Ⓜ️ Finetuning LLMs as chat assistants: Supervised Finetuning on Mistral 7B#
In this tutorial, you will learn how to finetune a Large Language Model (LLM), Mistral 7B in particular, on a chat-style instruction dataset. We start with mistralai/Mistral-7B-v0.1, an LLM that only does text completion, and we end up with our own argilla/Mistral-7B-v0.1-chat-OIG model that faithfully follows instructions and acts as a helpful chat assistant.
This tutorial consists of the following steps: 1. Preparing a FeedbackDataset in Argilla. 2. (Optional) Annotate instruction samples. 3. Set up the ArgillaTrainer for Supervised Finetuning. 4. Perform inference using the finetuned LLM. 5. Publish the resulting model and dataset on the Hugging Face Hub.
For this tutorial, we used the p3.8xlarge AWS instance and trained for a total of 70 minutes. In terms of compute, training the Mistral chat model cost us less than $15.
Introduction#
Mistral 7B#
In this tutorial we will be finetuning Mistral 7B, which is a powerful LLM developed by the Mistral AI team featuring 7.3 billion parameters. It stands out for its exceptional performance relative to its size, outperforming larger models like Llama 2 13B and Llama 1 34B on various benchmarks.
Another key aspect is its ability to perform well for longer sequences, and noticeably, it is released under the permissive Apache 2.0 license. This allows it to be used in commercial use cases with no strings attached.
Running Argilla#
For this tutorial, you will need to have an Argilla server running. There are two main options for deploying and running Argilla:
Deploy Argilla on Hugging Face Spaces: If you want to run tutorials with external notebooks (e.g., Google Colab) and you have an account on Hugging Face, you can deploy Argilla on Spaces with a few clicks:

For details about configuring your deployment, check the official Hugging Face Hub guide.
Launch Argilla using Argilla’s quickstart Docker image: This is the recommended option if you want Argilla running on your local machine. Note that this option will only let you run the tutorial locally and not with an external notebook service.
For more information on deployment options, please check the Deployment section of the documentation.
Tip
This tutorial is a Jupyter Notebook. There are two options to run it:
Use the Open in Colab button at the top of this page. This option allows you to run the notebook directly on Google Colab. Don’t forget to change the runtime type to GPU for faster model training and inference.
Download the .ipynb file by clicking on the View source link at the top of the page. This option allows you to download the notebook and run it on your local machine or on a Jupyter notebook tool of your choice.
Install dependencies#
Let’s start by installing the required dependencies to run both Argilla and the remainder of this tutorial.
[ ]:
%pip install "argilla~=1.16.0" "transformers~=4.34.0" "datasets~=2.14.5" "peft~=0.5.0" "trl~=0.7.1" "wandb~=0.15.12"
Note that you must also install torch with CUDA support. The widget here should be helpful if torch is not already set up.
Let’s import the Argilla module for reading and writing data:
[1]:
import argilla as rg
If you are running Argilla using the Docker quickstart image or Hugging Face Spaces, you need to init the Argilla client with the URL and API_KEY:
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
rg.init(
api_url="http://localhost:6900",
api_key="owner.apikey",
workspace="admin"
)
If you’re running a private Hugging Face Space, you will also need to set the HF_TOKEN as follows:
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# # Replace workspace with the name of your workspace
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="owner.apikey",
# workspace="admin",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
Enable Telemetry#
We gain valuable insights from how you interact with our tutorials. To improve ourselves in offering you the most suitable content, using the following lines of code will help us understand that this tutorial is serving you effectively. Though this is entirely anonymous, you can choose to skip this step if you prefer. For more info, please check out the Telemetry page.
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
Preparing a FeedbackDataset in Argilla#
In Argilla, the FeedbackDataset is a powerful and widely-configurable class that is in charge of defining the annotation process. In particular, we define fields and questions.
The former is in charge of defining the structure for the data that will be annotated, while the latter determines in what way the annotators can annotate the data. In practice, FeedbackDataset instances for finetuning LLMs often have “prompt” and “response” text fields, sometimes alongside a “context” text field or some additional metadata (e.g. sample IDs).
The questions provide a lot of flexibility - text questions allow annotators to provide better responses or suggestions to improve the prompt, while label questions may be used to select if a sample is considered “good” or not. With multi-label questions annotators can select whether samples are biased, harmful, incorrect, etc.
