Features#
Annotate records#
Note
For information about features in the new Feedback Task datasets, please check this guide.
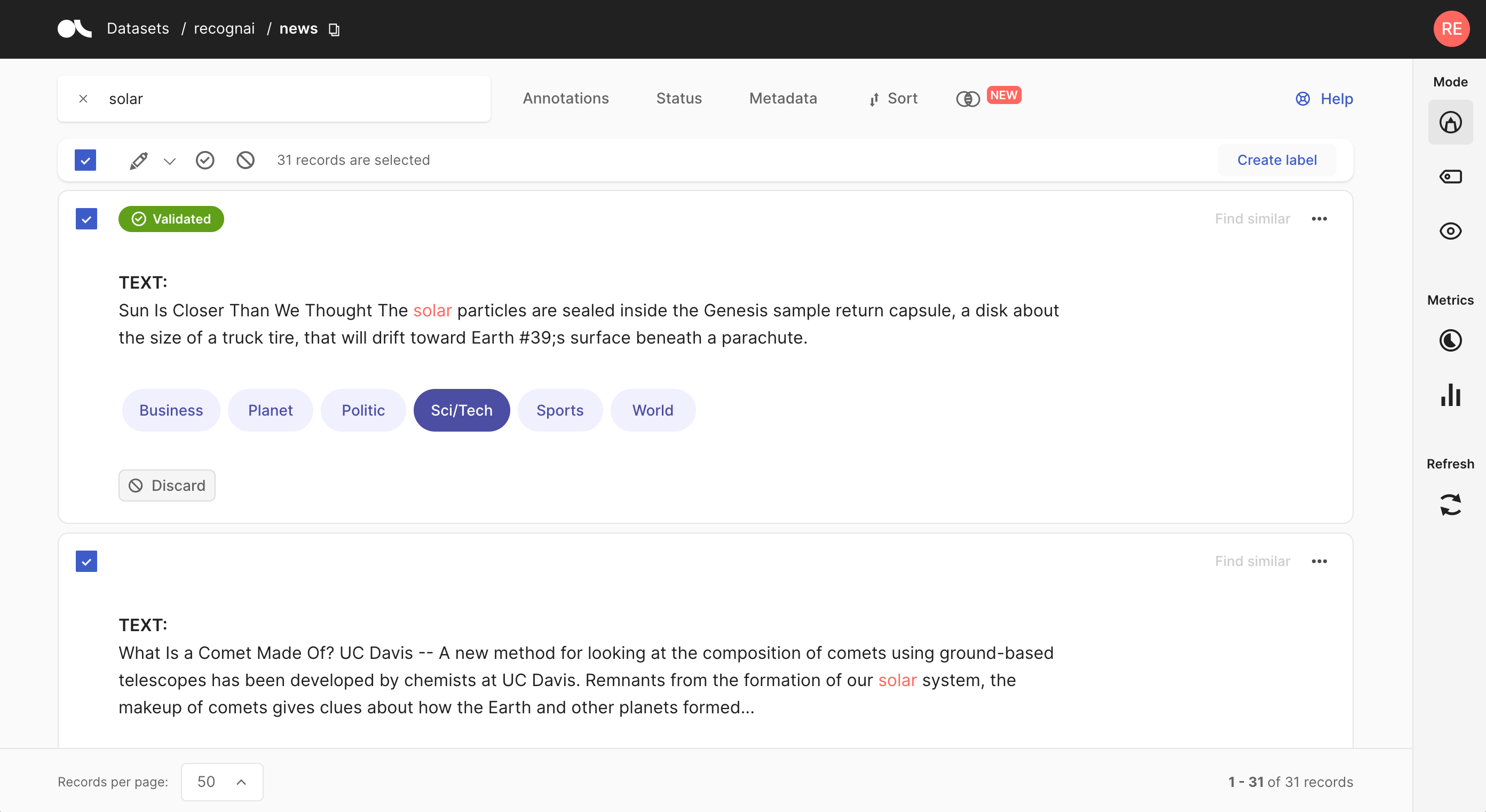
The Argilla UI has a dedicated mode to quickly label your data in a very intuitive way, or revise previous gold labels and correct them. Argilla’s powerful search and filter functionalities, together with potential model predictions, can guide the annotation process and support the annotator.
The Annotate mode is the default mode of the Dataset page.
Create labels#
For the text and token classification tasks, you can create new labels within the Annotate mode. On the right side of the bulk validation bar, you will find a “+ Create new label” button that lets you add new labels to your dataset.
Annotate#
The Argilla UI provides a simple and intuitive interface for annotating records. Each task offers a variety of small features and interactions to optimize annotations.
Text Classification#
Single label#
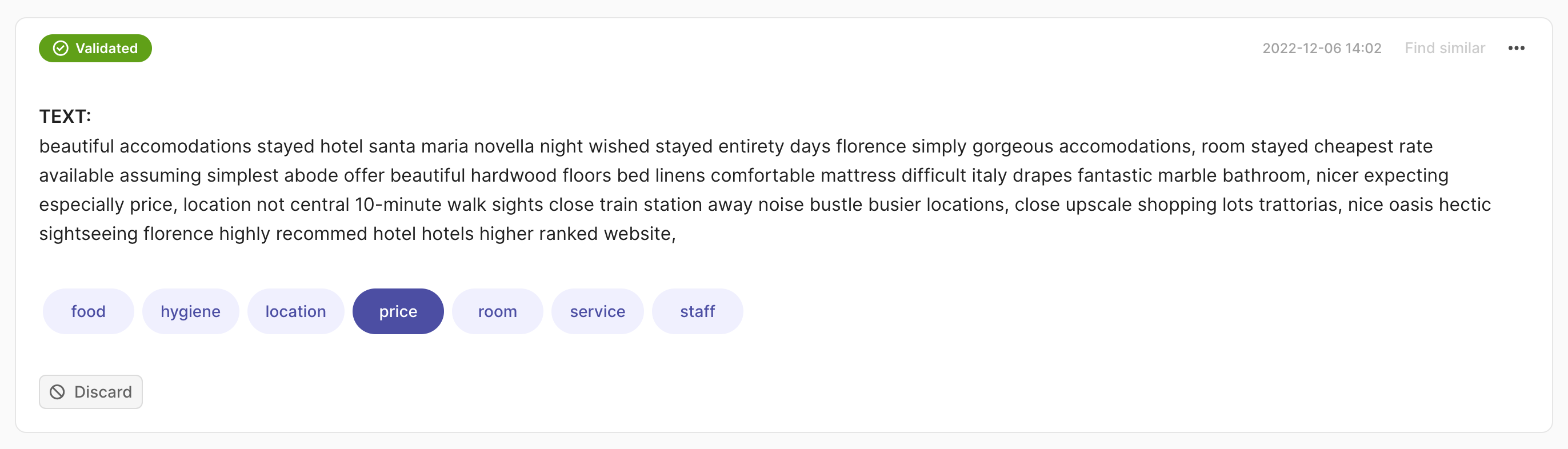 You can annotate the records with one click on the label. The record will be validated automatically.
