unstructured: Large-scale document processing for LLMs#
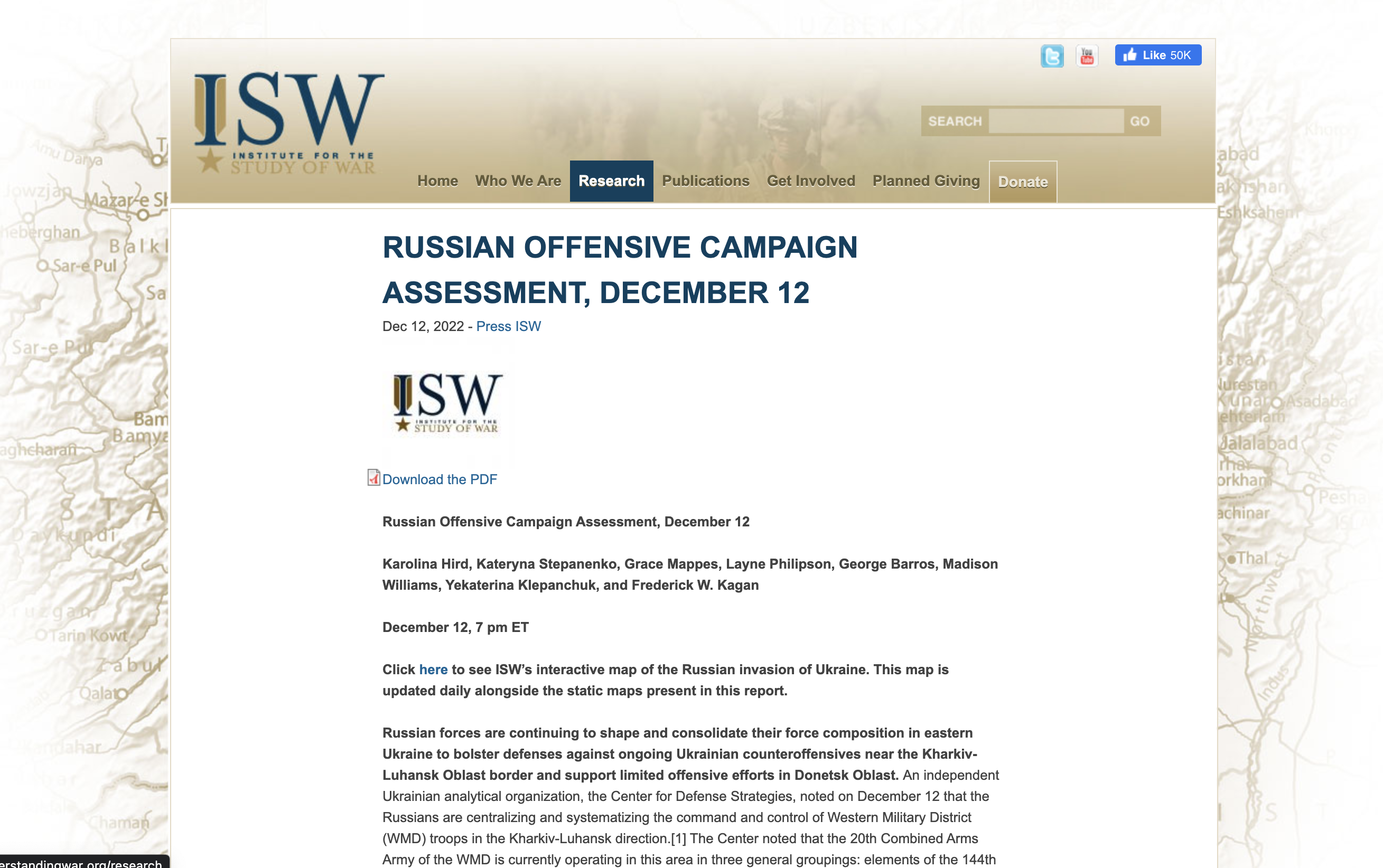
In this notebook, we’ll show you how you can use the amazing library unstructured together with argilla, and HuggingFace transformers to train a custom summarization model. In this case, we’re going to build a summarization model targeted at summarizing the Institute for the Study of War’s daily reports on the war in Ukraine. You can see an example of one of the reports here, and a screenshot appears below.