We recommend to set up the questions based on your goals and values for the annotation process. When preparing the training data, all of the annotations will be available, allowing you to carefully curate your training data. For example, based on your annotations you will be able to disregard samples that are (frequently) marked as harmful or low quality, or you can use the annotator-provided suggestions to responses or prompts instead of the existing ones. Furthermore, in some situations you may only have prompts to begin with, and you can use Argilla to request your annotators to provide responses. You can then use these in your training data.
For this tutorial#
For the purposes of this tutorial, we will use a “prompt” field with all chat history and the current prompt, as well as a “response” field with the response. Additionally, we introduce a “background” text field, which is sometimes used to provide additional background information prior to the user prompt. An example data sample is shown a few cells below, to help clarify what the background entails. For the questions we will use one simple LabelQuestion that asks the annotator whether the
response is "Good" or "Bad".
[5]:
dataset = rg.FeedbackDataset(
fields = [
rg.TextField(name="background"),
rg.TextField(name="prompt"),
rg.TextField(name="response", title="Final Response"),
],
questions = [
rg.LabelQuestion(name="quality", title="Is it a Good or Bad response?", labels=["Good", "Bad"])
]
)
Once created, we have to create individual records and push those to the dataset. For this tutorial, we will use some existing Apache-2.0 data from the Open Instruction Generalist chat-style instruction dataset. Due to the large size of this dataset, we will load the dataset with streaming=True, and semi-randomly sample 30k samples from this dataset.
[ ]:
from datasets import load_dataset
data = load_dataset("laion/OIG", split="train", streaming=True)
# Randomly sample through shuffle + take, but note that shuffling with a streaming
# dataset works with a buffer size, so the random 30k samples are not truly random
# Reduce the buffer size to speed up the data selection process.
data = data.shuffle(buffer_size=1_000_000).take(30_000)
The loaded data has a “text” column with data that looks like so:
Background: Tubulin in molecular biology can refer either to the tubulin protein superfamily of globular proteins, or one of the member proteins of that superfamily. α- and β-tubulins polymerize into microtubules, a major component of the eukaryotic cytoskeleton. Microtubules function in many essential cellular processes, including mitosis. Tubulin-binding drugs kill cancerous cells by inhibiting microtubule dynamics, which are required for DNA segregation and therefore cell division. , there are six members of the tubulin superfamily, although not all are present in all species. Both α and β tubulins have a mass of around 50 kDa and are thus in a similar range compared to actin (with a mass of ~42 kDa). In contrast, tubulin polymers (microtubules) tend to be much bigger than actin filaments due to their cylindrical nature. Tubulin was long thought to be specific to eukaryotes. More recently, however, several prokaryotic proteins have been shown to be related to tubulin. <human>: What are some examples of drugs that bind to tubulin? <bot>: These include paclitaxel, colchicine, and the "vinca" alkaloids, each of which have a distinct binding site on β-tubulin. <human>: Are there any other examples? <bot>: In addition, the anti-worm drug albendazole selectively targets the colchicine site in worm, but not human or "Drosophilia", β-Tubulin. <human>: What is another specific example of a drug that binds to tubulin? <bot>: Class III β-tubulin is a microtubule element expressed exclusively in neurons, and is a popular identifier specific for neurons in nervous tissue. <human>: What is the difference between class III and other isotypes? <bot>: It binds colchicine much more slowly than other isotypes of β-tubulin. <human>: Are there six classes of isotypes? <bot>: β1-tubulin, sometimes called class VI β-tubulin, is the most divergent at the amino acid sequence level. <human>: What are the functions of the different isotypes? <bot>: It is expressed exclusively in megakaryocytes and platelets in humans and appears to play an important role in the formation of platelets.
Let’s break this down: - The text uses <human>: and <bot>: to denote the start of the user-provided and generated texts, respectively. - The text uses Background: to denote some additional context that is relevant for the chat. Not all samples contain any background. - The dataset contains multi-step chat-style instructions.
To fit this in our FeedbackDataset, we have to split this up into a “background”, a “prompt” with all chat history and the last prompt, and the final “response”.