You can annotate the records with one click on the label. The record will be validated automatically.
Multi-label#
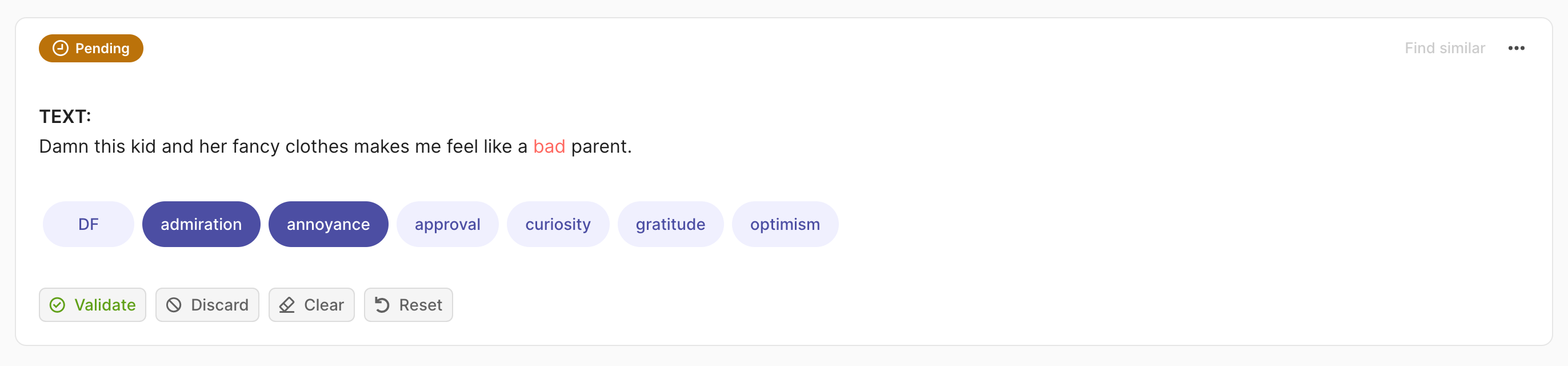 To annotate a record, click on one or multiple labels. Once a record is annotated, its status will show as Pending. Click Reset if you want to discard your changes and recover the previous state of the record or Validate to save your annotation into the dataset. The status will then change to Validated in the upper left corner of the record card.
To annotate a record, click on one or multiple labels. Once a record is annotated, its status will show as Pending. Click Reset if you want to discard your changes and recover the previous state of the record or Validate to save your annotation into the dataset. The status will then change to Validated in the upper left corner of the record card.
You can also remove all annotations using the Clear button or discard a record from the dataset by clicking Discard.
Note
When the dataset contains a large list of labels (10 +), we encourage viewing the record cards one by one (select 1 record per page from the footer) and using the arrow keys to move quickly between records.
Token Classification#
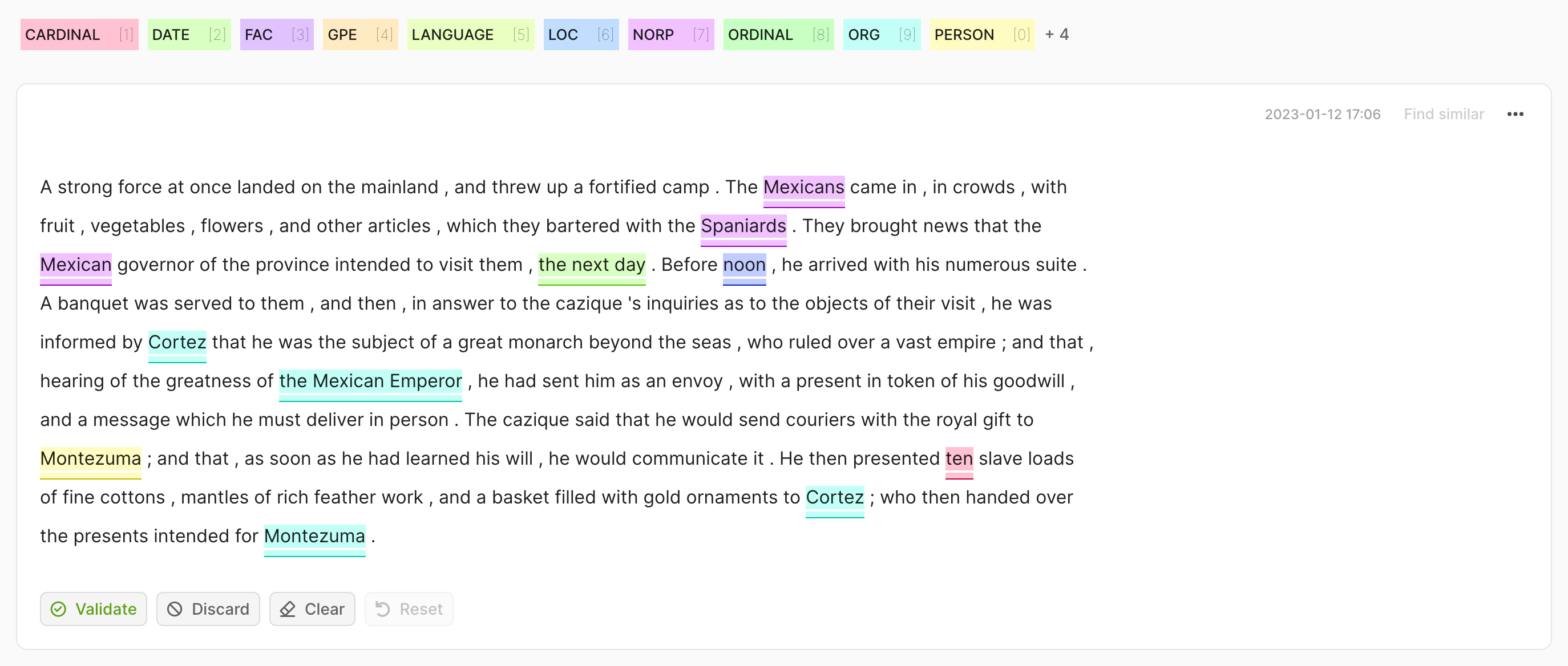
For token classification datasets, you can highlight words (tokens) in the text and annotate them with a label.
