Hugging Face Spaces#
Argilla nicely integrates with the Hugging Face stack (datasets, transformers, hub, and setfit), and now it can also be deployed using the Hub’s Spaces.
Warning
Hugging Face Spaces now have persistent storage and this is supported from Argilla 1.11.0 onwards, but you will need to manually activate it via the Hugging Face Spaces settings. Otherwise, unless you’re on a paid space upgrade, after 48 hours of inactivity the space will be shut off and you will lose all the data. To avoid losing data, we highly recommend using the persistent storage layer offered by Hugging Face. For more info check the “Setting up persistent storage” section.
In this guide, you’ll learn to deploy your own Argilla app and use it for data labeling workflows right from the Hub.
Your first Argilla Space#
In this section, you’ll learn to deploy an Argilla Space and use it for data annotation and training a sentiment classifier with SetFit, an amazing few-shot learning library.
Deploy Argilla on Spaces#
You can deploy Argilla on Spaces with just a few clicks:

You need to define the Owner (your personal account or an organization), a Space name, and the Visibility (Public or Private, in which case you will need to set a HF_TOKEN). If you plan to use the Space frequently or handle large datasets for data labeling and feedback collection, upgrading the hardware with a more powerful CPU and increased RAM can enhance performance.
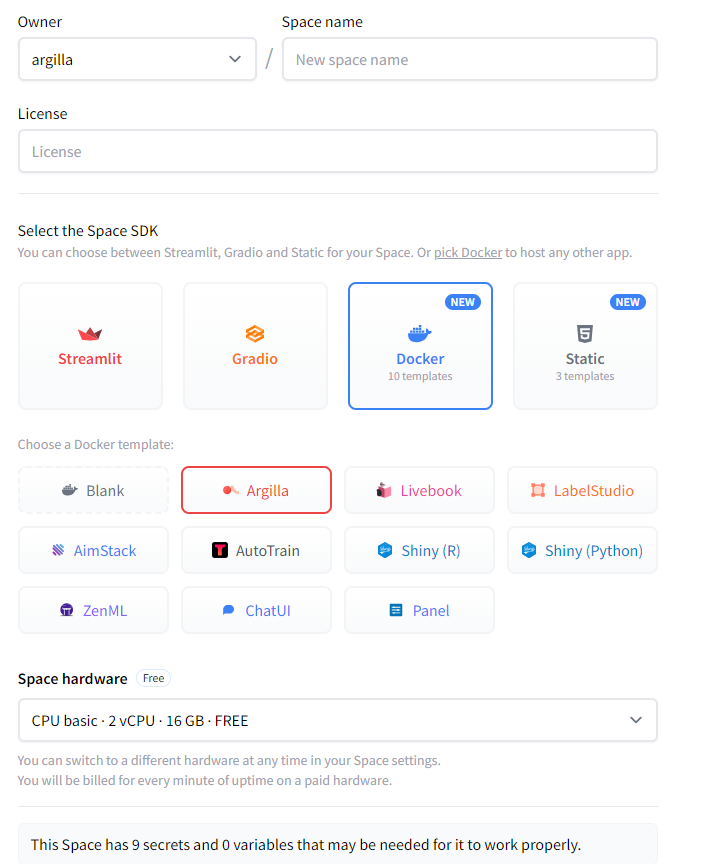
Tip
If you want to customize the title, emojis, and colors of your space, go to “Files and Versions” and edit the metadata of your README.md file.
You’ll see the Building status and once it becomes Running your space is ready to go. If you don’t see the Argilla login UI refresh the page.
Tip
You’ll see the login screen where you need to use either admin or argilla with the default passwords (12345678). Remember you can change the passwords using secret environment variables. If you get a 500 error when introducing the credentials, make sure you have introduced the correct password.
Tip
For quick experimentation, you can jump directly into the next section. If you want to add access restrictions, go to the “Setting up secret environment variables” at the end of this document. In addition, if you prefer to enable persistent storage, go to the following section. Setting up secret variables and persistent storage is recommended for longer-term usage.