[ ]:
from typing import Dict, Any
def extract_background_prompt_response(text: str) -> Dict[str, Any]:
'''Extract the anthropic prompt from a prompt and response pair.'''
start_prompt = text.find("<human>:")
end_prompt = text.rfind("<bot>:")
# Background is anything before the first <human>:
background = text[:start_prompt].strip()
# Prompt is anything between the first <human>: (inclusive) and the last <bot>: (exclusive)
prompt = text[start_prompt: end_prompt].strip()
# Response is everything after the last <bot>: (inclusive)
response = text[end_prompt:].strip()
return {"background": background, "prompt": prompt, "response": response}
data = data.map(extract_background_prompt_response, input_columns="text")
Now we can trivially convert this dataset into FeedbackRecord instances, and add them to the dataset.
[ ]:
records = [
rg.FeedbackRecord(
fields={
"background": sample["background"],
"prompt": sample["prompt"],
"response": sample["response"],
},
)
for sample in data
]
dataset.add_records(records)
Now that we have all the records locally, we want to push them to the Argilla server as well. Only then will we be able to see them in the Argilla UI.
[ ]:
dataset.push_to_argilla("oig-30k")
Once pushed, we can always load this data again using load_from_argilla:
[ ]:
dataset = rg.FeedbackDataset.from_argilla("oig-30k")
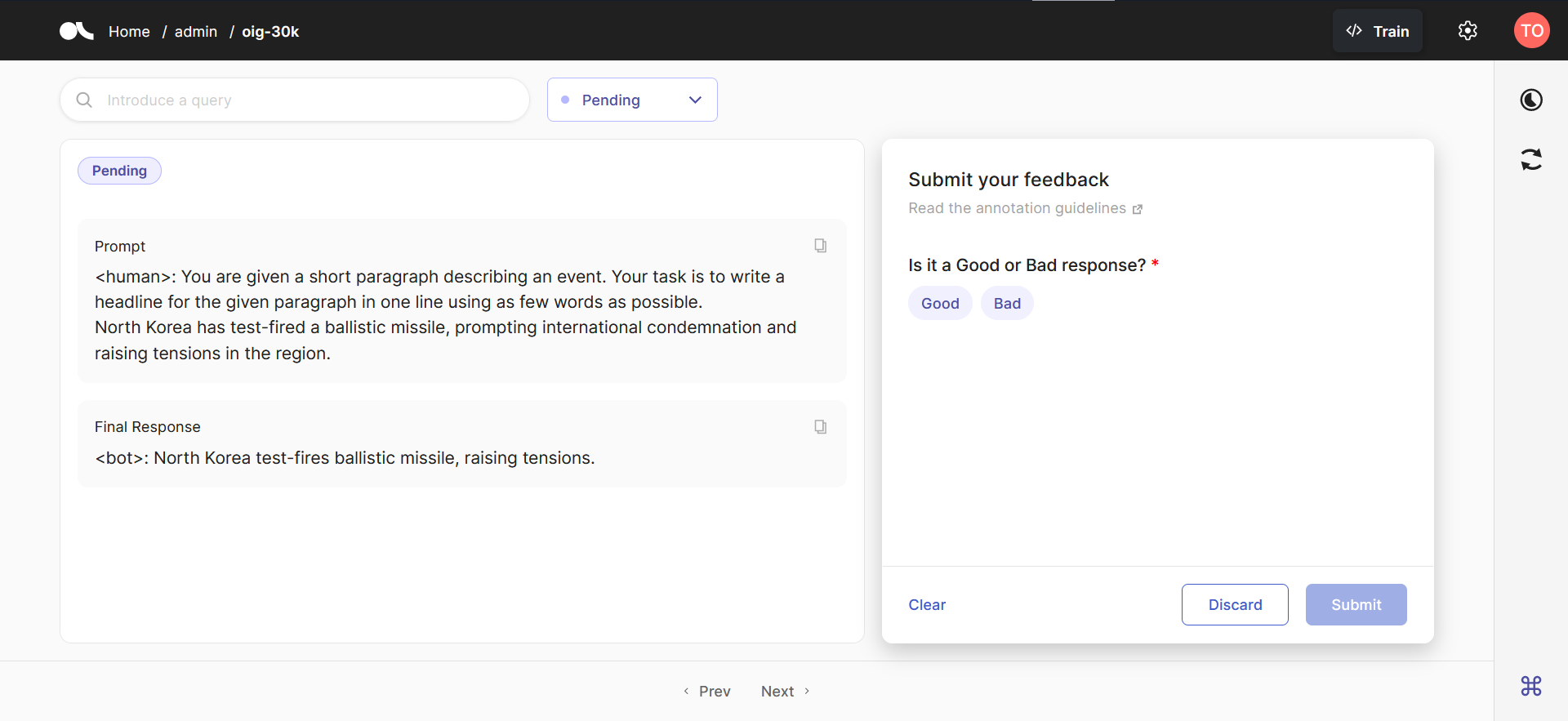
(Optional) Annotate instruction samples#
If you are using your own proprietary data, data from an unreliable source, or require on your annotators to provide responses, then you must perform data annotation. However, for the purposes of this tutorial, we will assume that all data is high quality and skip this step. See the data collection for LLMs documentation for additional information on this phase.