Under the hood, the highlighting takes advantage of the tokens information in the Token Classification data model.
To remove specific labels, hover over the highlights and press the X button or double-click directly on the colored area. You can also click the Clear button to remove all annotations in the record.
After modifying a record, either by adding or removing annotations, its status will change to Pending. When you have finished your annotation of the whole record, click Validate to save the changes. The status will change to Validated in the upper left corner of the record card. Alternatively, you can use the Reset button to discard your changes and recover the previous state of the record.
If you want to discard the record from the dataset, click Discard.
Text2Text#
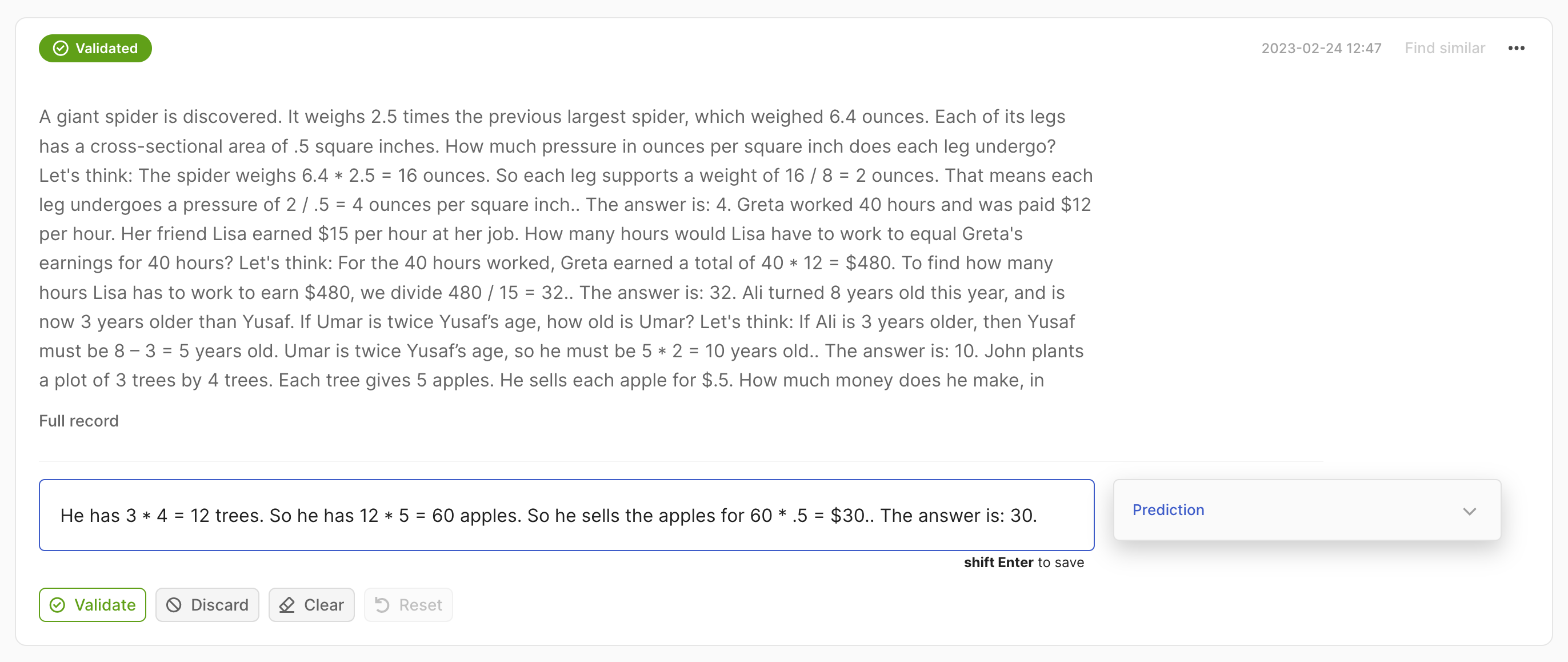 For Text2Text datasets, there is a text box available for drafting or editing annotations. If a record has one or more predictions, the prediction with the highest score will be pre-filled. You can empty the text field by clicking the Clear button.
For Text2Text datasets, there is a text box available for drafting or editing annotations. If a record has one or more predictions, the prediction with the highest score will be pre-filled. You can empty the text field by clicking the Clear button.
Remember to validate to save your changes after editing or drafting your annotation. Alternatively, you can discard your changes and revert to the previous state of the record using the Reset button.
After validating your annotation, predictions can still be accessed in the prediction panel on the right side of the record card.
If you want to discard the record from the dataset, click Discard.
Bulk annotate#
For all tasks, you can use bulk actions. You can either select the records one by one with the selection box on the upper left of each card, or you can use the global selection box below the search bar, which will select all records shown on the page. Then you can Validate and Discard the selected records using the icons next to the global selection box. For the multi-label text classification and token classification tasks you can also Clear and Reset at bulk level.

For the text classification task, you can additionally bulk annotate the selected records by simply clicking on the pencil icon next to the global selection box and selecting the label(s) from the list.
In multi-label text classification, you can remove labels from selected records by clicking the cross next to the label. You can also assign a partially used label to the whole selection by clicking on the tag button. Once you have made your selection, click Select to apply the annotations to all selected records. To finalize the validation, click on the “validate” icon.