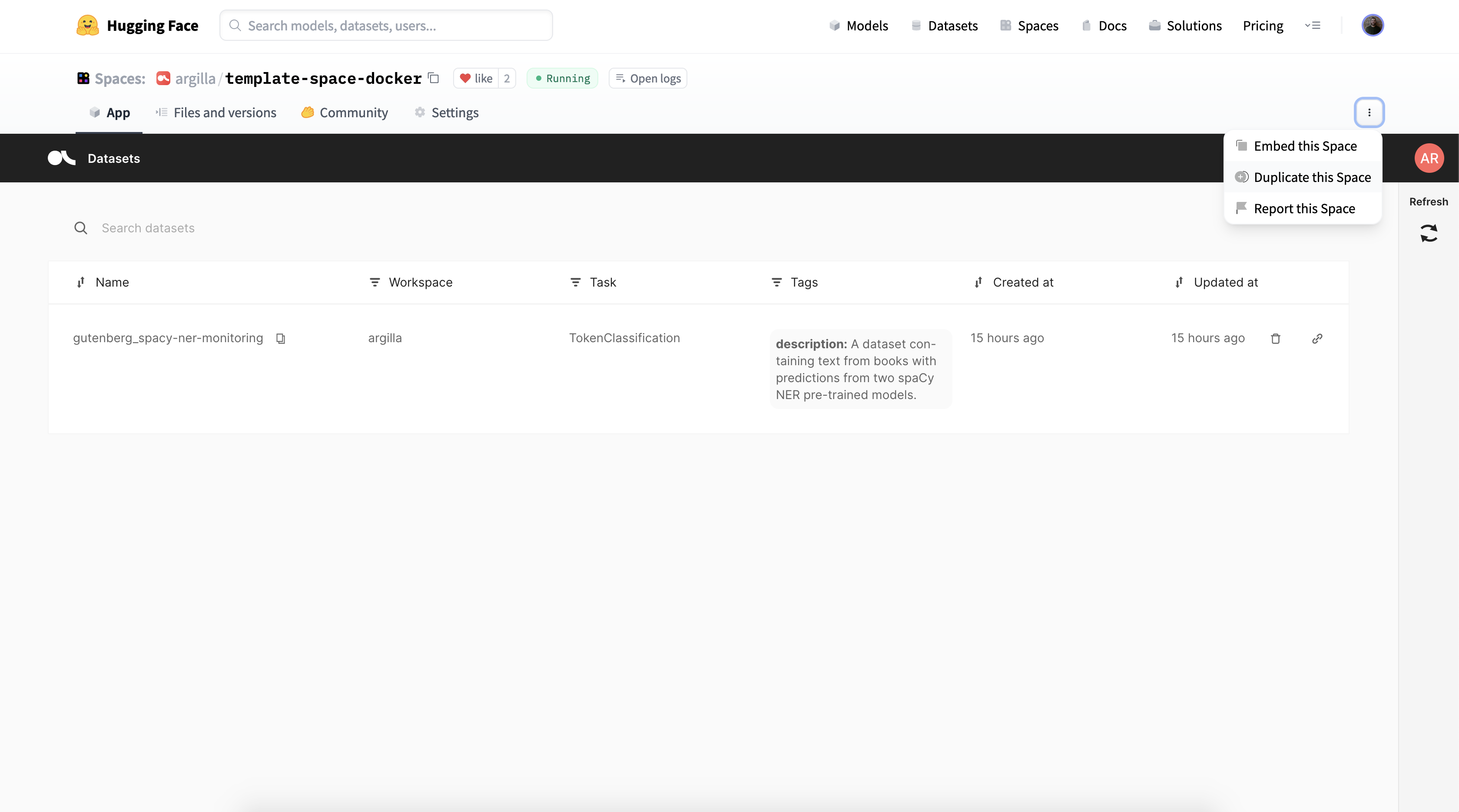
Your Argilla Space URL#
Once Argilla is running, you can use the UI with the Direct URL. This URL gives you access to a full-screen, stable Argilla instance, and is the api_url for reading and writing datasets using the Argilla Python library.
If you have a public space, you’ll find the Direct URL in the “Embed this Space” option (top right). You’ll see a URL like this:
https://dvilasuero-argilla-setfit.hf.space
If you are using a private space, the Direct URL should be constructed as follows:
https://[your-owner-name]-[your_space_name].hf.space. For instance, if the owner of the space isdvilasueroand your space name isargilla-setfit, your Direct URL will behttps://dvilasuero-argilla-setfit.hf.space.
Create your first dataset#
If everything goes well, you are ready to use the Argilla Python client from an IDE such as Colab, Jupyter, or VS Code.
If you want a quick step-by-step example, keep reading. If you want an end-to-end tutorial, go to this tutorial and use Colab or Jupyter.
