🧼 Clean labels using your model’s loss#
In this tutorial, we will learn to introduce a simple technique for error analysis, using model loss to find potential training data errors.
🤗 This technique is shown using a fine-tuned text classifier from the Hugging Face Hub on the AG News dataset.
✅ Using Argilla, we will verify more than 50 mislabelled examples on the training set of this well-known NLP benchmark.
💥 This trick is useful for model training with small and noisy datasets.
👥 This trick is complementary with other “data-centric” ML methods such as
cleanlab(see this Argilla tutorial).
Introduction#
This tutorial explains a simple trick you can leverage with Argilla for finding potential errors in training data: using your model loss to identify label errors or ambiguous examples. This trick is not new (those who’ve worked with fastai know how useful the plot_top_losses method is). Even Andrej Karpathy tweeted about this some time ago:
When you sort your dataset descending by loss you are guaranteed to find something unexpected, strange and helpful.
— Andrej Karpathy (@karpathy) October 2, 2020
The technique is really simple: if you are training a model with a training set, train your model, and apply your model to the training set to compute the loss for each example in the training set. If you sort your dataset examples by loss, examples with the highest loss are the most ambiguous and difficult to learn.
This technique can be used for error analysis during model development (e.g., identifying tokenization problems), but it turns out is also a really simple technique for cleaning up your training data, during model development or after training data collection activities.
In this tutorial, we’ll use this technique with a well-known text classification benchmark, the AG News dataset. After computing the losses, we’ll use Argilla to analyse the highest loss examples. In less than 5 minutes, we manually check and relabel the first 50 examples. In fact, the first 50 examples with the highest loss, are all incorrect in the original training set. If we visually inspect further examples, we still find label errors in the top 500 examples.
Why it’s important#
Machine learning models are only as good as the data they’re trained on. Almost all training data sources can be considered “noisy” (e.g., crowd-workers, annotator errors, weak supervision sources, data augmentation, etc.)
With this simple technique we’re able to find more than 50 label errors on a widely-used benchmark in less than 5 minutes (your dataset will probably be noisier!).
With advanced model architectures widely available, managing, cleaning, and curating data is becoming a key step for making robust ML applications. A good summary of the current situation can be found on the website of the Data-centric AI NeurIPS Workshop.
This simple trick can be used across the whole ML lifecycle and not only for finding label errors. With this trick, you can improve data preprocessing, tokenization, and even your model architecture.
Running Argilla#
For this tutorial, you will need to have an Argilla server running. There are two main options for deploying and running Argilla:
Deploy Argilla on Hugging Face Spaces: If you want to run tutorials with external notebooks (e.g., Google Colab) and you have an account on Hugging Face, you can deploy Argilla on Spaces with a few clicks:

For details about configuring your deployment, check the official Hugging Face Hub guide.
Launch Argilla using Argilla’s quickstart Docker image: This is the recommended option if you want Argilla running on your local machine. Note that this option will only let you run the tutorial locally and not with an external notebook service.
For more information on deployment options, please check the Deployment section of the documentation.
Tip
This tutorial is a Jupyter Notebook. There are two options to run it:
Use the Open in Colab button at the top of this page. This option allows you to run the notebook directly on Google Colab. Don’t forget to change the runtime type to GPU for faster model training and inference.
Download the .ipynb file by clicking on the View source link at the top of the page. This option allows you to download the notebook and run it on your local machine or on a Jupyter Notebook tool of your choice.
[ ]:
%pip install argilla transformers datasets torch -qqq
Let’s import the Argilla module for reading and writing data:
[ ]:
import argilla as rg
If you are running Argilla using the Docker quickstart image or Hugging Face Spaces, you need to init the Argilla client with the URL and API_KEY:
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
# Replace workspace with the name of your workspace
rg.init(
api_url="http://localhost:6900",
api_key="owner.apikey",
workspace="admin"
)
If you’re running a private Hugging Face Space, you will also need to set the HF_TOKEN as follows:
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# # Replace workspace with the name of your workspace
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="owner.apikey",
# workspace="admin",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
Finally, let’s include the imports we need:
[ ]:
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from datasets import load_dataset, Dataset, Features, Value, ClassLabel
from transformers.data.data_collator import DataCollatorWithPadding
import pandas as pd
Enable Telemetry#
We gain valuable insights from how you interact with our tutorials. To improve ourselves in offering you the most suitable content, using the following lines of code will help us understand that this tutorial is serving you effectively. Though this is entirely anonymous, you can choose to skip this step if you prefer. For more info, please check out the Telemetry page.