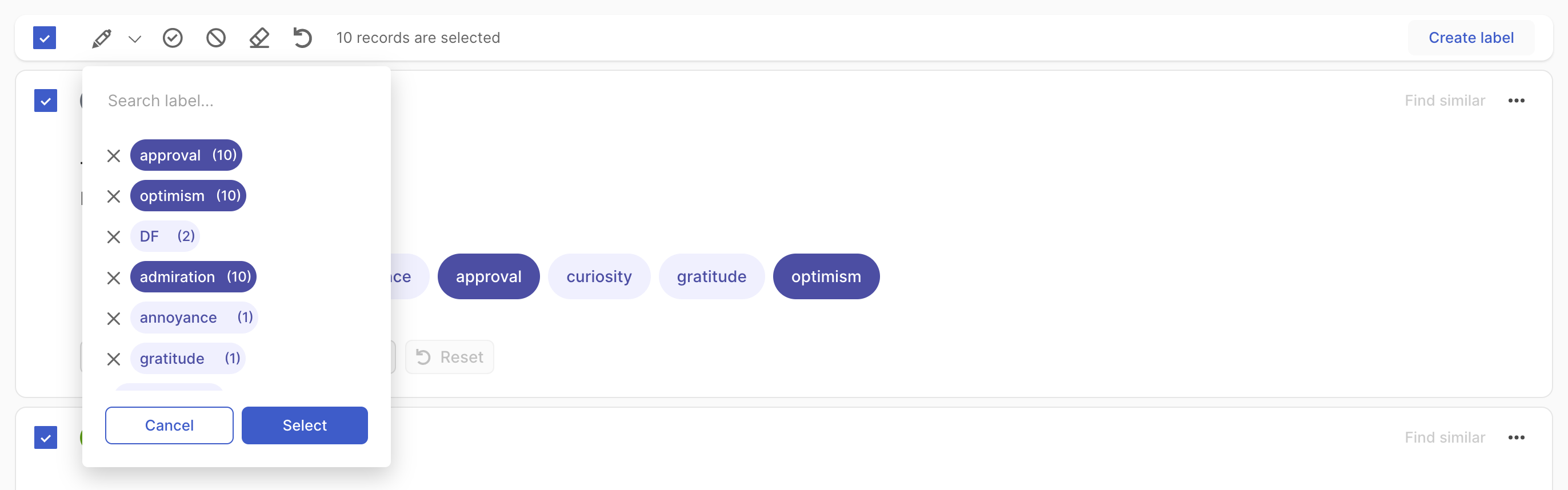
In single-label text classification, there is no need to validate after selecting your label.
Validate predictions#
In Argilla, you can pre-annotate your data by including model predictions in your records. Assuming that the model works reasonably well on your dataset, you can filter for records with high prediction scores, and simply validate their predictions to quickly annotate records.
Note
If you make any changes to predictions, validate annotations or annotate from scratch, you will need to validate the records to save the changes.
Text Classification#
For this task, model predictions are shown as percentages in the label tags. You can validate the predictions shown in a slightly darker tone by pressing the Validate button:
for a single label classification task, this will be the prediction with the highest percentage
for a multi-label classification task, this will be the predictions with a percentage above 50%
If you select a different label in the single label task, the status will change to Validated automatically. In the multi-label task, if you make any changes or clear the predictions/annotations, the status will change to Pending. You can then click Validate to save the changes or Reset to revert them and restore the previous status.
Token Classification#
For this task, predictions are shown as underlines. You can also validate the predictions (or the absence of them) by pressing the Validate button.
If you make any changes or clear the predictions/annotations, the status will change to Pending. You can then click Validate to save the changes or Reset to revert them and restore the previous status.
Text2Text#
The prediction and its score will appear in a text box below the main text. You can validate the prediction by clicking on the Validate button or edit the text making the changes directly in the text box.
If you make any changes, the status will change to Pending and you will need to press shift+Enter or click the Validate button to save the changes. You can also click the Clear button to start writing from scratch or Reset to undo your changes and restore the previous status.
Search and filter#