First, we need to pip install datasets and argilla on Colab or your local machine:
pip install datasets argilla
Then, you can read the example dataset using the datasets library. This dataset is a CSV file uploaded to the Hub using the drag-and-drop feature.
from datasets import load_dataset
dataset = load_dataset("dvilasuero/banking_app", split="train").shuffle()
You can create your first dataset by logging it into Argilla using your endpoint URL:
import argilla as rg
# if you connect to your public app endpoint (uses default API key)
rg.init(api_url="[your_space_url]", api_key="admin.apikey")
# if you connect to your private app endpoint (uses default API key)
rg.init(api_url="[your_space_url]", api_key="admin.apikey", extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"})
# transform dataset into Argilla's format and log it
rg.log(rg.read_datasets(dataset, task="TextClassification"), name="bankingapp_sentiment")
Congrats! You now have a dataset available from the Argilla UI to start browsing and labeling. In the code above, we’ve used one of the many integrations with Hugging Face libraries, which let you read hundreds of datasets available on the Hub.
Data labeling and model training#
At this point, you can label your data directly using your Argilla Space and read the training data to train your model of choice.
# this will read our current dataset and turn it into a clean dataset for training
dataset = rg.load("bankingapp_sentiment").prepare_for_training()
You can also get the full dataset and push it to the Hub for reproducibility and versioning:
# save full argilla dataset for reproducibility
rg.load("bankingapp_sentiment").to_datasets().push_to_hub("bankingapp_sentiment")
Finally, this is how you can train a SetFit model using data from your Argilla Space:
from sentence_transformers.losses import CosineSimilarityLoss
from setfit import SetFitModel, SetFitTrainer
# Create train test split
dataset = dataset.train_test_split()
# Load SetFit model from Hub
model = SetFitModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
# Create trainer
trainer = SetFitTrainer(
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
loss_class=CosineSimilarityLoss,
batch_size=8,
num_iterations=20,
)
# Train and evaluate
trainer.train()
metrics = trainer.evaluate()
As a next step, you can check the Argilla Tutorials section. All the tutorials can be run using Colab or local Jupyter Notebooks, so you can start building datasets with Argilla and Spaces!
Feedback and support#
If you have improvement suggestions or need specific support, please join Argilla Slack community or reach out on Argilla’s GitHub repository.
Setting up persistent storage#
Hugging Face Spaces recently introduced a feature for persistent storage, which must be enabled manually through the Hugging Face Spaces settings. Without this activation, and if you’re not subscribed to a paid space upgrade, the space will automatically shut down after 48 hours of inactivity, resulting in data loss. To prevent this, we highly recommend using the persistent storage layer offered by Hugging Face.
To enable persistent storage, go to the “Settings” tab on your created Space and click on the desired plan on the “Persistent Storage” section. This will enable persistent storage for your Space and you will be able to use it for data labeling and feedback collection.

Setting up secret environment variables#
The Space template provides a way to set up different optional settings focusing on securing your Argilla Space.
To set up these secrets, you can go to the Settings tab on your created Space. Make sure to save these values somewhere for later use.
The template space has three users: owner, admin and argilla. The username owner corresponds to the root user, who can create users, workspaces, and upload datasets within your Argilla Space. The username admin can upload datasets in their workspace/s. And, the username argilla is an annotator user with access to the argilla workspace and to the datasets uploaded there.
The usernames, passwords, and API keys to upload, read, update, and delete datasets can be configured using the following secrets:
OWNER_USERNAME: The owner username to log in Argilla. The default owner username isowner. By setting up a custom username you can use your own username to log in to the app.OWNER_PASSWORD: This sets a custom password to log in to the app with theownerusername. The default password is12345678. By setting up a custom password you can use your own password to log in to the app.OWNER_API_KEY: Argilla provides a Python library to interact with the app (read, write, and update data, log model predictions, etc.). If you don’t set this variable, the library and your app will use the default API key i.e.owner.apikey. If you want to secure your app for reading and writing data, we recommend you to set up this variable. The API key you choose can be any string of your choice and you can check an online generator if you like.ADMIN_USERNAME: The admin username to log in Argilla. The default admin username isadmin. By setting up a custom username you can use your own username to log in to the app.ADMIN_PASSWORD: This sets a custom password to log in to the app with theadminusername. The default password is12345678. By setting up a custom password you can use your own password to log in to the app.ADMIN_API_KEY: Argilla provides a Python library to interact with the app (read, write, and update data, log model predictions, etc.). If you don’t set this variable, the library and your app will use the default API key i.e.admin.apikey. If you want to secure your app for reading and writing data, we recommend you to set up this variable. The API key you choose can be any string of your choice and you can check an online generator if you like.ANNOTATOR_USERNAME: The annotator username to log in Argilla. The default annotator username isargilla. By setting up a custom username you can use your own username to log in to the app.ANNOTATOR_PASSWORD: This sets a custom password to log in to the app with theargillausername. The default password is12345678. By setting up a custom password you can use your own password to log in to the app.