Attribution 🎉
This notebook has been developed by Matt Robinson, from Unstructured. Unstructured is the recommended library for collecting unstructured formats for Argilla datasets, such as HTML docs and PDFs. If you don’t know Unstructured yet, go to the unstructured GitHub repo and leave a star if you like what they’re building.
Introduction#
Combining the unstructured, argilla, and transformers libraries, we’re able to complete a data science project that previously could have taken a week or more in just a few hours!
Section 1: Data Collection and Staging with unstructured
Section 2: Label Verification with Argilla
Section 3: Model Training with transformers
Running Argilla#
For this tutorial, you will need to have an Argilla server running. There are two main options for deploying and running Argilla:
Deploy Argilla on Hugging Face Spaces: If you want to run tutorials with external notebooks (e.g., Google Colab) and you have an account on Hugging Face, you can deploy Argilla on Spaces with a few clicks:

For details about configuring your deployment, check the official Hugging Face Hub guide.
Launch Argilla using Argilla’s quickstart Docker image: This is the recommended option if you want Argilla running on your local machine. Note that this option will only let you run the tutorial locally and not with an external notebook service.
For more information on deployment options, please check the Deployment section of the documentation.
Tip
This tutorial is a Jupyter Notebook. There are two options to run it:
Use the Open in Colab button at the top of this page. This option allows you to run the notebook directly on Google Colab. Don’t forget to change the runtime type to GPU for faster model training and inference.
Download the .ipynb file by clicking on the View source link at the top of the page. This option allows you to download the notebook and run it on your local machine or on a Jupyter Notebook tool of your choice.
[ ]:
%pip install "unstructured==0.4.4" -qqq
Let’s import the Argilla module for reading and writing data:
[ ]:
import argilla as rg
If you are running Argilla using the Docker quickstart image or Hugging Face Spaces, you need to init the Argilla client with the URL and API_KEY:
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
rg.init(
api_url="http://localhost:6900",
api_key="admin.apikey"
)
If you’re running a private Hugging Face Space, you will also need to set the HF_TOKEN as follows:
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="admin.apikey",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
Finally, let’s include the imports we need:
[ ]:
import calendar
from datetime import datetime
import re
import time
import requests
from transformers import pipeline
import tqdm
from unstructured.partition.html import partition_html
from unstructured.documents.elements import NarrativeText, ListItem
from unstructured.staging.argilla import stage_for_argilla
import nltk
nltk.download('averaged_perceptron_tagger')
Section 1: Data Collection and Staging with unstructured#
First, we’ll pull our documents from the ISW website. We’ll use the built-in Python datetime and calendar libraries to iterate over the dates for the reports we want to pull and fine the associated URLs.
[4]:
ISW_BASE_URL = "https://www.understandingwar.org/backgrounder/russian-offensive-campaign-assessment"
def datetime_to_url(dt):
month = dt.strftime("%B").lower()
return f"{ISW_BASE_URL}-{month}-{dt.day}"
[5]:
urls = []
year = 2022
for month in range(3, 13):
_, last_day = calendar.monthrange(year, month)
for day in range(1, last_day + 1):
dt = datetime(year, month, day)
urls.append(datetime_to_url(dt))
Once we have the URLs, we can pull the HTML document for each report from the web using the requests library. Normally, you’d need to write custom HTML parsing code using a library like lxml or beautifulsoup to extract the narrative text from the webpage for model training. With the unstructured library, you can simply call the partition_html function to extract the content of interest.
[6]:
def url_to_elements(url):
r = requests.get(url)
if r.status_code != 200:
return None
elements = partition_html(text=r.text)
return elements
After partitioning the document, we’ll extract the Key Takeaways section from the ISW reports, which is shown in the screenshot below. The Key Takeaways section will serve as the target text for our summarization model. While it would be time-consuming the write HTML parsing code to find this content, with the unstructured library it is easy. Since the partition_html function breaks down the elements of the document into different categories like Title, NarrativeText, and
ListItem, all we need to do is find the Key Takeaways title and then grab ListItem elements until the list ends. This logic is implemented in the get_key_takeaways function.

