🔐 Backup and version Argilla Datasets using DVC#
In this tutorial, we will show you how you can store and version your data using DVC. Alternatively, you can take a look at our Elasticsearch docs about creating retention snapshots directly from your Elasticsearch cluster. It will walk you through the following steps:
⚙️ configure DVC
🧐 determine backup config
🧪 test back-up config
Introduction#
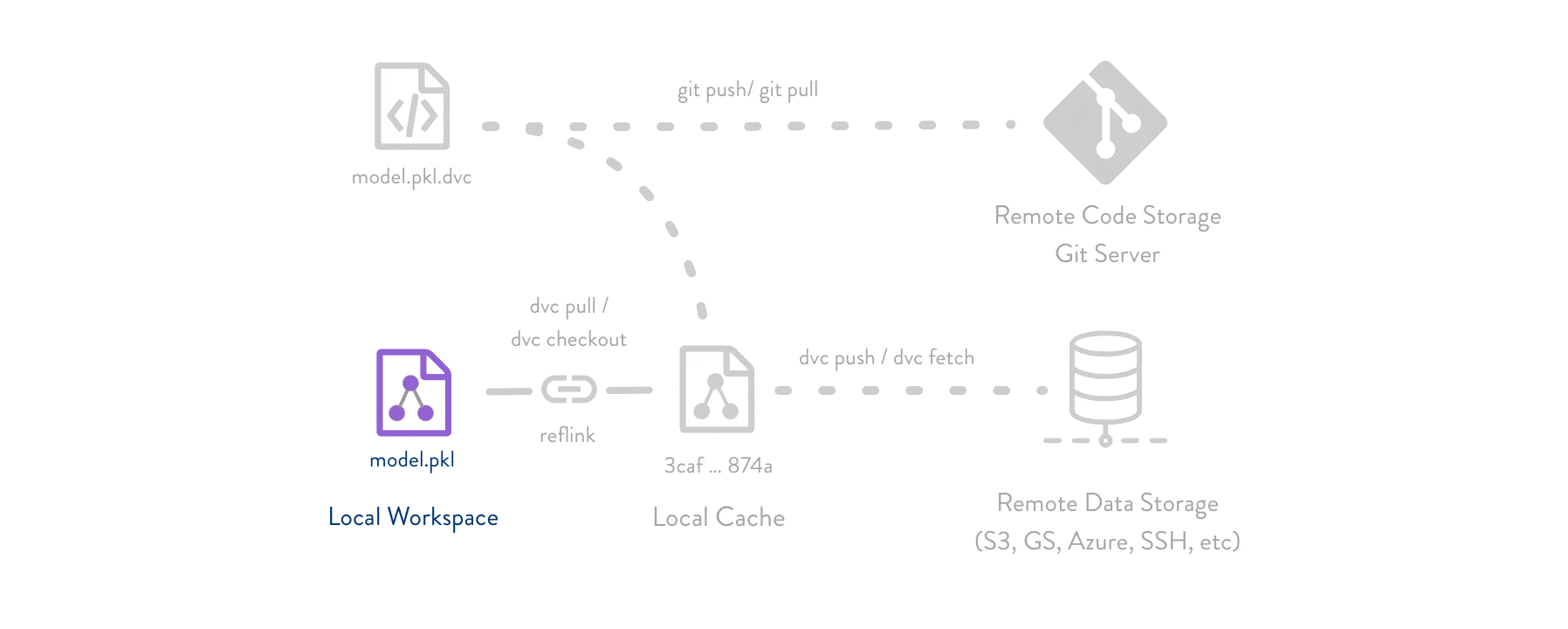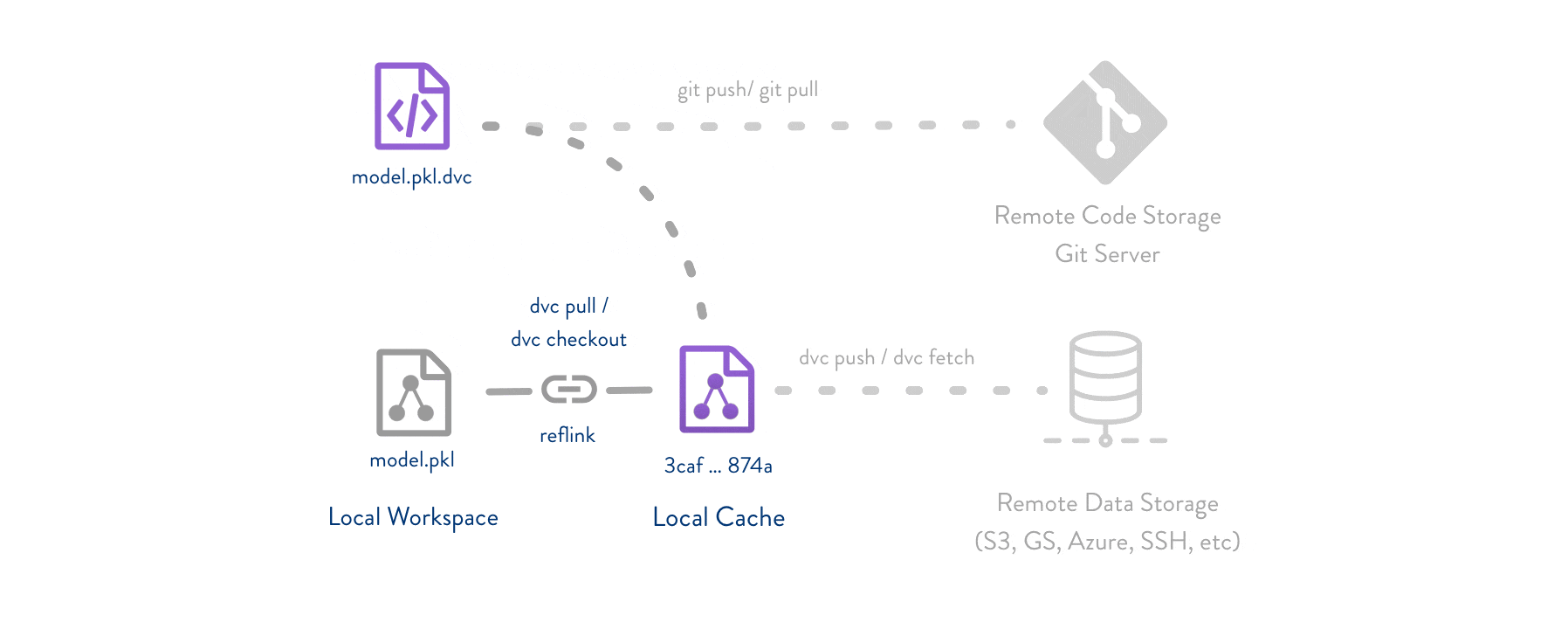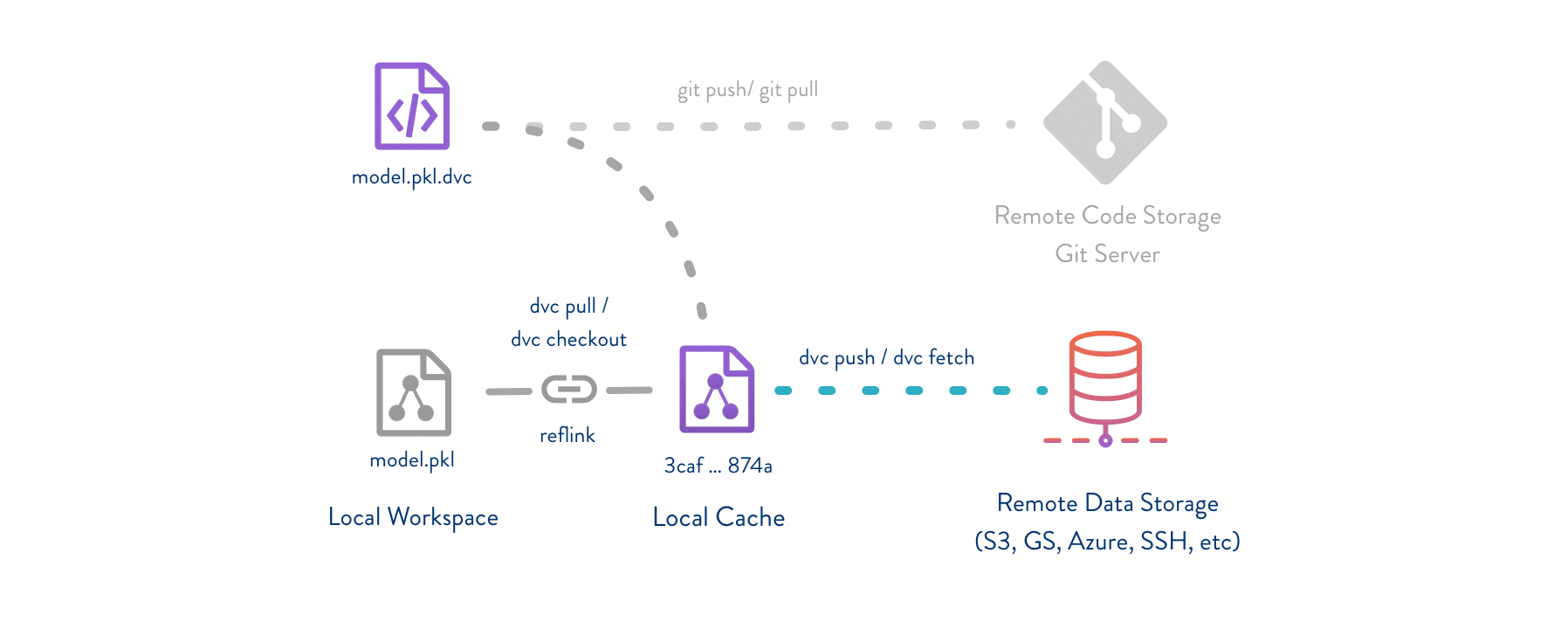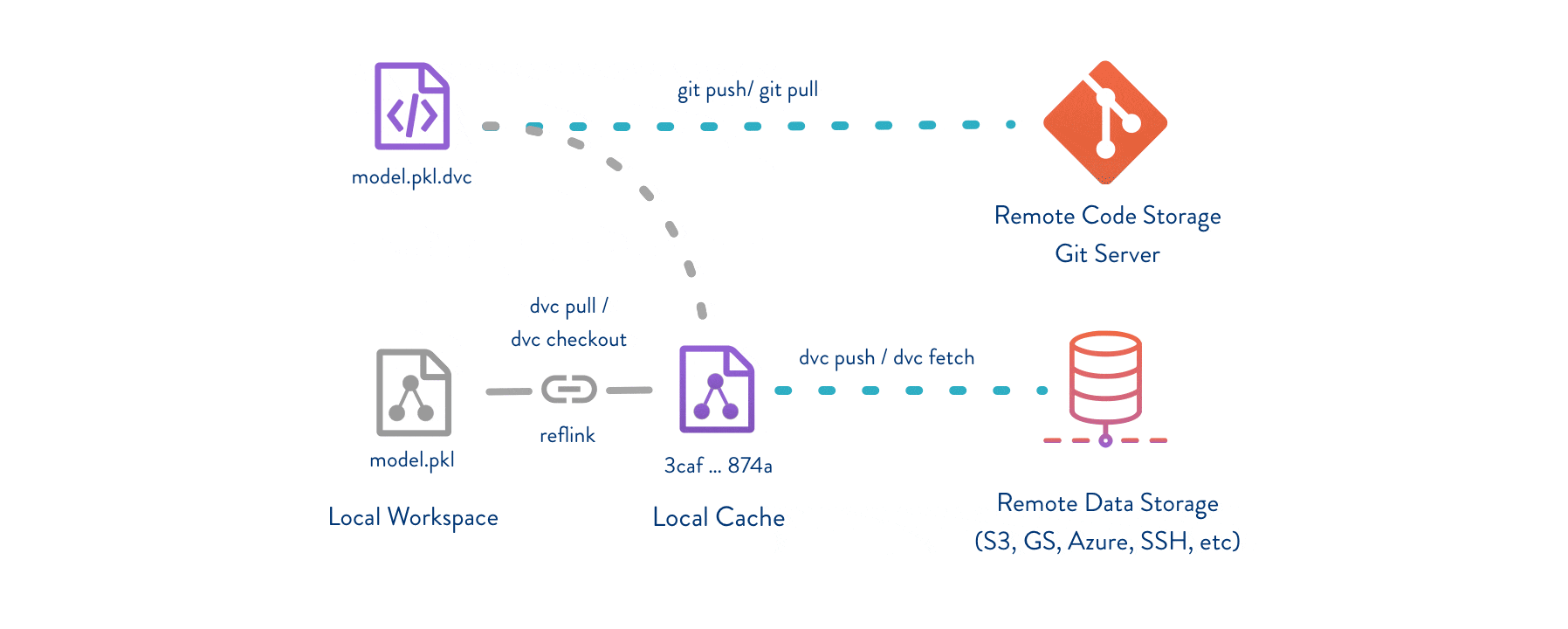
It is important to be able to keep track and store data to version data used in training cycles and to avoid losing data. DVC creates a reference to your data and stores it within an external storage repo. Pushing this reference to get allows us to reproduce certain stages of your repository, while also having a copy of the exact data that was in the repo during that exact time. Think “git for data”.
Take a look at the DVC docs to get a bit more familiar with the idea behind this versioning principle.