The powerful search bar allows you to do simple, quick searches, as well as complex queries that take full advantage of Argilla’s data models. In addition, the filters provide you with a quick and intuitive way to filter and sort your records with respect to various parameters, including the metadata of your records. For example, you can use the Status filter to hide already annotated records (Status: Default), or to only show annotated records when revising previous annotations (Status: Validated).
You can find more information about how to use the search bar and the filters in our detailed search guide and filter guide.
Note
Not all filters are available for all tasks.
Progress metric#
From the sidebar you can access the Progress metrics. There you will find the progress of your annotation session, the distribution of validated and discarded records, and the label distribution of your annotations.
You can find more information about the metrics in our dedicated metrics guide.
Weak labeling#
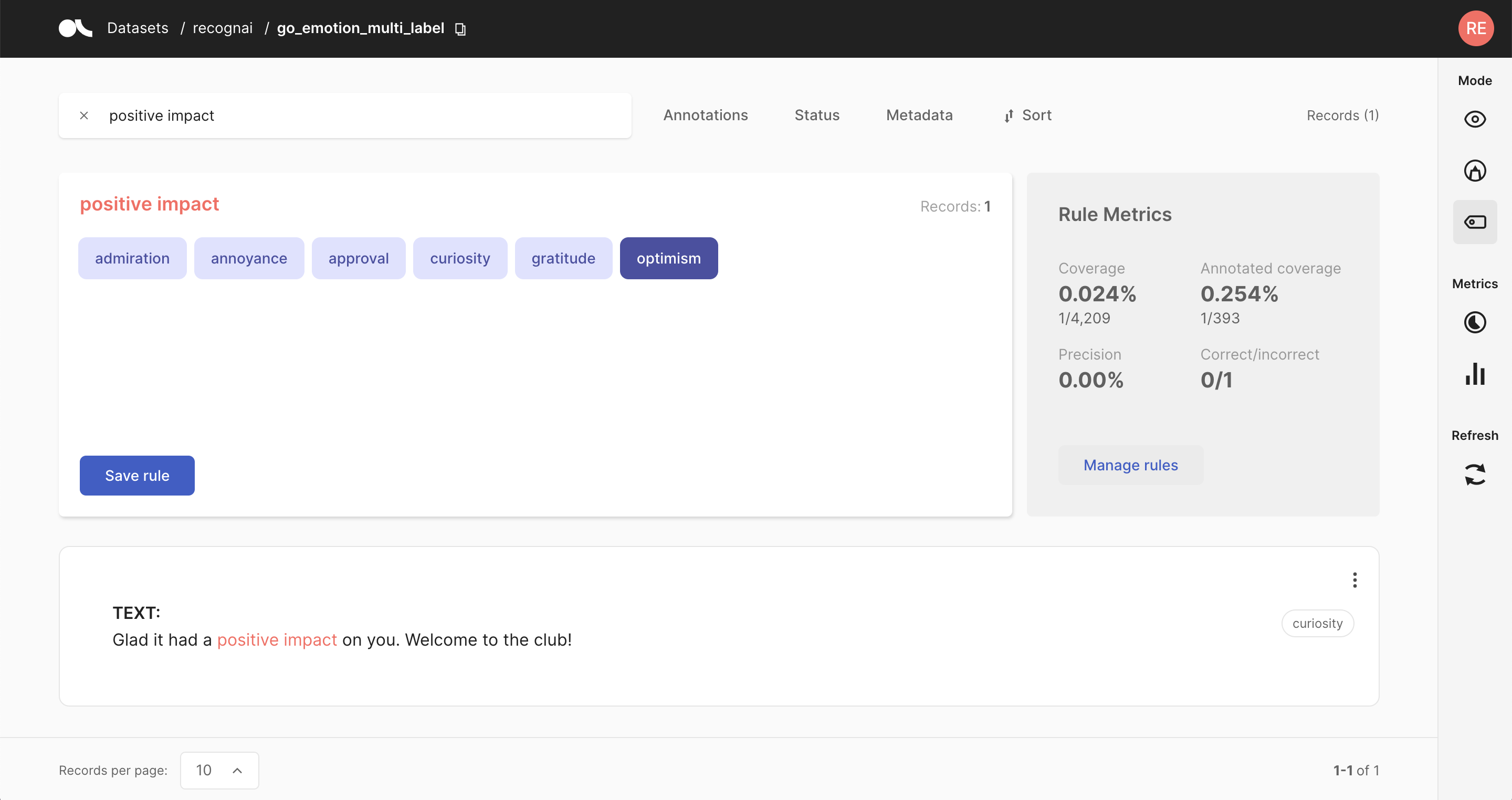
The Argilla UI has a dedicated mode to find good heuristic rules, also often referred to as labeling functions, for a weak supervision workflow. As shown in our guide and tutorial, these rules allow you to quickly annotate your data with noisy labels in a semiautomatic way.
You can access the Weak labeling mode via the sidebar of the Dataset page.
Note
The Weak labeling mode is only available for text classification datasets.
Query plus labels#
A rule in Argilla basically applies a chosen set of labels to a list of records that match a given query, so all you need is a query plus labels. After entering a query in the search bar and selecting one or multiple labels, you will see some metrics for the rule on the right and the matches of your query in the record list below.
Warning
Filters are not part of the rule but are applied to the record list. This means that, if you have filters set, the record list does not necessarily correspond to the records affected by the rule.
If you are happy with the metrics and/or the matching record list, you can save the rule by clicking on “Save rule”. In this way, it will be stored as part of the current dataset and can be accessed via the manage rules button.
Hint
If you want to add labels to the available list of labels, you can go to your Dataset Settings page and create new labels there.