Set up the ArgillaTrainer for Supervised Finetuning#
Model & Tokenizer#
Next, we have to set up the ArgillaTrainer. First off, we will load the Mistral 7B model and tokenizer. We’ll load the model using float16 to improve the memory usage and efficiency, and device_map="auto" automatically picks the best device to load the model on. For example, this will prioritize your GPU before your CPU.
Furthermore, setting the pad_token_id to eos_token_id is required for open-end generation. If you don’t define pad_token_id, it is often set to eos_token_id already, but you will be given warnings that you should do it yourself.
[ ]:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "mistralai/Mistral-7B-v0.1"
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float16, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
Training Task#
Next, we can set up the TrainingTask for supervised finetuning. This task requires a formatting_func that formats the data from Argilla in preparation for training. This formatting function first checks if the data quality is up to par. This is done by inspecting the annotations and checking if a sample was not annotated, annotated as “Bad” or discarded. For the purposes of the tutorial, I’ll ignore this
part and consider all data to be high quality.
Then, we convert the data to our desired chat format, where each step consists of:
<s><human>: {prompt} <bot>: {response}</s>
or
Background: {background} <s><human>: {prompt} <bot>: {response}</s>
In this format, <s> and </s> are the BOS and EOS tokens of the LLM. If a different model is being finetuned, then these tokens must be changed to the correct BOS and EOS tokens. When dealing with multiple sequential steps, the chat is formatted like so:
<s><human>: {prompt_1} <bot>: {response_1}</s><s><human>: {prompt_2} <bot>: {response_2}</s><s><human>: {prompt_3} <bot>: {response_3}</s>
When generating, we can supply the LLM with the following format:
<s><human>: {prompt_1} <bot>: {response_1}</s><s><human>: {prompt_2} <bot>:
and the model will generate the assistant response given the history, followed by </s>. The generation will naturally stop at this EOS marker. If the user chooses to respond again, then we can again add <s><human>: {prompt} <bot>: to the prior outputs and generate some more responses.
Note that the OIG data itself does not contain these BOS and EOS markers, so we need to add them manually between each of the prompt-response pairs.
[14]:
from typing import Dict, Iterator, Any
from argilla.feedback import TrainingTask
ANNOTATED_ONLY = False
def formatting_func(sample: Dict[str, Any]) -> Iterator[str]:
if ANNOTATED_ONLY:
# Discard if there are no annotations...
if not sample["quality"]:
return
# or if it is annotated as "Bad" or discarded.
first_annotation = sample["quality"][0]
if first_annotation["value"] == "Bad" or first_annotation["status"] == "discarded":
return
# Filter out responses that are likely low quality
if len(sample["response"]) <= 2:
return
# Add </s><s> between all prompt-response pairs
prompt = sample["prompt"]
prompt = prompt.replace("<human>:", f"{tokenizer.eos_token}{tokenizer.bos_token}<human>:")
prompt = prompt[prompt.find("<human>:"):]
# Add response and optionally the background to the full text.
output = prompt + " " + sample["response"]
if sample["background"]:
output = sample["background"] + " " + output
output = output + tokenizer.eos_token
# We expect one less <s> than </s>, because the Mistral tokenizer will automatically add the BOS
# at the start of the text when this text is tokenized. When that's done, the format will be exactly
# what we want
assert output.count("<s>") + 1 == output.count("</s>")
return output
task = TrainingTask.for_supervised_fine_tuning(formatting_func)
Often times it’ll be convenient to have a manual look at the data before we start the training, just to verify that the data is indeed correctly formatted. Luckily, Argilla implements a method to apply the TrainingTask over a FeedbackDataset for a specific training framework, and you’ll get the training data just like how that particular framework wants to have it.