Let’s get started!
Running Argilla#
For this tutorial, you will need to have an Argilla server running. There are two main options for deploying and running Argilla:
Deploy Argilla on Hugging Face Spaces: If you want to run tutorials with external notebooks (e.g., Google Colab) and you have an account on Hugging Face, you can deploy Argilla on Spaces with a few clicks:

For details about configuring your deployment, check the official Hugging Face Hub guide.
Launch Argilla using Argilla’s quickstart Docker image: This is the recommended option if you want Argilla running on your local machine. Note that this option will only let you run the tutorial locally and not with an external notebook service.
For more information on deployment options, please check the Deployment section of the documentation.
Tip
This tutorial is a Jupyter Notebook. There are two options to run it:
Use the Open in Colab button at the top of this page. This option allows you to run the notebook directly on Google Colab. Don’t forget to change the runtime type to GPU for faster model training and inference.
Download the .ipynb file by clicking on the View source link at the top of the page. This option allows you to download the notebook and run it on your local machine or on a Jupyter notebook tool of your choice.
Setup packages#
To complete this tutorial, you will need to install the Argilla client and DVC.
[ ]:
%pip install argilla -qqq
[ ]:
!brew install dvc # mac
# !snap install --classic dvc # linux
# !choco install dvc # windows
Let’s import the Argilla module for reading and writing data:
[ ]:
import argilla as rg
If you are running Argilla using the Docker quickstart image or public Hugging Face Spaces, you need to init the Argilla client with the URL and API_KEY:
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
rg.init(
api_url="http://localhost:6900",
api_key="admin.apikey"
)
If you’re running a private Hugging Face Space, you will also need to set the HF_TOKEN as follows:
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# rg.init(
# api_url="https://https://[your-owner-name]-[your_space_name].hf.space",
# api_key="admin.apikey",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
Finally, let’s include the imports we need:
[ ]:
import datetime
import os
import glob
import time
from typing import List
Enable Telemetry#
We gain valuable insights from how you interact with our tutorials. To improve ourselves in offering you the most suitable content, using the following lines of code will help us understand that this tutorial is serving you effectively. Though this is entirely anonymous, you can choose to skip this step if you prefer. For more info, please check out the Telemetry page.
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
Configure .git#
We will use GitHub as a way to track our stored files. This requires us to link our directory to a git remote. We assume that the environment already has set up the correct git credentials and that it is linked to a .git file. This can be tested with git remote -v.
[ ]:
!git remote -v
Configure DVC#
We will first initialize our DVC repo, which will automatically be linked to our git remote.