Rule Metrics#
After entering a query and selecting labels, Argilla provides you with some key metrics about the rule. Some metrics are only available if your dataset has also annotated records.
Coverage: Percentage of records labeled by the rule.
Annotated coverage: Percentage of annotated records labeled by the rule.
Correct/incorrect: Number of labels the rule predicted correctly/incorrectly with respect to the annotations.
Precision: Percentage of correct labels given by the rule with respect to the annotations.
Note
For multi-label classification tasks, we only count wrongly predicted labels as incorrect, not labels that the rule misses.
Overall rule metrics#
From the right sidebar you can access the Overall rule metrics. Here you will find the aggregated metrics, such as the coverages, the average precision and the total number of correctly/incorrectly predicted labels. You can also find an overview of how many rules you saved and how they are distributed with respect to their labels.
Hint
If you struggle to increase the overall coverage, try to filter for the records that are not covered by your rules via the Annotation filter.
Manage rules#
Here you will see a list of your saved rules. You can edit a rule by clicking on its name, or delete it by clicking on the trash icon.
Semantic search#
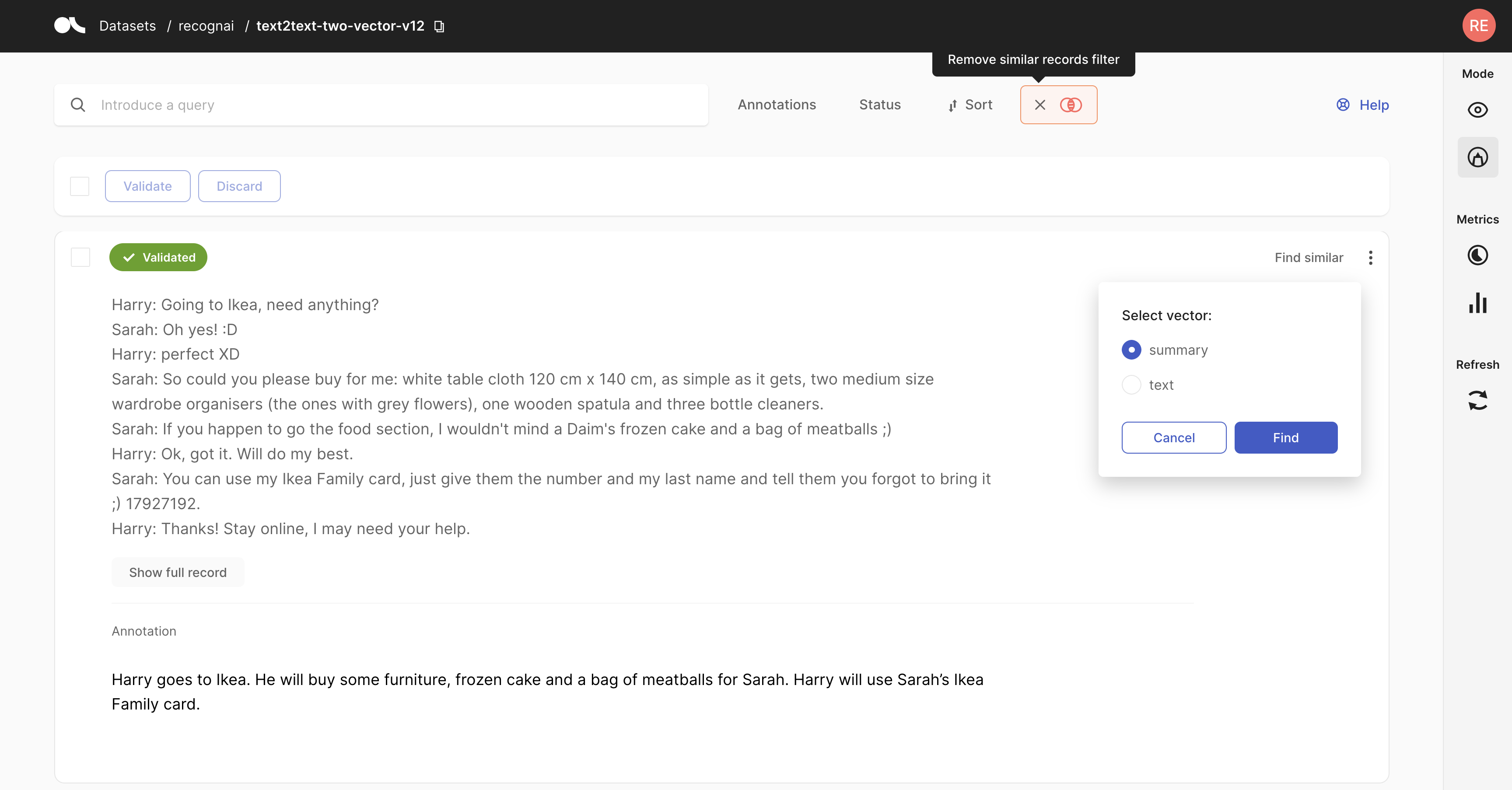
This feature enables you to find similar records when exploring or annotating records. This leverages semantic search to find “semantically” similar records. In order to use this feature, your dataset records should contain vectors that can be associated when logging the dataset into Argilla. Check the Deep Dive Feature guide about Semantic Search to understand how to benefit from this feature.
Explore records#
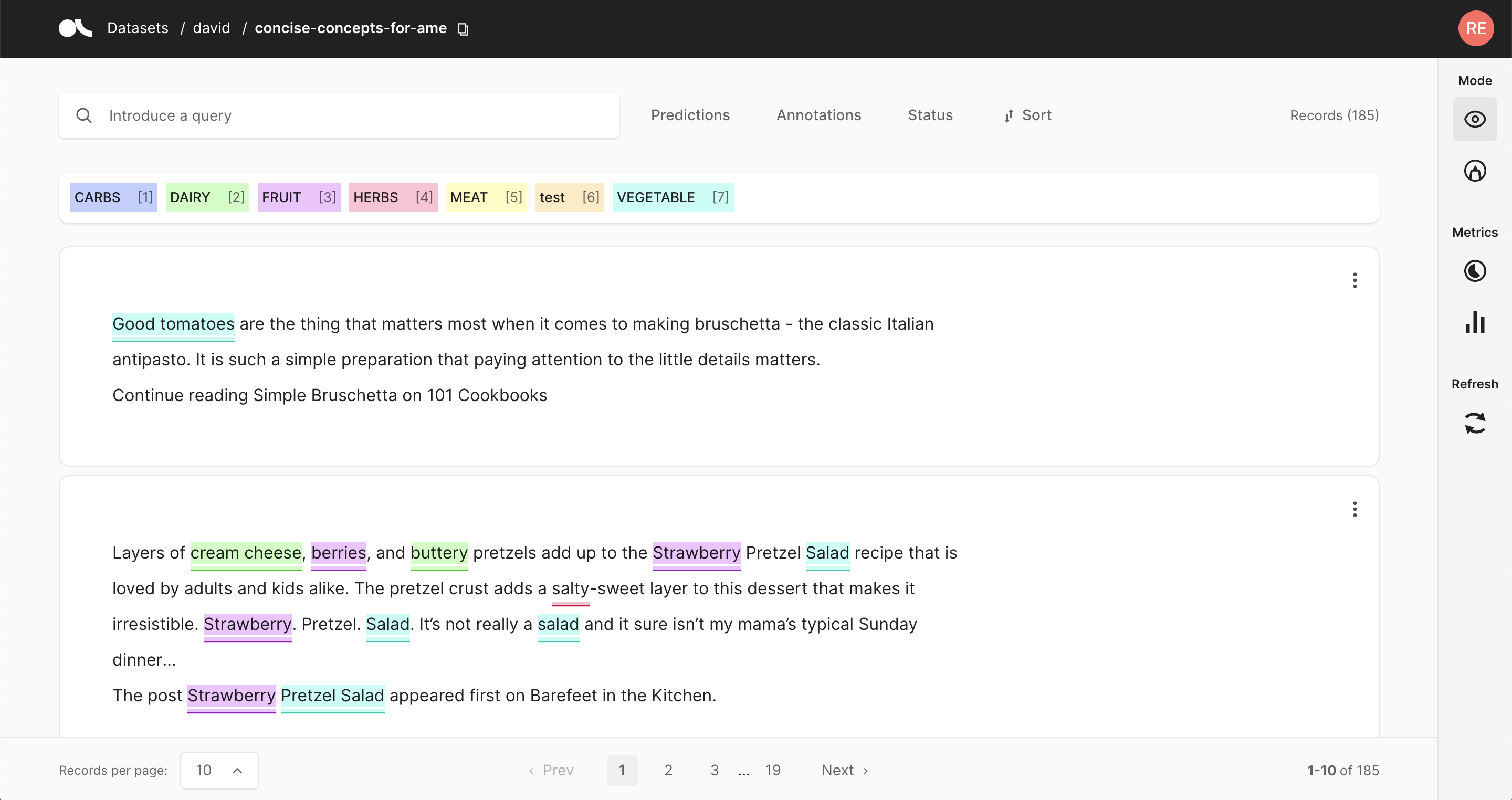
If you want to explore your dataset or analyze the predictions of a model, the Argilla UI offers a dedicated Explore mode. The powerful search functionality and intuitive filters allow you to quickly navigate through your records and dive deep into your dataset. At the same time, you can view the predictions and compare them to gold annotations.
You can access the Explore mode via the sidebar of the Dataset page.