[15]:
formatted_dataset = dataset.prepare_for_training(framework="trl", task=task)
formatted_dataset
[15]:
Dataset({
features: ['id', 'text'],
num_rows: 23806
})
[42]:
print(formatted_dataset[80]["text"])
<human>: The neopositivists subscribed to a notion of philosophy as the conceptual clarification of the methods, insights and discoveries of the sciences. They saw in the logical symbolism elaborated by Frege (1848–1925) and Bertrand Russell (1872–1970) a powerful instrument that could rationally reconstruct all scientific discourse into an ideal, logically perfect, language that would be free of the ambiguities and deformations of natural language. This gave rise to what they saw as metaphysical pseudoproblems and other conceptual confusions. By combining Frege's thesis that all mathematical truths are logical with the early Wittgenstein's idea that all logical truths are mere linguistic tautologies, they arrived at a twofold classification of all propositions: the analytic (a priori) and the synthetic (a posteriori). On this basis, they formulated a strong principle of demarcation between sentences that have sense and those that do not: the so-called verification principle. Any sentence that is not purely logical, or is unverifiable is devoid of meaning. As a result, most metaphysical, ethical, aesthetic and other traditional philosophical problems came to be considered pseudoproblems.
When was Bertrand Russell born?
<bot>: 1872
</s><s><human>: When did Bertrand Russell die?
<bot>: 1970
</s><s><human>: What did Frege say about math?
<bot>: all mathematical truths are logical
</s><s><human>: What did Wittgenstein say about logic?
<bot>: all logical truths are mere linguistic tautologies
</s><s><human>: What are pseudoproblems?
<bot>: most metaphysical, ethical, aesthetic and other traditional philosophical problems
</s><s><human>: When was Frege's thesis published?
<bot>: Sorry, I cannot find a relevant answer in the given context.
</s><s><human>: When was Wittgenstein born?
<bot>: Sorry, I cannot find a relevant answer in the given context.
</s><s><human>: When did Wittgenstein die?
<bot>: Sorry, I cannot find a relevant answer in the given context.
</s><s><human>: Who was a neopositivist?
<bot>: Sorry, I cannot find a relevant answer in the given context.
</s><s><human>: What gave a sentence meaning? <bot>: Sorry, I cannot find a relevant answer in the given context.</s>
This seems to match our desired format exactly!
Data Collation#
When training LLMs, we want to verify that the text is tokenized and collated correctly. In particular, the data collation can be quite important, as some data collators will replace all special tokens (e.g. padding, BOS and EOS tokens) with a label of -100, which is the label that is ignored during training. If this is the case, then the model will not learn to produce the EOS token. Consequently, the model will always respond with endless tokens - far from ideal.
By default, models trained with supervised finetuning use the DataCollatorForLanguageModeling data collator, so let’s experiment:
[49]:
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(tokenizer, mlm=False)
data_collator([tokenizer(formatted_dataset[0]["text"])])
[49]:
{'input_ids': tensor([[ 1, 523, 18529, 9670, 12628, 272, 2296, 808, 302, 11382,
28725, 3133, 8373, 28747, 5936, 16280, 4969, 1059, 9697, 438,
1830, 647, 464, 20746, 18566, 9917, 3578, 1996, 378, 533,
5446, 28705, 28770, 2421, 647, 464, 1733, 824, 2516, 9746,
7230, 5573, 10487, 3578, 1421, 2063, 4372, 272, 2996, 464,
5985, 272, 2078, 5944, 297, 1745, 3725, 395, 264, 464,
5613, 28742, 442, 464, 2501, 4135, 523, 10093, 9670, 1770,
2]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]), 'labels': tensor([[ 1, 523, 18529, 9670, 12628, 272, 2296, 808, 302, 11382,
28725, 3133, 8373, 28747, 5936, 16280, 4969, 1059, 9697, 438,
1830, 647, 464, 20746, 18566, 9917, 3578, 1996, 378, 533,
5446, 28705, 28770, 2421, 647, 464, 1733, 824, 2516, 9746,
7230, 5573, 10487, 3578, 1421, 2063, 4372, 272, 2996, 464,
5985, 272, 2078, 5944, 297, 1745, 3725, 395, 264, 464,
5613, 28742, 442, 464, 2501, 4135, 523, 10093, 9670, 1770,
-100]])}
As you can see, the final EOS is indeed set to -100, meaning that it would not be learned. Instead, we will create a custom data collator that directly copies the input_ids to the labels. This is trivial by subclassing the `DataCollatorForSeq2Seq <https://huggingface.co/docs/transformers/main_classes/data_collator#transformers.DataCollatorForSeq2Seq>`__ class.
