🥇 Compare Text Classification Models#
In this tutorial, you’ll learn to make text classification on a dataset using two different models, upload models predictions in your Argilla workspace and compare models by computing the F1 score for each model. It will walk you through these steps: - 💾 Load the dataset you want to use. - 💻 Compute predictions with a zero-shot classification model. - 🔄 Convert model output to Argilla format and upload it to Argilla workspace. - 💻 Compute predictions with zero-shot SetFit model. - 🧪 Compare models predictions with F1 score
Introduction#
When working on Text Classification, you may want to compare two models to decide which one to use. For this, we compute the F1 score on train models using their annotations as the true text class. The F1 score can be interpreted as a harmonic mean of the precision and recall, where an F1 score reaches its best value at 1 and worst score at 0. (more info in this documentation)
Argilla allows you to deploy and monitor any model you like, but in this tutorial, we will focus on the two most common frameworks in the NLP space: transformers and SetFit. Let’s get started!
Running Argilla#
For this tutorial, you will need to have an Argilla server running. There are two main options for deploying and running Argilla:
Deploy Argilla on Hugging Face Spaces: If you want to run tutorials with external notebooks (e.g., Google Colab) and you have an account on Hugging Face, you can deploy Argilla on Spaces with a few clicks:

For details about configuring your deployment, check the official Hugging Face Hub guide.
Launch Argilla using Argilla’s quickstart Docker image: This is the recommended option if you want Argilla running on your local machine. Note that this option will only let you run the tutorial locally and not with an external notebook service.
For more information on deployment options, please check the Deployment section of the documentation.
Tip
This tutorial is a Jupyter Notebook. There are two options to run it:
Use the Open in Colab button at the top of this page. This option allows you to run the notebook directly on Google Colab. Don’t forget to change the runtime type to GPU for faster model training and inference.
Download the .ipynb file by clicking on the View source link at the top of the page. This option allows you to download the notebook and run it on your local machine or on a Jupyter Notebook tool of your choice.
Setup#
To complete this tutorial, you will need to install the Argilla client and a few third-party libraries using pip:
[1]:
%pip install transformers argilla datasets torch setfit -qqqqqqq
The imports needed:
[2]:
import argilla as rg
from datasets import load_dataset
from transformers import pipeline
from argilla.metrics.text_classification import f1
import pandas as pd
If you are running Argilla using the Docker quickstart image or Hugging Face Spaces, you need to init the Argilla client with the URL and API_KEY:
[3]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
# Replace workspace with the name of your workspace
rg.init(
api_url="http://localhost:6900",
api_key="owner.apikey",
workspace="admin"
)
If you’re running a private Hugging Face Space, you will also need to set the HF_TOKEN as follows:
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# # Replace workspace with the name of your workspace
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="owner.apikey",
# workspace="admin",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
For this tutorial the HugginFace ag_news dataset is chosen:
[ ]:
news_dataset = load_dataset("ag_news", split="test")
This dataset is composed of two columns, one is the text of the news article and the other one is the label associated with this text article:
For this tutorial, we will consider the label as the annotation of the text
We transform our dataset in order to create an argilla TextClassificationDataset:
[ ]:
int_to_label = {
0:"World",
1:"Sports",
2:"Business",
3:"Sci/Tech",
}
news_dataset = news_dataset.map(lambda row: {"prediction": [{"label":int_to_label[row["label"]], "score":1}]})
[ ]:
ds_record = rg.read_datasets(dataset=news_dataset, task="TextClassification")
Enable Telemetry#
We gain valuable insights from how you interact with our tutorials. To improve ourselves in offering you the most suitable content, using the following lines of code will help us understand that this tutorial is serving you effectively. Though this is entirely anonymous, you can choose to skip this step if you prefer. For more info, please check out the Telemetry page.
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
Make Zero Shot Text Classification predictions using transformers#
On HugginFace we choose the model cross-encoder/nli-distilroberta-base that is trained to perform zero-shot classification. We create a pipeline with this model and then perform prediction.