Search and filter#
The powerful search bar allows you to do simple, quick searches, as well as complex queries that take full advantage of Argilla’s data models. In addition, the filters provide you a quick and intuitive way to filter and sort your records with respect to various parameters, including predictions and annotations. Both of the components can be used together to dissect in-depth your dataset, validate hunches, and find specific records.
You can find more information about how to use the search bar and the filters in our detailed search guide and filter guide.
Note
Not all filters are available for all tasks.
Predictions and annotations#
Predictions and annotations are an integral part of Argilla’s data models The way they are presented in the Argilla UI depends on the task of the dataset and the mode activated in the right column.
Text classification#
In this task, the predictions are given as tags below the input text. They contain the label as well as a percentage score.
In the annotation view, the predicted labels come in a slightly darker tone, while annotations have a much darker shade and white lettering. In the exploration view, the predicted labels appear below the input text and annotations are shown as tags on the right side of the card.
Token classification#
In this task, predictions and annotations are displayed as highlights in the input text. To easily identify them at a glance, annotations are highlighted with the color of their corresponding label, while predictions are underlined with a solid line.
Text2Text#
In this task, the prediction with the highest score appears in a text field below the input text. You can switch between predictions by clicking on their associated score, which appears on the upper right corner.
Once you start making changes to the text or after you have validated the annotation, the predictions will still be visible from the Prediction banner at the right hand side of the text field.
Metrics#
From the sidebar you can access the Stats metrics that provide support for your analysis of the dataset.
Search Records#
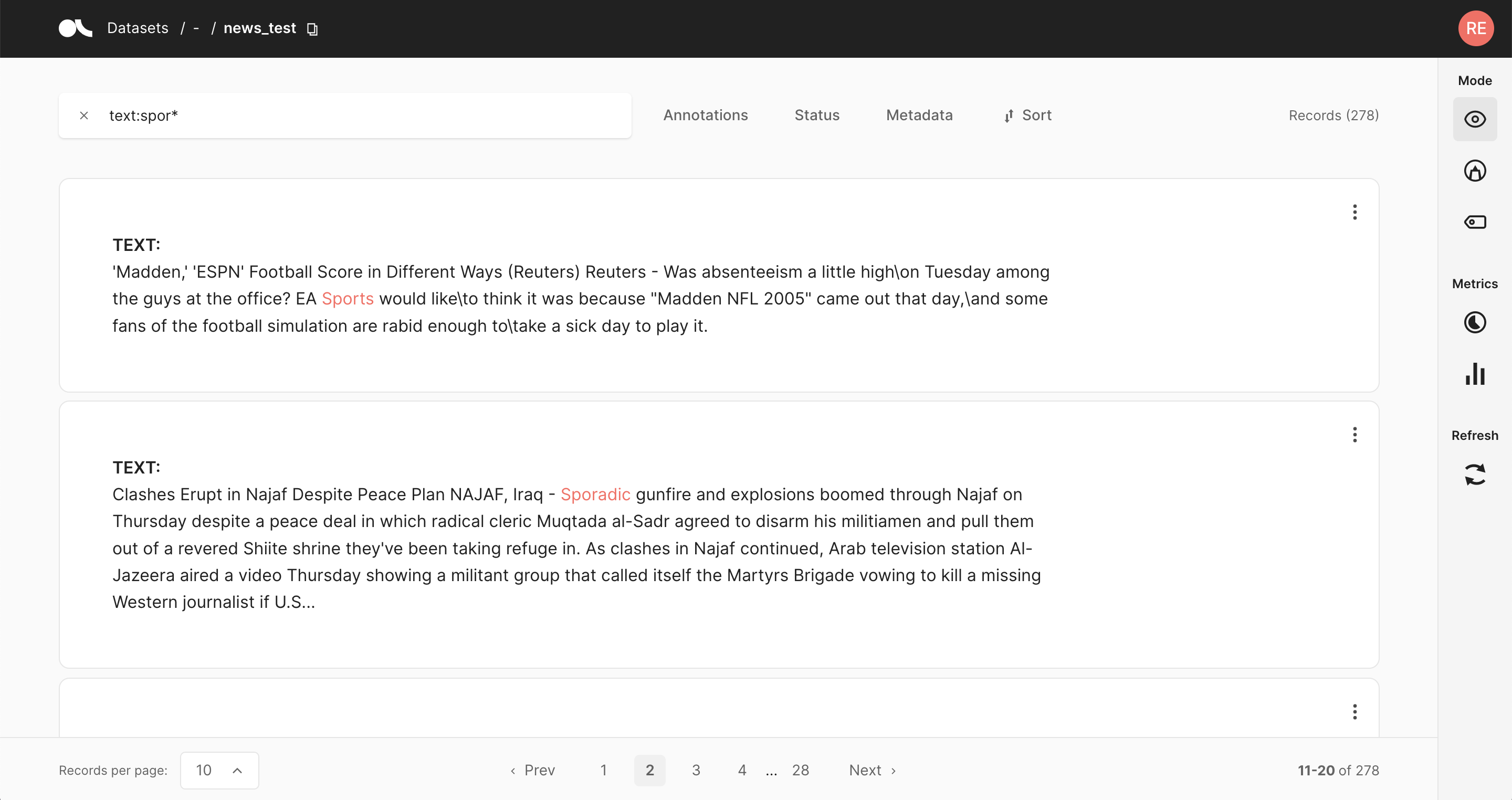
The search bar in Argilla is driven by Elasticsearch’s powerful query string syntax.
It allows you to perform simple fuzzy searches of words and phrases, or complex queries taking full advantage of Argilla’s data model.
Check out the query guide for a comprehensive guide on how to search in the Argilla UI.
Filter Records#
The Argilla UI provides a set of filters that help you to quickly and conveniently navigate your records. For example, you can filter records by their predictions, by a specific metadata, or choose to only view records that are missing annotations. The filters are available in all modes of the UI.
Hint
You can also filter the records through the search bar by means of queries.
Note
Not all filters listed below are available for all tasks.
Predictions filter#
This filter allows you to filter records with respect to their predictions:
Predicted as: filter records by their predicted labels
Predicted ok: filter records whose predictions do, or do not, match the annotations
Score: filter records with respect to the score of their prediction
Predicted by: filter records by the prediction agent
Annotations filter#
This filter allows you to filter records with respect to their annotations:
Annotated as: filter records with respect to their annotated labels
Annotated by: filter records by the annotation agent
Only records not covered by rules: this option only appears if you defined rules for your dataset. It allows you to show only records that are not covered by your rules.