[51]:
from transformers import DataCollatorForSeq2Seq, BatchEncoding
class DataCollatorForSeq2SeqCopyLabels(DataCollatorForSeq2Seq):
def __call__(self, features, return_tensors=None) -> BatchEncoding:
for feature in features:
if "labels" not in feature:
feature["labels"] = feature["input_ids"].copy()
return super().__call__(features, return_tensors=return_tensors)
[52]:
data_collator = DataCollatorForSeq2SeqCopyLabels(tokenizer)
data_collator([tokenizer(formatted_dataset[0]["text"])])
[52]:
{'input_ids': tensor([[ 1, 523, 18529, 9670, 12628, 272, 2296, 808, 302, 11382,
28725, 3133, 8373, 28747, 5936, 16280, 4969, 1059, 9697, 438,
1830, 647, 464, 20746, 18566, 9917, 3578, 1996, 378, 533,
5446, 28705, 28770, 2421, 647, 464, 1733, 824, 2516, 9746,
7230, 5573, 10487, 3578, 1421, 2063, 4372, 272, 2996, 464,
5985, 272, 2078, 5944, 297, 1745, 3725, 395, 264, 464,
5613, 28742, 442, 464, 2501, 4135, 523, 10093, 9670, 1770,
2]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]), 'labels': tensor([[ 1, 523, 18529, 9670, 12628, 272, 2296, 808, 302, 11382,
28725, 3133, 8373, 28747, 5936, 16280, 4969, 1059, 9697, 438,
1830, 647, 464, 20746, 18566, 9917, 3578, 1996, 378, 533,
5446, 28705, 28770, 2421, 647, 464, 1733, 824, 2516, 9746,
7230, 5573, 10487, 3578, 1421, 2063, 4372, 272, 2996, 464,
5985, 272, 2078, 5944, 297, 1745, 3725, 395, 264, 464,
5613, 28742, 442, 464, 2501, 4135, 523, 10093, 9670, 1770,
2]])}
Now we see 2 at the very end of labels, i.e. the EOS token, just like we want!
Generation Callback#
When training LLMs, it’s always recommended to perform some form of generation during training. This is crucial as the loss alone is not a good indicator of model performance, and it is the primary method to gauge if the model is going in the right direction and learning like expected. For this purpose, we will create a callback that generates some text and prints it out on every evaluation.
[53]:
from typing import Optional
import torch
from transformers import TrainerCallback, TrainerControl, TrainerState, GenerationConfig, TrainingArguments, PreTrainedModel, PreTrainedTokenizer
class GenerationCallback(TrainerCallback):
def __init__(self, prompt: str) -> None:
super().__init__()
self.prompt = prompt
def on_evaluate(self, args: TrainingArguments, state: TrainerState, control: TrainerControl, model: Optional[PreTrainedModel] = None, tokenizer: Optional[PreTrainedTokenizer] = None, **kwargs):
# Tokenize the prompt and send it to the right device
inputs = tokenizer(self.prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(
**inputs,
generation_config=GenerationConfig(
max_new_tokens=50,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
),
)
print(tokenizer.batch_decode(outputs, skip_special_tokens=False)[0])
generation_callback = GenerationCallback("<human>: What were Nelson Mandela's relations with the ANC? <bot>:")
ArgillaTrainer & hyperparameters#
Next, we can initialize the ArgillaTrainer! We have already prepared all of the components that it requires.
[ ]:
from argilla.feedback import ArgillaTrainer
trainer = ArgillaTrainer(
dataset=dataset,
model=model,
tokenizer=tokenizer,
task=task,
framework="trl",
train_size=0.99,
)
The next step is to configure the trainer with the desired arguments settings for training. We will start with configuration options for the TRL SFTTrainer. This trainer accepts a PEFT config, allowing us to use the awesome LoRA. This technique accelerates the fine-tuning of large models while consuming less memory. Upon training,
this will produce small adapter_config.json and adapter_model.bin files, which can be combined with the original model to produce the finetuned model. See this documentation for information on how to load these models again.
We also set the maximum sequence length to 1024 as a way to keep the memory usage down, and we provide the trainer with our custom data_collator and generation_callback.