note: ``device=0`` in pipeline() permits to use GPU if you do not have a GPU available delete this parameter
[7]:
labels =["Sports", "Sci/Tech", "Business", "World"]
pipe = pipeline("zero-shot-classification", model='cross-encoder/nli-distilroberta-base', device=0)
result = []
with pipe.device_placement():
result = pipe(
[data.text for data in ds_record],
candidate_labels=labels,
)
Now that predictions are successfully made with the zero-shot model we can transform it into a list of argilla TextClassificationRecord and upload it to our argilla client
[ ]:
zero_shot_news_dataset = [
rg.TextClassificationRecord(
text=res["sequence"],
prediction=list(zip(res['labels'],res['scores'])),
annotation=record.prediction[0][0],
) for res, record in zip(result, ds_record)
]
rg.log(name="zero_shot_news_dataset", records=zero_shot_news_dataset)
You can access the zero_shot_news_dataset in the Argilla UI:
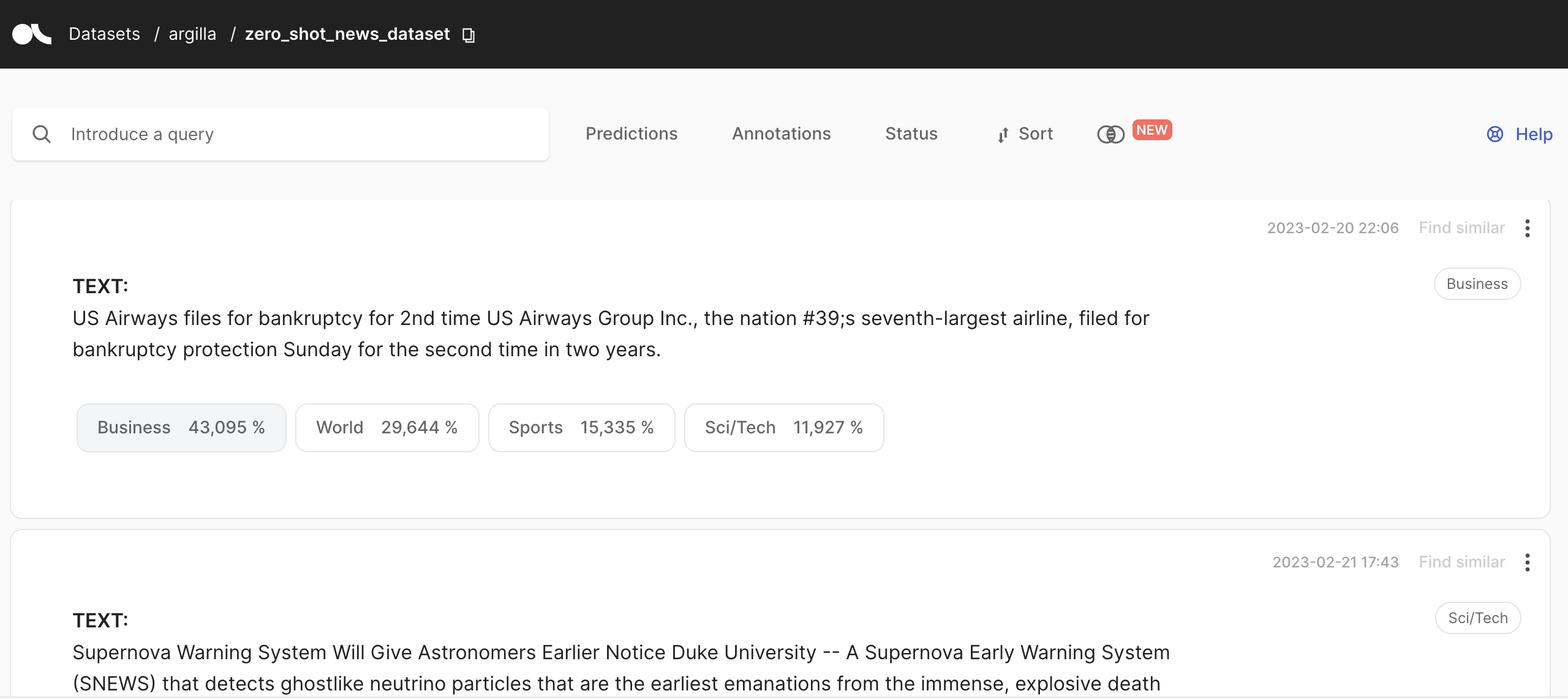
Finally, we measure the performance of our model using the argilla f1 function that computes the F1 score:
[9]:
f1_zero_shot = f1("zero_shot_news_dataset")
f1_zero_shot.visualize()
Make zero-shot text classification using a trained SetFit classifier#
The imports needed:
[10]:
from setfit import SetFitModel, SetFitTrainer, get_templated_dataset
We create a synthetic dataset of training examples using our dataset’s labels
[11]:
labels = ["Sports", "Sci/Tech", "Business", "World"]
train_dataset = get_templated_dataset(
candidate_labels=labels,
sample_size=8,
template="The news article is about {}"
)
We train a SetFitModel using the pretrained model ‘all-MiniLM-L6-v2’
[ ]:
model = SetFitModel.from_pretrained("all-MiniLM-L6-v2")
trainer = SetFitTrainer(
model=model,
train_dataset=train_dataset
)
trainer.train()
We are then able to compute the text classification:
[13]:
result = [{
'sequence': data["text"],
'scores': model.predict_proba([data["text"]]).squeeze().numpy(),
'labels': labels
} for data in news_dataset]
Finally, we can log the result dataset into Argilla and compute the F1 score:
[ ]:
setfit_zero_shot_news_dataset = [
rg.TextClassificationRecord(
text=res["sequence"],
prediction=list(zip(res['labels'],res['scores'])),
annotation=record.prediction[0][0],
) for res, record in zip(result, ds_record)
]
rg.log(name="setfit_zero_shot_news_dataset", records=setfit_zero_shot_news_dataset)
You can access the setfit_zero_shot_news_dataset in the Argilla UI:
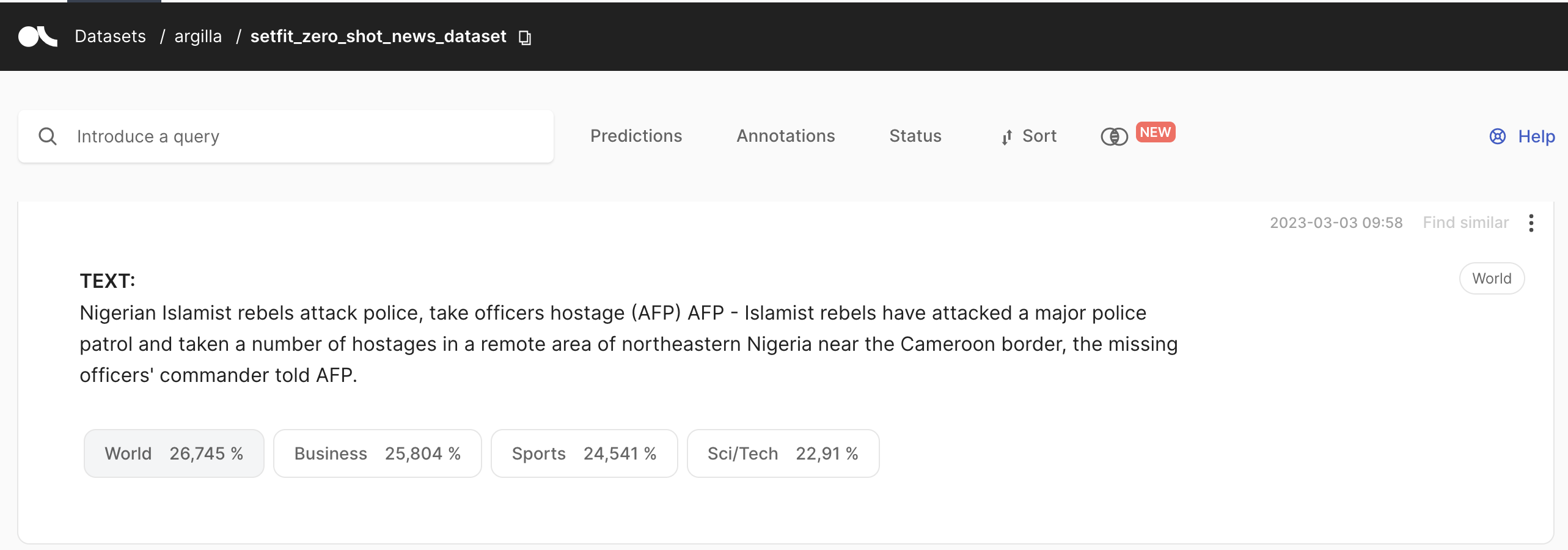
[15]:
f1_setfit_zero_shot = f1("setfit_zero_shot_news_dataset")
f1_setfit_zero_shot.visualize()
Now that we have computed the F1 score for each model with can create a comparison table:
[16]:
f_score = list(f1_setfit_zero_shot.data.keys())
f1_setfit_zero_shot_values = list(f1_setfit_zero_shot.data.values())
f1_zero_shot_values = list(f1_zero_shot.data.values())
unnecessary_labels = ["Sports_recall", "World_recall", ""]
df_results = pd.DataFrame({"f_score": f_score, "zero-shot classification": f1_zero_shot_values, "zero-shot SetFit classification": f1_setfit_zero_shot_values})
[17]:
df_results
[17]:
| f_score | zero-shot classification | zero-shot SetFit classification | |
|---|---|---|---|
| 0 | precision_macro | 0.517754 | 0.663322 |
| 1 | recall_macro | 0.529605 | 0.668816 |
| 2 | f1_macro | 0.514483 | 0.663725 |
| 3 | precision_micro | 0.529605 | 0.668816 |
| 4 | recall_micro | 0.529605 | 0.668816 |
| 5 | f1_micro | 0.529605 | 0.668816 |
| 6 | Sci/Tech_precision | 0.476950 | 0.556291 |
| 7 | Sci/Tech_recall | 0.283158 | 0.530526 |
| 8 | Sci/Tech_f1 | 0.355350 | 0.543103 |
| 9 | Sci/Tech_support | 11400.000000 | 7600.000000 |
| 10 | World_precision | 0.367909 | 0.663734 |
| 11 | World_recall | 0.358421 | 0.555789 |
| 12 | World_f1 | 0.363103 | 0.604984 |
| 13 | World_support | 11400.000000 | 7600.000000 |
| 14 | Business_precision | 0.449227 | 0.620098 |
| 15 | Business_recall | 0.565789 | 0.665789 |
| 16 | Business_f1 | 0.500815 | 0.642132 |
| 17 | Business_support | 11400.000000 | 7600.000000 |
| 18 | Sports_precision | 0.776930 | 0.813166 |
| 19 | Sports_recall | 0.911053 | 0.923158 |
| 20 | Sports_f1 | 0.838663 | 0.864678 |
| 21 | Sports_support | 11400.000000 | 7600.000000 |
Results interpretation: Without any hesitation the zero-shot classification using SetFit model is the more effective one. The F1 score for each class is better.
The best-predicted class for both classifiers is Sports.