Argilla concepts#
Feedback Dataset#
Note
The dataset class covered in this section is the FeedbackDataset. This fully configurable dataset will replace the DatasetForTextClassification, DatasetForTokenClassification, and DatasetForText2Text in Argilla 2.0. Not sure which dataset to use? Check out our section on choosing a dataset.
This comprehensive guide introduces the key entities in Argilla Feedback. Argilla Feedback is a powerful platform designed for collecting and managing feedback data from labelers or annotators. By understanding these entities and their relationships, you can effectively utilize the platform and leverage the collected feedback for various applications.
Refer to the diagram below to visualize the relationships between the entities in Argilla Feedback:

Dataset#
The Dataset represents a collection of feedback records. It serves as the container for organizing and managing the feedback data. A dataset consists of multiple Records, which are individual feedback data points. Through datasets, you can configure the structure, fields, and questions for labelers to provide feedback.
Field#
A Field defines the schema or structure for a specific data element within a record. It represents a piece of information that labelers will see and interact with during the feedback process. Examples of fields could include text inputs, checkboxes, or dropdown menus. Fields provide the necessary context and guidance to labelers while collecting feedback.
Question#
A Question represents a specific query or instruction presented to labelers for feedback. Questions play a crucial role in guiding labelers and capturing their input. Argilla Feedback supports different types of questions to accommodate various feedback scenarios.
LabelQuestion: This type of question is designed for capturing feedback in the form of a single label. Labelers can classify a given aspect or attribute using a predefined set of options. It is useful for obtaining a classification where options are mutually exclusive.
MultiLabelQuestion: This type of question is designed for capturing feedback in the form of one or multiple labels. Labelers can classify a given aspect or attribute using a predefined set of options. It is useful for obtaining a classification where options are not exclusive.
RankingQuestion: This type of question is designed to capture the labeler’s preferences. Labelers can order a predefined set of options according to their preference or relevance. It is useful for obtaining feedback on the labeler’s preference among multiple options.
RatingQuestion: This type of question is designed for capturing numerical rating feedback. Labelers can rate a given aspect or attribute using a predefined scale or set of options. It is useful for obtaining quantitative feedback or evaluating specific criteria.
SpanQuestion: This type of question is meant to highlight relevant pieces of text within record fields. It is useful for tasks such as named entity recognition or information extraction.
TextQuestion: This type of question is suitable for collecting natural language feedback or textual responses from labelers. It allows them to provide detailed and descriptive feedback in response to the question.
Guidelines#
Guidelines are a crucial component of the feedback collection process. They provide instructions, expectations, and any specific guidance for labelers to follow while providing feedback. Guidelines help ensure consistency and quality in the collected feedback. It is essential to provide clear and concise guidelines to help labelers understand the context and requirements of the feedback task.
Record#
A Record represents an individual feedback data point within a dataset. It contains the information or data that you want labelers to provide feedback on. Each record includes one or more Fields, which are the specific data elements or attributes that labelers will interact with during the feedback process. Fields define the structure and content of the feedback records.
Response#
Argilla allows for multiple concurrent annotators, seamlessly gathering feedback from many labelers. Each Response represents the input provided by a labeler in response to specific questions within a dataset. It includes the labeler’s identification, the feedback value itself, and a status indicating whether the response has been submitted or discarded. These responses form the foundation of the collected feedback data, capturing the diverse perspectives and insights of the labelers.
Suggestions#
Suggestions enhance the feedback collection process by providing machine-generated feedback to labelers. Suggestions serve as automated decision-making aids, leveraging rules, models, or language models (LLMs) to accelerate the feedback process.
With Suggestions, each record can be equipped with multiple machine-generated recommendations (one per question). These suggestions can act as weak signals, seamlessly combining with human feedback to enhance the efficiency and accuracy of the feedback collection workflow. By leveraging the power of automated suggestions, labelers can make more informed decisions, resulting in a more streamlined, partially automated, and effective feedback collection process.
Metadata#
Metadata will hold extra information that you want your record to have. For example, if it belongs to the training or the test dataset, a quick fact about something regarding that specific record. Feel free to use it as you need!
Vector#
Vectors can be added to a record to represent the semantic meaning of a field or a combination of them. They can be used within the UI or the SDK to search the most or least similar records within your dataset.
Other datasets#
Note
The records classes covered in this section correspond to three datasets: DatasetForTextClassification, DatasetForTokenClassification, and DatasetForText2Text. These will be deprecated in Argilla 2.0 and replaced by the fully configurable FeedbackDataset class. Not sure which dataset to use? Check out our section on choosing a dataset.