[ ]:
from peft import LoraConfig, TaskType
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=8,
lora_alpha=16,
lora_dropout=0.05,
target_modules=["q_proj", "v_proj"],
)
trainer.update_config(
data_collator=data_collator,
callbacks=[generation_callback],
peft_config=peft_config,
max_seq_length=1024,
)
Beyond that, we want to configure the TrainingArguments to set the hyperparameters. Note that we only train with 3000 steps here. This already proved sufficient to finetune a reasonable model that follows our chat format.
[ ]:
trainer.update_config(
per_device_train_batch_size=3,
per_device_eval_batch_size=3,
eval_accumulation_steps=16,
max_steps=3000,
logging_steps=50,
learning_rate=5e-5,
save_strategy="no",
evaluation_strategy="steps",
eval_steps=500,
lr_scheduler_type="cosine",
warmup_ratio=0.1,
remove_unused_columns=False,
fp16=True,
num_train_epochs=1,
)
Then, all that remains is training the model. We provide an output directory for where the adapter files are saved.
[ ]:
trainer.train("Mistral-7B-v0.1-chat-OIG-3k")
Perform inference using the finetuned LLM#
After training, the model is still in memory as model, but often, times we will want to load the trained model anew. This is simple using AutoPeftModelForCausalLM:
[1]:
from transformers import AutoTokenizer
from peft import AutoPeftModelForCausalLM
import torch
model_path = "Mistral-7B-v0.1-chat-OIG-3k"
model = AutoPeftModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
Loading checkpoint shards: 100%|██████████| 2/2 [00:08<00:00, 4.14s/it]
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
At this point, inference becomes simple too. See the generate() method for more information.
[5]:
text = "<human>: What were Nelson Mandela's relations with the ANC? <bot>:"
inputs = tokenizer(text, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=250, pad_token_id=tokenizer.pad_token_id)
print(tokenizer.batch_decode(outputs, skip_special_tokens=False)[0])
<s> <human>: What were Nelson Mandela's relations with the ANC? <bot>: Nelson Mandela was a member of the ANC.</s>
[7]:
text = "<human>: What were Nelson Mandela's relations with the ANC? <bot>: Nelson Mandela was a member of the ANC.</s><s><human>: How old was he when he joined? <bot>: "
inputs = tokenizer(text, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=250, pad_token_id=tokenizer.pad_token_id)
print(tokenizer.batch_decode(outputs, skip_special_tokens=False)[0])
<s> <human>: What were Nelson Mandela's relations with the ANC? <bot>: Nelson Mandela was a member of the ANC.</s><s> <human>: How old was he when he joined? <bot>: 22</s>
Publish the resulting model and dataset on the Hugging Face Hub#
Lastly, we will want to save our trained model and the dataset to the Hugging Face Hub, even privately. Let’s start with the adapter model:
[ ]:
model_id = "argilla/Mistral-7B-v0.1-chat-OIG"
model.push_to_hub(model_id, private=True)
tokenizer.push_to_hub(model_id)
This resulted in the argilla/Mistral-7B-v0.1-chat-OIG on the Hub. We can save the dataset to the Hub like so:
[ ]:
dataset = rg.FeedbackDataset.from_argilla("oig-30k", workspace="admin")
dataset.push_to_huggingface("argilla/oig-30k", private=True)
Which created the argilla/oig-30k repository.
Performing inference with our published model#
If you’d like to try out the model that we trained for this tutorial, then you can run the following snippets to load the Adapter files from the Hugging Face Hub and try out your own prompts. These cells below can be ran completely separate from the remainder of the tutorial.
[ ]:
from transformers import AutoTokenizer
from peft import AutoPeftModelForCausalLM
import torch
model_path = "argilla/Mistral-7B-v0.1-chat-OIG"
model = AutoPeftModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
Feel free to experiment with various different prompts here:
[ ]:
prompt = "<human>: Finish this sequence: purple, red, orange, yellow, ... <bot>: "
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"], max_new_tokens=250, pad_token_id=tokenizer.pad_token_id)
print(tokenizer.batch_decode(outputs, skip_special_tokens=False)[0])
Conclusion#
To conclude, we have learned how to use the ArgillaTrainer to apply Supervised Finetuning via TRL to Mistral-7B to create a chat-style assistant model.
If you’re interested in finetuning LLMs, be sure to also check out these pages: