🔎 Filter and query datasets#
Feedback Dataset#
Note
The dataset class covered in this section is the FeedbackDataset. This fully configurable dataset will replace the DatasetForTextClassification, DatasetForTokenClassification, and DatasetForText2Text in Argilla 2.0. Not sure which dataset to use? Check out our section on choosing a dataset.
Filter#
From Argilla 1.15.0, the filter_by method has been included for the FeedbackDatasets pushed to Argilla, which allows you to filter the records in a dataset based on the response_status of the annotations of the records. So on, to be able to use the filter_by method, you will need to make sure that you are using a FeedbackDataset in Argilla.
Warning
The filter_by method returns a new instance which is a FeedbackDataset with the filtered records and synced with Argilla, which means that you will just have access to the records that are compliant with the applied filter. So calling filter_by will return a FeedbackDataset with a subset of the records, but the records won’t be modified unless updates or deletions are specifically applied at record-level. So on, the following methods are not allowed: delete, delete_records, add_records, records.add, and records.delete; while you’ll still be able to perform record-level operations such as update or delete.
By fields content#
In the UI, you can filter records based on their content using the searchbar in the top left corner on top of the record card. For example, you may read or annotate all records mentioning John Wick by simply typing “John Wick” in the searchbar.
By metadata property#
In the UI, you will find a metadata filter that lets you easily set a combination of filters based on the metadata properties defined for your dataset.
Note
Note that if a metadata property was set to visible_for_annotators=False this metadata property will only appear in the metadata filter for users with the admin or owner role.
In the Python SDK, you can also filter the records using one or a combination of metadata filters for the metadata properties defined in your dataset. Depending on the type of metadata you want to filter by, you will need to choose one of the following: IntegerMetadataFilter, FloatMetadataFilter or TermsMetadataFilter.
These are the arguments that you will need to define for your filter:
name: The name of the metadata property you want to filter by.ge: In anIntegerMetadataFilterorFloatMetadataFilter, match values greater than or equal to the provided value. At least one ofgeorleshould be provided.le: In anIntegerMetadataFilterorFloatMetadataFilter, match values lower than or equal to the provided value. At least one ofgeorleshould be provided.values: In aTermsMetadataFilter, returns records with at least one of the values provided.
import argilla as rg
rg.init(api_url="<ARGILLA_API_URL>", api_key="<ARGILLA_API_KEY>")
dataset = rg.FeedbackDataset.from_argilla(name="my-dataset", workspace="my-workspace")
filtered_records = dataset.filter_by(
metadata_filters=[
rg.IntegerMetadataFilter(
name="tokens-length",
ge=900, # at least one of ge or le should be provided
le=1000
),
rg.TermsMetadataFilter(
name="task",
values=["summarization", "information-extraction"]
)
]
)
By response#
Within the UI filters, you can filter records according to the value of responses given by the current user.
Note
This is available for responses to questions of the following types: LabelQuestion, MultiLabelQuestion and RatingQuestion.
By suggestion#
In the Argilla UI, you can filter your records based on suggestions. When these are available, it is possible to filter by suggestion score, value and agent.
Note
This is available for suggestions to questions of the following types: LabelQuestion, MultiLabelQuestion and RatingQuestion.
By status#
In the UI, you can find a status selector that will let you choose a queue of records depending on the status of responses given by the current user. Here you can choose to see records with Pending, Discarded or Submitted responses.
In the Python SDK, the filter_by method allows you to filter the records in a dataset based on the response_status of the responses given by all users. The response_status of an annotation can be one of the following:
pending: The records with this status have no responses. In the UI, they will appear under thePendingqueue.draft: The records with this status have responses that have been saved as a draft, not yet submitted or discarded. In the UI, they will appear under theDraftqueue.discarded: The records with this status may or may not have responses but have been discarded by the annotator. In the UI, they will appear under theDiscardedqueue.submitted: The records with this status have responses already submitted by the annotator. In the UI, they will appear under theSubmittedqueue.