Status filter#
This filter allows you to filter records with respect to their status:
Default: records without any annotation or edition
Validated: records with validated annotations
Edited: records with annotations but still not validated
Metadata filter#
This filter allows you to filter records with respect to their metadata.
Hint
Nested metadata will be flattened and the keys will be joined by a dot.
Sort records#
With this component, you can sort the records by various parameters, such as the predictions, annotations or their metadata.
Examples#
Here we will provide a few examples of how you can take advantage of the filters for different use cases.
Missing annotations#
If you are annotating records and want to display only records that do not have an annotation yet, you can set the status filter to Default.
Low scores#
If you uploaded model predictions and want to check for which records the model still struggles with, you can use the score filter to filter records with a low score.
High loss#
If you logged the model loss as metadata for each record, you can sort the records by this loss in descending order to see records for which the model disagrees with the annotations (see this tutorial for an example).
View dataset metrics#
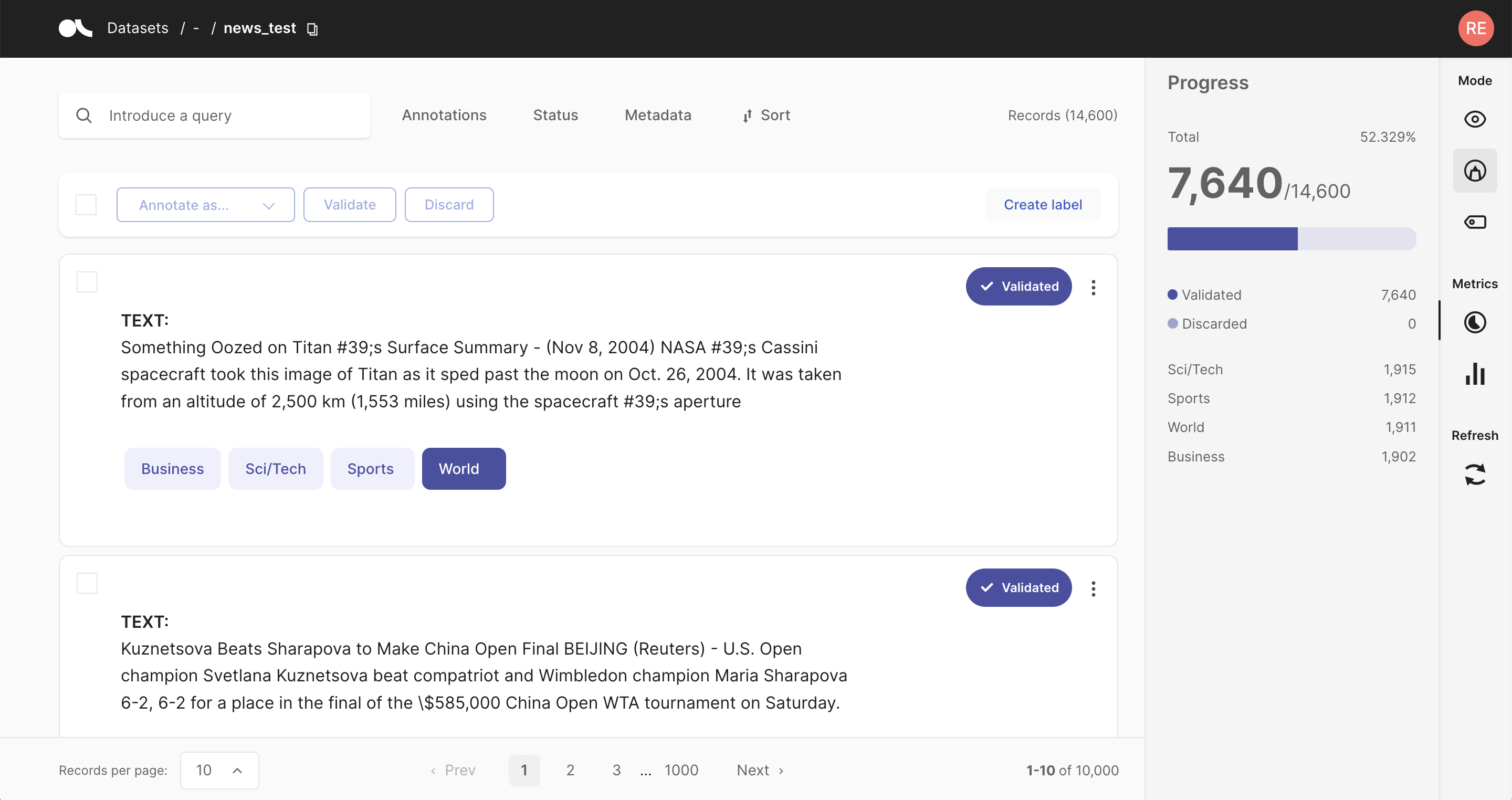
The Dataset Metrics are part of the Sidebar placed on the right side of Argilla datasets. To know more about this component, click here.
Argilla metrics are very convenient in terms of assessing the status of the dataset, and extracting valuable information.
How to use Metrics#
Metrics are composed of two submenus: Progress and Stats. These submenus might be different for Token and Text Classification tasks, as well as for the different modes (especially the Weak labeling mode).
Progress#
This submenu is useful when users need to know how many records have been annotated, validated and/or discarded.
Annotation and Explore modes#
When clicking on this menu, not only the progress is shown. The number of records is also displayed, as well as the number of labeled records or entities that are validated or discarded.
Weak labeling mode#
In this mode, progress is related to the coverage of the rules. It shows the model coverage and the annotated coverage, and also the precision average and the number of correct and incorrect results.
In the total rules section, users can find the number of rules related to the different categories.
Stats#
This submenu allows users to know more about the keywords of the dataset.
Explore and Weak labeling mode#
In both modes, the Keywords list displays a list of relevant words and the number of occurrences.
Annotation mode#
In the annotation mode, the stats show the mentions (this is, the entities) that are present in the records.
This submenu has the Predicted as (for predictions) and the Annotated as (for annotation) sections, and here users can see the number of entities predicted or annotated with a specific label. The number of occurrences is ordered from highest to lowest, and the labels are also ordered in that way.