[12]:
def _find_key_takeaways_idx(elements):
for idx, element in enumerate(elements):
if element.text == "Key Takeaways":
return idx
def get_key_takeaways(elements):
key_takeaways_idx = _find_key_takeaways_idx(elements)
if not key_takeaways_idx:
return None
takeaways = []
for element in elements[key_takeaways_idx + 1:]:
if not isinstance(element, ListItem):
break
takeaways.append(element)
takeaway_text = " ".join([el.text for el in takeaways])
return NarrativeText(text=takeaway_text)
[13]:
elements = url_to_elements(urls[200])
[14]:
print(get_key_takeaways(elements))
Russian forces continue to prioritize strategically meaningless offensive operations around Donetsk City and Bakhmut over defending against continued Ukrainian counter-offensive operations in Kharkiv Oblast. Ukrainian forces liberated a settlement southwest of Lyman and are likely continuing to expand their positions in the area. Ukrainian forces continued to conduct an interdiction campaign in Kherson Oblast. Russian forces continued to conduct unsuccessful assaults around Bakhmut and Avdiivka. Ukrainian sources reported extensive partisan attacks on Russian military assets and logistics in southern Zaporizhia Oblast. Russian officials continued to undertake crypto-mobilization measures to generate forces for war Russian war efforts. Russian authorities are working to place 125 “orphan” Ukrainian children from occupied Donetsk Oblast with Russian families.
Next, we’ll grab the narrative text from the document as input for our model. Again, this is easy with unstructured because the partition_html function already splits out the text. We’ll just grab all of the NarrativeText elements that exceed a minimum length threshold. While we’re in there, we’ll also clean out the raw text for citations within the document, which isn’t natural language and could impact the quality of our summarization model.
[15]:
def get_narrative(elements):
narrative_text = ""
for element in elements:
if isinstance(element, NarrativeText) and len(element.text) > 500:
# NOTE: Removes citations like [3] from the text
element_text = re.sub("\[\d{1,3}\]", "", element.text)
narrative_text += f"\n\n{element_text}"
return NarrativeText(text=narrative_text.strip())
[28]:
# Show a sample of narrative text
print(get_narrative(elements).text[0:2000])
Russian forces continue to conduct meaningless offensive operations around Donetsk City and Bakhmut instead of focusing on defending against Ukrainian counteroffensives that continue to advance. Russian troops continue to attack Bakhmut and various villages near Donetsk City of emotional significance to pro-war residents of the Donetsk People’s Republic (DNR) but little other importance. The Russians are apparently directing some of the very limited reserves available in Ukraine to these efforts rather than to the vulnerable Russian defensive lines hastily thrown up along the Oskil River in eastern Kharkiv Oblast. The Russians cannot hope to make gains around Bakhmut or Donetsk City on a large enough scale to derail Ukrainian counteroffensives and appear to be continuing an almost robotic effort to gain ground in Donetsk Oblast that seems increasingly divorced from the overall realities of the theater.
Russian failures to rush large-scale reinforcements to eastern Kharkiv and to Luhansk Oblasts leave most of Russian-occupied northeastern Ukraine highly vulnerable to continuing Ukrainian counter-offensives. The Russians may have decided not to defend this area, despite Russian President Vladimir Putin’s repeated declarations that the purpose of the “special military operation” is to “liberate” Donetsk and Luhansk oblasts. Prioritizing the defense of Russian gains in southern Ukraine over holding northeastern Ukraine makes strategic sense since Kherson and Zaporizhia Oblasts are critical terrain for both Russia and Ukraine whereas the sparsely-populated agricultural areas in the northeast are much less so. But the continued Russian offensive operations around Bakhmut and Donetsk City, which are using some of Russia’s very limited effective combat power at the expense of defending against Ukrainian counteroffensives, might indicate that Russian theater decision-making remains questionable.
Ukrainian forces appear to be expanding positions east of the Oskil River and
Now we have everything set up, let’s collect all of the reports! This step could take a while, so we added a sleep call to the loop to avoid overwhelming ISW’s webpage.
[ ]:
inputs = []
annotations = []
for url in tqdm.tqdm(urls):
elements = url_to_elements(url)
if url is None or not elements:
continue
text = get_narrative(elements)
annotation = get_key_takeaways(elements)
if text and annotation:
inputs.append(text)
annotations.append(annotation.text)
# NOTE: Sleeping to reduce the volume of requests to ISW
time.sleep(1)
Section 2: Label Verification with argilla#
Now that we’ve collected the data and prepared it with unstructured, we’re ready to work on our data labels in argilla. First, we’ll use the stage_for_argilla staging brick from the unstructured library. This will automatically convert our dataset to a DatasetForText2Text object, which we can then import into Argilla.