[8]:
!dvc init
Initialized DVC repository.
You can now commit the changes to git.
+---------------------------------------------------------------------+
| |
| DVC has enabled anonymous aggregate usage analytics. |
| Read the analytics documentation (and how to opt-out) here: |
| <https://dvc.org/doc/user-guide/analytics> |
| |
+---------------------------------------------------------------------+
What's next?
------------
- Check out the documentation: <https://dvc.org/doc>
- Get help and share ideas: <https://dvc.org/chat>
- Star us on GitHub: <https://github.com/iterative/dvc>
Next, we assume that DVC will be used in combination with Google Drive as remote storage. Other options are available but configuring Google Drive is the most straightforward approach. This needs to be configured by adding something similar as shown below, where <your-gdrive-folder-id> is replaced with the Google Drive folder you would like to use for storage. Alternatively, you can go to their configuration page.
[ ]:
!dvc remote add myremote gdrive://<your-gdrive-folder-id>
[ ]:
!dvc remote default myremote
Additionally, we set autostaging for dvc, which also automatically commits them to git.
[13]:
!dvc config core.autostage true
Define Background Process#
After setting up DVC, we can now define a function to collect and store data. This will follow the following steps: - Export data using a naming convention /data/YY-mm-dd_dataset - (optional) create /data_descriptions to add to GitHub - Add the data to DVC, creating a .dvc reference to the /data/* - Commit the .dvc reference to GitHub - push the /data/* to DVC and push the .dvc to GitHub
This kind of versioning allows us to explore data in GitHub by using git checkout first (to switch a branch or checkout a .dvc file version) and then run dvc checkout to sync data.
[22]:
def dataset_backupper(datasets: List[str], duration: int=60*60*24):
while True:
# load datasets and save as .pkl files
for dataset_name in datasets:
ds = rg.load(dataset_name)
df = ds.to_pandas()
df.to_pickle(f"data/{dataset_name}.pkl")
# get all .pkl files using glob
files = glob.glob('data/*.pkl', recursive=True)
[os.system(f'dvc add {file}') for file in files]
# push all .pkl.dvc files to github via git push
os.system("dvc push")
os.system("git commit -m 'update DVC files'")
os.system("git push")
time.sleep(duration)
dataset_backupper(["argilla-dvc"])
Everything is up to date.
[WARNING] Unstaged files detected.
[INFO] Stashing unstaged files to /Users/davidberenstein/.cache/pre-commit/patch1673435632-44248.
check yaml...........................................(no files to check)Skipped
fix end of files.....................................(no files to check)Skipped
trim trailing whitespace.................................................Passed
Insert license header in Python source files.........(no files to check)Skipped
black................................................(no files to check)Skipped
isort................................................(no files to check)Skipped
[INFO] Restored changes from /Users/davidberenstein/.cache/pre-commit/patch1673435632-44248.
[docs/tutorial-on-dvc-usage c86cb402] update DVC files
4 files changed, 10 insertions(+)
create mode 100644 docs/_source/tutorials/notebooks/.dvc/.gitignore
create mode 100644 docs/_source/tutorials/notebooks/.dvc/config
create mode 100644 docs/_source/tutorials/notebooks/.dvcignore
create mode 100644 docs/_source/tutorials/notebooks/data/zingg.pkl.dvc
To https://github.com/argilla-io/argilla.git
2ea0912d..c86cb402 docs/tutorial-on-dvc-usage -> docs/tutorial-on-dvc-usage
This is just a toy example but it is highly configurable depending on your needs. Think about: - only backing up records that are more than X days old - deleting records after backing them up - separating backups per time period - add model versioning into the mix
Be creative and have some fun while doing it 🤓
Retrieve data versions#
Next, we can explore data based on our git commit hashes. git checkout <commit> opens a previous commit, along with the corresponding *.dvc references. Next, we can use dvc pull to fetch and checkout the data files, that were present during the specific <commit>.
Summary#
In this tutorial, we learned a bit about DVC and how this cool package might be used to back-up and version data within the Argilla ecosystem. This can help to preserve data and keep a clean overview of your data and model history.