Argilla is built around a few simple concepts. This section clarifies what those concepts are. Let’s take a look at Argilla’s data model:
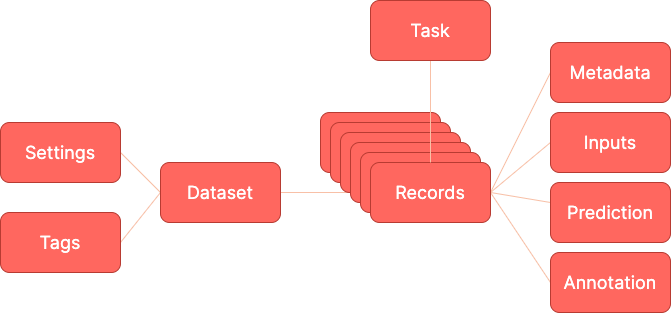
Dataset#
A dataset is a collection of records of a common type.
You can programmatically build datasets with the Argilla client and log them to the web app.
In the web app, you can dive into your dataset to explore and annotate your records.
You can also load your datasets back to the client and export them into various formats, or prepare it for training a model.
Record#
A record is a data item composed of text inputs and, optionally, predictions and annotations.
Think of predictions as the classification that your system made over that input (for example: ‘Virginia Woolf’), and think of annotations as the ground truth that you manually assign to that input (because you know that, in this case, it would be ‘William Shakespeare’). Records are defined by the type of task they are related to. Let’s see three different examples:
Examples#
Note
For information about the Data model for the new FeedbackDataset, check this guide instead.
Text Classification#
Single label
Text classification deals with predicting in which categories a text fits. As if you’re shown an image you can quickly tell if there’s a dog or a cat in it, we build NLP models to distinguish between a novel of Jane Austen and a poem of Charlotte Bronte. It’s all about feeding models with labeled examples and seeing how they start predicting over the very same labels.
Let’s see examples of a spam classifier.
record = rg.TextClassificationRecord(
text="Access this link to get free discounts!",
prediction = [('SPAM', 0.8), ('HAM', 0.2)],
prediction_agent = "link or reference to agent",
annotation = "SPAM",
annotation_agent= "link or reference to annotator",
# Extra information about this record
metadata={
"split": "train"
},
)
Multi label
Another similar task to Text Classification, but yet a bit different, is Multi-label Text Classification, with just one key difference; more than one label may be predicted. While in a regular Text Classification task, we may decide that the tweet “I can’t wait to travel to Egypt and visit the pyramids” fits into the hashtag #Travel, which is accurate, in Multi-label Text Classification, we can classify it as more than one hashtag, like #Travel #History #Africa #Sightseeing #Desert.
record = rg.TextClassificationRecord(
text="I can't wait to travel to Egypt and visit the pyramids",
multi_label = True,
prediction = [('travel', 0.8), ('history', 0.6), ('economy', 0.3), ('sports', 0.2)],
prediction_agent = "link or reference to agent",
annotation = ['travel', 'history'],
annotation_agent= "link or reference to annotator",
)
Token classification#
Tasks of the kind of token classification are NLP tasks aimed at dividing the input text into words, or syllables, and assigning certain values to them. Think about giving each word in a sentence its grammatical category or highlight which parts of a medical report belong to a certain specialty. There are some popular ones like NER or POS-tagging.
record = rg.TokenClassificationRecord(
text = "Michael is a professor at Harvard",
tokens = ["Michael", "is", "a", "professor", "at", "Harvard"],
# Predictions are a list of tuples with all your token labels and their starting and ending positions
prediction = [('NAME', 0, 7), ('LOC', 26, 33)],
prediction_agent = "link or reference to agent",
# Annotations are a list of tuples with all your token labels and their starting and ending positions
annotation = [('NAME', 0, 7), ('ORG', 26, 33)],
annotation_agent = "link or reference to annotator",
metadata={ # Information about this record
"split": "train"
},
)
Text2Text#
Text2Text tasks, like text generation, are tasks where the model receives and outputs a sequence of tokens. Examples of such tasks are machine translation, text summarization, paraphrase generation, etc.
record = rg.Text2TextRecord(
text = "Michael is a professor at Harvard",
# The prediction is a list of texts or tuples if you want to add a score to a prediction
prediction = ["Michael es profesor en Harvard", "Michael es un profesor de Harvard"],
prediction_agent = "link or reference to agent",
# The annotation is a string representing the expected output text for the given input text
annotation = "Michael es profesor en Harvard"
)
Annotation#
An annotation is a piece of information assigned to a record, a label, token-level tags, or a set of labels, and typically by a human agent.
Prediction#
A prediction is a piece of information assigned to a record, a label or a set of labels and typically by a machine process.
Metadata#
Metadata will hold extra information that you want your record to have: if it belongs to the training or the test dataset, a quick fact about something regarding that specific record… Feel free to use it as you need!
Task#
A task defines the objective and shape of the predictions and annotations inside a record. You can see our supported tasks at tasks.
Settings#
For now, only a set of predefined labels (labels schema) is configurable. Still, other settings like annotators, and metadata schema, are planned to be supported as part of dataset settings.