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
Preliminaries#
A model fine-tuned with the AG News dataset (you could train your own model if you wish).
The AG News train split (the same trick could and should be applied to validation and test splits).
Argilla for logging, exploring, and relabeling wrong examples (we provide pre-computed datasets so feel free to skip to this step)
1. Load the fine-tuned model and the training dataset#
Now, we will load the AG News dataset. But first, we need to define and set the device, the model and the tokenizer:
[ ]:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("andi611/distilbert-base-uncased-ner-agnews")
model = AutoModelForSequenceClassification.from_pretrained(
"andi611/distilbert-base-uncased-ner-agnews"
)
model.to(device)
# Load the training split
ds = load_dataset("ag_news", split="train")
# Tokenize and encode the training set
def tokenize_and_encode(batch):
return tokenizer(batch["text"], truncation=True)
ds_enc = ds.map(tokenize_and_encode, batched=True)
2. Computing the loss#
The following code will compute the loss for each example using our trained model. This process is taken from the very well-explained blog post by Lewis Tunstall: “Using data collators for training and error analysis”, where he explains this process for error analysis during model training.
In our case, we instantiate a data collator directly, while he uses the Data Collator from the Trainer directly:
[ ]:
# Create the data collator for inference
data_collator = DataCollatorWithPadding(tokenizer, padding=True)
# Function to compute the loss example-wise
def loss_per_example(batch):
batch = data_collator(batch)
input_ids = torch.tensor(batch["input_ids"], device=device)
attention_mask = torch.tensor(batch["attention_mask"], device=device)
labels = torch.tensor(batch["labels"], device=device)
with torch.no_grad():
output = model(input_ids, attention_mask)
batch["predicted_label"] = torch.argmax(output.logits, axis=1)
# compute the probabilities for logging them into Argilla
batch["predicted_probas"] = torch.nn.functional.softmax(output.logits, dim=0)
# Don't reduce the loss (return the loss for each example)
loss = torch.nn.functional.cross_entropy(output.logits, labels, reduction="none")
batch["loss"] = loss
# Datasets complains with numpy dtypes, let's use Python lists
for k, v in batch.items():
batch[k] = v.cpu().numpy().tolist()
return batch
Now, it is time to turn the dataset into a Pandas dataframe and sort this dataset by descending loss:
Warning
Computing a model for this information is computationally intensive and might be slow if you don’t have a GPU. Even if you have a GPU, it could take around 5 minutes to compute this information for the full dataset. Try reducing the number of records in the dataset during load_dataset or using .select(range(number_of_record)).
[ ]:
losses_ds = ds_enc.remove_columns("text").map(
loss_per_example, batched=True, batch_size=32
)
# Turn the dataset into a Pandas dataframe, sort by descending loss and visualize the top examples.
pd.set_option("display.max_colwidth", None)
losses_ds.set_format("pandas")
losses_df = losses_ds[:][["label", "predicted_label", "loss", "predicted_probas"]]
# Add the text column removed by the trainer
losses_df["text"] = ds_enc["text"]
losses_df.sort_values("loss", ascending=False).head(10)
| label | predicted_label | loss | predicted_probas | text | |
|---|---|---|---|---|---|
| 44984 | 1 | 0 | 8.833023 | [0.06412869691848755, 7.090532017173246e-05, 0.00019675122166518122, 0.0002370826987316832] | Baghdad blasts kills at least 16 Insurgents have detonated two bombs near a convoy of US military vehicles in southern Baghdad, killing at least 16 people, Iraqi police say. |