Note
From Argilla 1.14.0, calling from_argilla will pull the FeedbackDataset from Argilla, but the instance will be remote, which implies that the additions, updates, and deletions of records will be pushed to Argilla as soon as they are made. This is a change from previous versions of Argilla, where you had to call push_to_argilla again to push the changes to Argilla.
You can either filter the records by a single status or by a list of statuses.
For example, to filter the records by the status “submitted”, you can do the following:
import argilla as rg
rg.init(api_url="<ARGILLA_API_URL>", api_key="<ARGILLA_API_KEY>")
dataset = rg.FeedbackDataset.from_argilla(name="my-dataset", workspace="my-workspace")
filtered_dataset = dataset.filter_by(response_status="submitted")
To filter the records by a list of statuses, you can do the following:
import argilla as rg
rg.init(api_url="<ARGILLA_API_URL>", api_key="<ARGILLA_API_KEY>")
dataset = rg.FeedbackDataset.from_argilla(name="my-dataset", workspace="my-workspace")
filtered_dataset = dataset.filter_by(response_status=["submitted", "draft"])
Sort#
You may also order your records according to one or several attributes, including insertion and last update time, suggestion scores, response and suggestion values for Rating questions and metadata properties. In the UI, you can easily do this using the Sort menu.
In the Python SDK, you can do this sorting with the sort_by method using the following arguments:
field: This refers to the information that will be used for the sorting. This can be the time when a record was created (created_at), last updated (updated_at) or any metadata properties configured for your dataset (metadata.my-metadata-name).order: Whether the order should be ascending (asc) or descending (des).
sorted_records = remote.sort_by(
[
SortBy(field="metadata.my-metadata", order="asc"),
SortBy(field="updated_at", order="des"),
]
)
Tip
You can also combine filters and sorting: dataset.filter_by(...).sort_by(...)
Semantic search#
In Feedback datasets, you can also retrieve records based on their similarity with another record. To do that, make sure you have added vector_settings to your dataset configuration and that your records include vectors.