[31]:
dataset = stage_for_argilla(inputs, "text2text", annotation=annotations)
[32]:
dataset.to_pandas().head()
[32]:
| text | prediction | prediction_agent | annotation | annotation_agent | vectors | id | metadata | status | event_timestamp | metrics | search_keywords | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Russian forces are completing the reinforcemen... | None | None | Russian forces are setting conditions to envel... | None | None | 1a5b66dcbf80159ce2c340b17644d639 | {} | Validated | 2023-01-31 11:19:52.784880 | None | None |
| 1 | Russian forces resumed offensive operations in... | None | None | Russian forces resumed offensive operations ag... | None | None | 32e2f136256a7003de06c5792a5474fe | {} | Validated | 2023-01-31 11:19:52.784941 | None | None |
| 2 | The Russian military has continued its unsucce... | None | None | Russian forces opened a new line of advance fr... | None | None | 6e4c94cdc2512ee7b915c303161ada1d | {} | Validated | 2023-01-31 11:19:52.784983 | None | None |
| 3 | Russian forces continue their focus on encircl... | None | None | Russian forces have advanced rapidly on the ea... | None | None | 5c123326055aa4832014ed9ab07e80f1 | {} | Validated | 2023-01-31 11:19:52.785022 | None | None |
| 4 | Russian forces remain deployed in the position... | None | None | Russian forces conducted no major offensive op... | None | None | b6597ad2ca8a352bfc46a04b85b22421 | {} | Validated | 2023-01-31 11:19:52.785060 | None | None |
After staging the data for argilla, we can call the rg.log function from the argilla Python library to upload the data to the Argilla UI. Before running this step, ensure that you have the Argilla Server running in the background. After logging the data to Argilla, your UI should look like the screenshot below.
[ ]:
rg.log(dataset, name="isw-summarization")
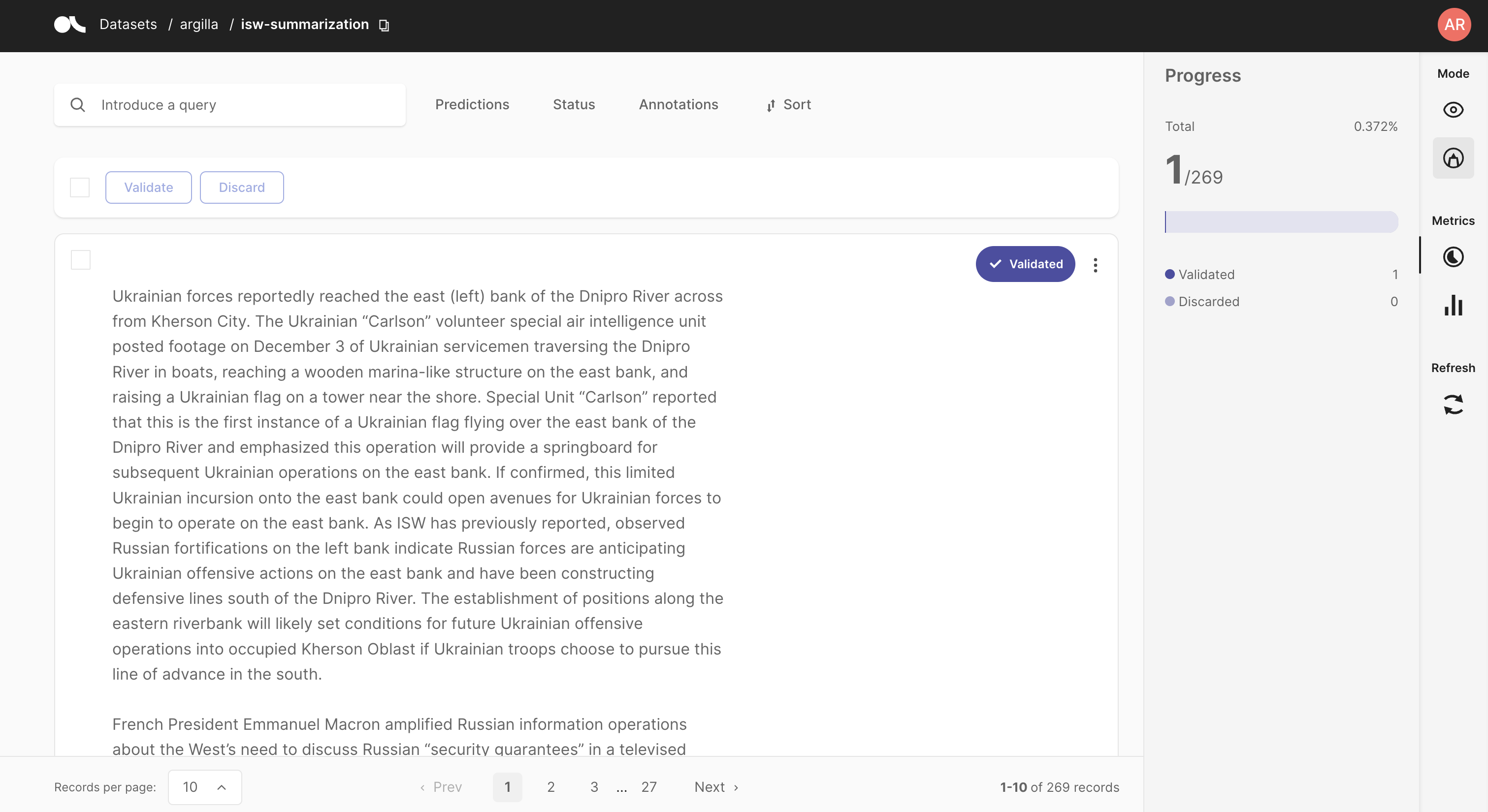
After uploading the dataset, head over to the Argilla UI and validate and/or adjust the summaries we pulled from the ISW site. You can also check out the Argilla docs for more information on all of the exciting tools Argilla provides to help you label, assess, and refine your training data!
Section 3: Model Training with transformers#