| 101562 | 1 | 0 | 8.781285 | [0.12395327538251877, 9.289286026614718e-06, 0.0001785584754543379, 0.0007945793331600726] | Immoral, unjust, oppressive dictatorship. . . and then there #39;s <b>...</b> ROBERT MUGABES Government is pushing through legislation designed to prevent human rights organisations from operating in Zimbabwe. |
| 31564 | 1 | 2 | 8.772168 | [0.00016983140085358173, 8.863882612786256e-06, 0.18702593445777893, 0.00025946463574655354] | Ford to Cut 1,150 Jobs At British Jaguar Unit Ford Motor Co. announced Friday that it would eliminate 1,150 jobs in England to streamline its Jaguar Cars Ltd. unit, where weak sales have failed to offset spending on new products and other parts of the business. |
| 41247 | 1 | 0 | 8.751480 | [0.2929899990558624, 7.849136454751715e-05, 0.00034211069578304887, 4.463219011086039e-05] | Palestinian gunmen kidnap CNN producer GAZA CITY, Gaza Strip -- Palestinian gunmen abducted a CNN producer in Gaza City on Monday, the network said. The network said Riyadh Ali was taken away at gunpoint from a CNN van. |
| 44961 | 1 | 0 | 8.740394 | [0.06420651078224182, 7.788064249325544e-05, 0.0001824614155339077, 0.0002348265261389315] | Bomb Blasts in Baghdad Kill at Least 35, Wound 120 Insurgents detonated three car bombs near a US military convoy in southern Baghdad on Thursday, killing at least 35 people and wounding around 120, many of them children, officials and doctors said. |
| 75216 | 1 | 0 | 8.735966 | [0.13383473455905914, 1.837693343986757e-05, 0.00017987379396799952, 0.00036031895433552563] | Marine Wives Rally A group of Marine wives are running for the family of a Marine Corps officer who was killed in Iraq. |
| 31229 | 1 | 2 | 8.729340 | [5.088283069198951e-05, 2.4471093638567254e-05, 0.18256260454654694, 0.00033902408904396] | Auto Stocks Fall Despite Ford Outlook Despite a strong profit outlook from Ford Motor Co., shares of automotive stocks moved mostly lower Friday on concerns sales for the industry might not be as strong as previously expected. |
| 19737 | 3 | 1 | 8.545797 | [4.129256194573827e-05, 0.1872873306274414, 4.638762402464636e-05, 0.00010757221753010526] | Mladin Release From Road Atlanta Australia #39;s Mat Mladin completed a winning double at the penultimate round of this year #39;s American AMA Chevrolet Superbike Championship after taking |
| 60726 | 2 | 0 | 8.437369 | [0.5235446095466614, 4.4463453377829865e-05, 3.5171411582268775e-05, 8.480428368784487e-05] | Suicide Bombings Kill 10 in Green Zone Insurgents hand-carried explosives into the most fortified section of Baghdad Thursday and detonated them within seconds of each other, killing 10 people and wounding 20. |
| 28307 | 3 | 1 | 8.386065 | [0.00018589739920571446, 0.42903241515159607, 2.5073826691368595e-05, 3.97983385482803e-05] | Lightning Strike Injures 40 on Texas Field (AP) AP - About 40 players and coaches with the Grapeland High School football team in East Texas were injured, two of them critically, when lightning struck near their practice field Tuesday evening, authorities said. |
[2]:
# Save this to a file for further analysis
# losses_df.to_json("agnews_train_loss.json", orient="records", lines=True)
While using Pandas and Jupyter notebooks is useful for initial inspection, and programmatic analysis. If you want to quickly explore the examples, relabel them, and share them with other project members, Argilla provides you with a straightforward way to do this. Let’s see how.