The combination of these secret variables gives you the following setup options:
I want to avoid that anyone without the API keys adds, deletes, or updates datasets using the Python client: You need to set up
ADMIN_PASSWORDandADMIN_API_KEY.Additionally, I want to avoid that the
argillausername deletes datasets from the UI: You need to set upANNOTATOR_PASSWORDand use theargillagenerated API key with the Python Client (check your Space logs). This option might be interesting if you want to control dataset management but want anyone to browse your datasets using theargillauser.Additionally, I want to avoid that anyone without password browses my datasets with the
argillauser: You need to set upANNOTATOR_PASSWORD. In this case, you can use theargillagenerated API key and/orADMIN_API_KEYvalues with the Python Client depending on your needs for dataset deletion rights.
Additionally, the LOAD_DATASETS will let you configure the sample datasets that will be pre-loaded. The default value is single and the supported values for this variable are:
1. single: Load single datasets for TextClassification task.
2. full: Load all the sample datasets for NLP tasks (TokenClassification, TextClassification, Text2Text)
3. none: No datasets being loaded.
Setting up HF Authentication#
From version 1.23.0 you can enable Hugging Face authentication for your Argilla Space. This feature allows you to give access to your Argilla Space to users that are logged in to the Hugging Face Hub.
Note
This feature is specially useful for public crowdsourcing projects. If you would like to have more control over who can log in to the Space, you can set this up on a private space so that only members of your Organization can sign in. Alternatively, you may want to create users and use their credentials instead.
To enable this feature, you will first need to create an OAuth App in Hugging Face. To do that, go to your user settings in Hugging Face and select Connected Apps > Create App. Once inside, choose a name for your app and complete the form with the following information:
Homepage URL: Your Argilla Space Direct URL.
Logo URL:
[Your Argilla Space Direct URL]/favicon.icoScopes:
openidandprofile.Redirect URL:
[Your Argilla Space Direct URL]/oauth/huggingface/callback
This will create a Client ID and an App Secret that you will need to add as variables of your Space. To do this, go to the Space Settings > Variables and Secrets and save the Client ID and App Secret as environment secrets like so:
Name:
OAUTH2_HUGGINGFACE_CLIENT_ID- Value: [Your Client ID]Name:
OAUTH2_HUGGINGFACE_CLIENT_SECRET- Value: [Your App Secret]
Alternatively, you can provide the environment variables in the .oauth.yaml file like so:
# This attribute will enable or disable the Hugging Face authentication
enabled: true
providers:
# The OAuth provider setup
# For now, only Hugging Face is supported
- name: huggingface
# This is the client ID of the OAuth app. You can find it in your Hugging Face settings.
# see https://huggingface.co/docs/hub/oauth#creating-an-oauth-app for more info.
# You can also provide it by using the env variable `OAUTH2_HUGGINGFACE_CLIENT_ID`
client_id: XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXXX
# This is the client secret of the OAuth app. You can find it in your Hugging Face settings.
# See https://huggingface.co/docs/hub/oauth#creating-an-oauth-app for more info.
# We encourage you to provide it by using the env variable `OAUTH2_HUGGINGFACE_CLIENT_SECRET`
client_secret: XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXXX
# The scope of the OAuth app. At least `openid` and `profile` are required.
scope: openid profile
# This section defines the allowed workspaces for the oauth users.
# Workspaces defined here must exist in Argilla.
allowed_workspaces:
- name: admin
Warning
Be aware that the .oauth.yaml file is public in the case of public spaces or may be accesible by other members of your organization if it is a private space.
Therefore, we recommend setting these variables as enviroment secrets.
Now check that the enabled parameter is set to true in your .oauth.yaml file and go back to the Settings to do a Factory rebuild. Once the Space is restarted, you and your collaborators can sign and log in to your Space using their Hugging Face accounts.