After refining our training data in Argilla, we’re ready to fine-tune our model using the transformers library. Luckily, argilla has a utility for converting datasets to a dataset.Dataset, which is the format required by the transformers Trainer object. In this example, we’ll train a t5-small model to keep the runtime for the notebook reasonable. You can play around with larger models to get higher-quality results.
[18]:
training_data = rg.load("isw-summarization").to_datasets()
[19]:
model_checkpoint = "t5-small"
[ ]:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint)
[21]:
max_input_length = 1024
max_target_length = 128
def preprocess_function(examples):
inputs = [doc for doc in examples["text"]]
model_inputs = tokenizer(inputs, max_length=max_input_length, truncation=True)
# Setup the tokenizer for targets
with tokenizer.as_target_tokenizer():
labels = tokenizer(examples["annotation"], max_length=max_target_length, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
[ ]:
tokenized_datasets = training_data.map(preprocess_function, batched=True)
[23]:
from transformers import AutoModelForSeq2SeqLM, DataCollatorForSeq2Seq, Seq2SeqTrainingArguments, Seq2SeqTrainer
model = AutoModelForSeq2SeqLM.from_pretrained(model_checkpoint)
[24]:
batch_size = 16
model_name = model_checkpoint.split("/")[-1]
args = Seq2SeqTrainingArguments(
"t5-small-isw-summaries",
evaluation_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
save_total_limit=3,
num_train_epochs=1,
predict_with_generate=True,
fp16=False,
push_to_hub=False,
)
[25]:
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
[26]:
trainer = Seq2SeqTrainer(
model,
args,
train_dataset=tokenized_datasets,
eval_dataset=tokenized_datasets,
data_collator=data_collator,
tokenizer=tokenizer,
)
[ ]:
trainer.train()
[ ]:
trainer.save_model("t5-small-isw-summaries")
[ ]:
summarization_model = pipeline(
task="summarization",
model="./t5-small-isw-summaries",
)
Now that our model is trained, we can save it locally and use our unstructured helper functions to grab future reports for inference!
[30]:
elements = url_to_elements(urls[200])
narrative_text = get_narrative(elements)
results = summarization_model(str(narrative_text), max_length=100)
print(results[0]["summary_text"])
Russian forces continue to attack Bakhmut and various villages near Donetsk City . the Russians are apparently directing some of the very limited reserves available in Ukraine to these efforts rather than to the vulnerable Russian defensive lines hastily thrown up . Russian sources claimed that Russian forces are repelled a Ukrainian ground attack on Pravdyne .