3. Log high-loss examples into Argilla#
Using the amazing Hugging Face Hub we’ve shared the resulting dataset, which you can find here and load directly using the datasets library
Now, we log the first 500 examples into a Argilla dataset:
[ ]:
# If you have skipped the first two steps you can load the dataset here:
dataset = load_dataset("dvilasuero/ag_news_training_set_losses", split="train")
losses_df = dataset.to_pandas()
ds = load_dataset("ag_news", split="test") # only for getting the label names
[7]:
# Create a Text classification record for logging into Argilla
def make_record(row):
return rg.TextClassificationRecord(
text=row.text,
# This is the "gold" label in the original dataset
annotation=[(ds.features["label"].names[row.label])],
# This is the prediction together with its probability
prediction=[
(
ds.features["label"].names[row.predicted_label],
row.predicted_probas[row.predicted_label],
)
],
# Metadata fields can be used for sorting and filtering, here we log the loss
metadata={"loss": row.loss},
# Who makes the prediction
prediction_agent="andi611/distilbert-base-uncased-ner-agnews",
# Source of the gold label
annotation_agent="ag_news_benchmark",
)
# If you want to log the full dataset remove the indexing
top_losses = losses_df.sort_values("loss", ascending=False)[0:499]
# Build Argilla records
records = top_losses.apply(make_record, axis=1)
rg.log(records, name="ag_news_error_analysis")
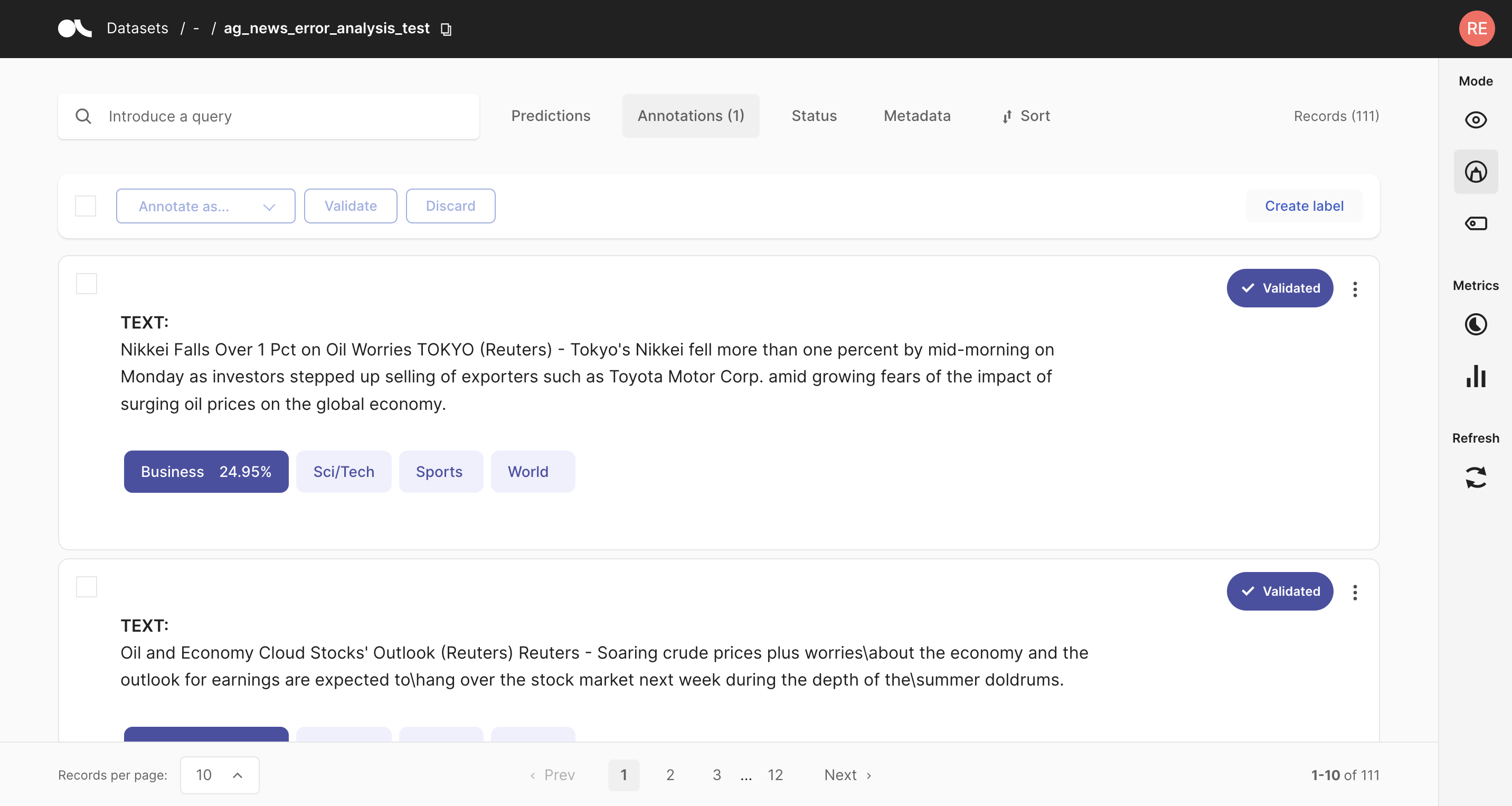
4. Using Argilla UI for inspection and relabeling#
In this step, we have an Argilla Dataset available for exploration and annotation. A useful feature for this use case is Sorting. With Argilla you can sort your examples by combining different fields, both from the standard fields (such as score) and custom fields (via the metadata fields). In this case, we’ve logged the loss so we can order our training examples by loss in descending order (showing higher loss examples first).
