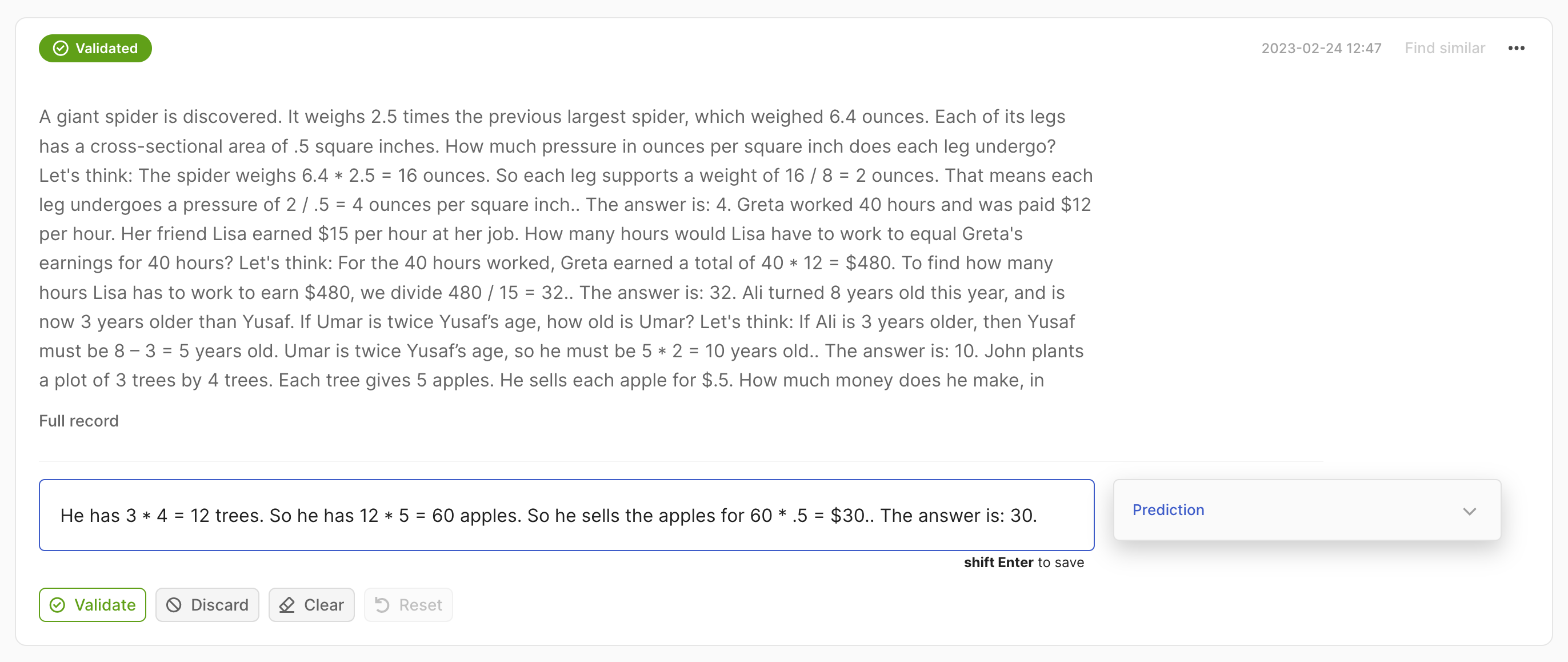
rec = rg.Text2TextRecord(
text="A giant spider is discovered... how much does he make in a year?",
prediction=["He has 3*4 trees. So he has 12*5=60 apples."],
)
rg.log(records=rec, name="my_dataset")
Update records#
It is possible to update records from your Argilla datasets using our Python API. This approach works the same way as an upsert in a normal database, based on the record id. You can update any arbitrary parameters and they will be over-written if you use the id of the original record.
import argilla as rg
# Read all records in the dataset or define a specific search via the `query` parameter
record = rg.load("my_dataset")
# Modify first record metadata (if no previous metadata dict, you might need to create it)
record[0].metadata["my_metadata"] = "I'm a new value"
# Log record to update it, this will keep everything but add my_metadata field and value
rg.log(name="my_dataset", records=record[0])
Delete records#
You can delete records by passing their id into the rg.delete_records() function or using a query that matches the records. Learn more here.
## Delete by id
import argilla as rg
rg.delete_records(name="example-dataset", ids=[1,3,5])
## Discard records by query
import argilla as rg
rg.delete_records(name="example-dataset", query="metadata.code=33", discard_only=True)