For preparing this tutorial, we have manually checked and relabelled the first 50 examples. Moreover, we’ve shared this re-annotated dataset in the Hugging Face Hub. In the next section, we show you how easy is to share Argilla Datasets in the Hub.
5. Sharing the dataset in the Hugging Face Hub#
Let’s first load the re-annotated examples. Re-labelled examples are marked as annotated_by the user argilla, which is the default user when launching Argilla with Docker. We can retrieve only these records using the query param as follows:
[11]:
dataset = rg.load("ag_news_error_analysis", query="annotated_by:argilla").to_pandas()
# Let's do some transformations before uploading the dataset
dataset["loss"] = dataset.metadata.transform(lambda r: r["loss"])
dataset = dataset.rename(columns={"annotation": "corrected_label"})
dataset.head()
[11]:
| inputs | prediction | corrected_label | prediction_agent | annotation_agent | multi_label | explanation | id | metadata | status | event_timestamp | metrics | text | loss | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | {'text': 'Top nuclear official briefs Majlis c... | [(World, 0.1832696944)] | World | andi611/distilbert-base-uncased-ner-agnews | argilla | False | None | 071a1014-71e7-41f4-83e4-553ba47610cf | {'loss': 7.6656146049} | Validated | None | {} | Top nuclear official briefs Majlis committee T... | 7.665615 |
| 1 | {'text': 'Fischer Delivers Strong Message in S... | [(World, 0.0695228428)] | World | andi611/distilbert-base-uncased-ner-agnews | argilla | False | None | 07c8c4f6-3288-46f4-a618-3da4a537e605 | {'loss': 7.9892320633} | Validated | None | {} | Fischer Delivers Strong Message in Syria Germa... | 7.989232 |
| 2 | {'text': 'The Politics of Time and Dispossessi... | [(Sci/Tech, 0.100481838)] | Sci/Tech | andi611/distilbert-base-uncased-ner-agnews | argilla | False | None | 0965a0d1-4886-432a-826a-58e99dfd9972 | {'loss': 7.133708477} | Validated | None | {} | The Politics of Time and Dispossession Make a ... | 7.133708 |
| 3 | {'text': 'Hadash Party joins prisoners #39; st... | [(World, 0.1749624908)] | World | andi611/distilbert-base-uncased-ner-agnews | argilla | False | None | 09fc7065-a2c8-4041-adf8-34e029a7fde0 | {'loss': 7.339015007} | Validated | None | {} | Hadash Party joins prisoners #39; strike for 2... | 7.339015 |
| 4 | {'text': 'China May Join \$10Bln Sakhalin-2 Ru... | [(Business, 0.1370282918)] | Business | andi611/distilbert-base-uncased-ner-agnews | argilla | False | None | 1ef97c49-2f0f-43be-9b28-80a291cb3b1d | {'loss': 7.321100235} | Validated | None | {} | China May Join \$10Bln Sakhalin-2 Russia said ... | 7.321100 |
[12]:
# Let's add the original dataset labels to share them together with the corrected ones
# We sort by ascending loss our corrected dataset
dataset = dataset.sort_values("loss", ascending=False)
# we add original labels in string form
id2label = list(dataset.corrected_label.unique())
original_labels = [id2label[i] for i in top_losses[0:50].label.values]
dataset["original_label"] = original_labels
Now let’s transform this into a Dataset and define the features schema:
[13]:
ds = dataset[["text", "corrected_label", "original_label"]].to_dict(orient="list")
hf_ds = Dataset.from_dict(
ds,
features=Features(
{
"text": Value("string"),
"corrected_label": ClassLabel(names=list(dataset.corrected_label.unique())),
"original_label": ClassLabel(names=list(dataset.corrected_label.unique())),
}
),
)
Uploading the dataset with the push_to_hub method is as easy as:
[ ]:
hf_ds.push_to_hub("argilla/ag_news_corrected_labels")
Now the dataset is publicly available at the Hub!
Summary#
In this tutorial, we learn to use the model loss to find label errors in your training data set. Argilla’s UI makes it easy to sort your data by loss, quickly browsing the dataset to correct label errors.