In the UI, go to the record you’d like to use for the semantic search and click on Find similar at the top right corner of the record card. If there is more than one vector, you will be asked to select which vector to use. You can also select whether you want the most or least similar records and the number of results you would like to see.
At any time, you can expand or collapse the record that was used for the search as a reference. If you want to undo the search, just click on the cross next to the reference record.
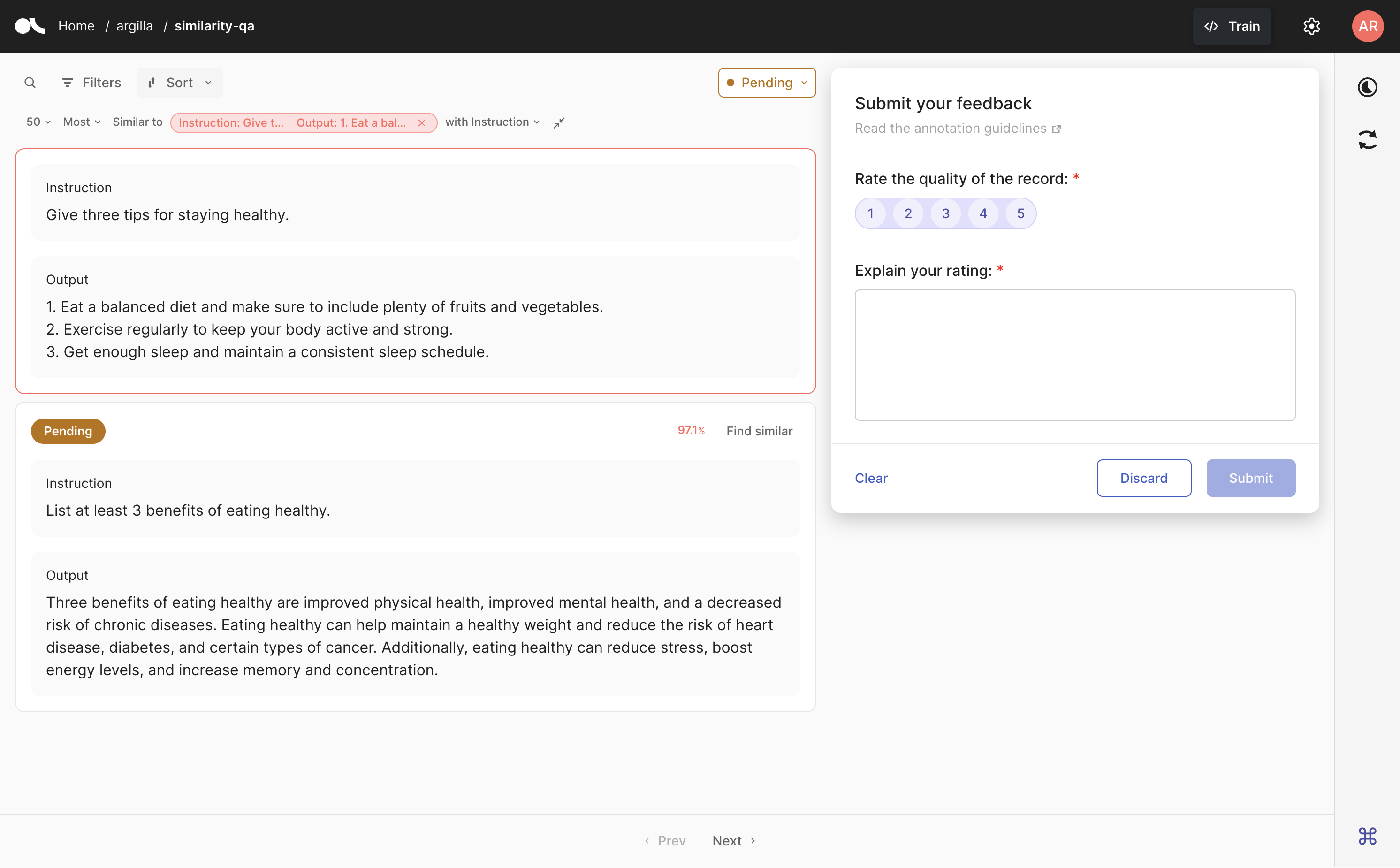
In the Python SDK, you can also get a list of feedback records that are semantically close to a given embedding with the find_similar_records method. These are the arguments of this function:
vector_name: Thenameof the vector to use in the search.value: A vector to use for the similarity search in the form of aList[float]. It is necessary to include avalueor arecord.record: AFeedbackRecordto use as part of the search. It is necessary to include avalueor arecord.max_results(optional): The maximum number of results for this search. The default is50.
This returns a list of Tuples with the records and their similarity score (between 0 and 1).
ds = rg.FeedbackDataset.from_argilla("my_dataset", workspace="my_workspace")
# using text embeddings
similar_records = ds.find_similar_records(
vector_name="my_vector",
value=embedder_model.embeddings("My text is here")
# value=embedder_model.embeddings("My text is here").tolist() # for numpy arrays
)
# using another record
similar_records = ds.find_similar_records(
vector_name="my_vector",
record=ds.records[0],
max_results=5
)
# work with the resulting tuples
for record, score in similar_records:
...
You can also combine filters and semantic search like this:
similar_records = (dataset
.filter_by(metadata=[rg.TermsMetadataFilter(values=["Positive"])])
.find_similar_records(vector_name="vector", value=model.encode("Another text").tolist())
)
Other datasets#
Note
The records classes covered in this section correspond to three datasets: DatasetForTextClassification, DatasetForTokenClassification, and DatasetForText2Text. These will be deprecated in Argilla 2.0 and replaced by the fully configurable FeedbackDataset class. Not sure which dataset to use? Check out our section on choosing a dataset.
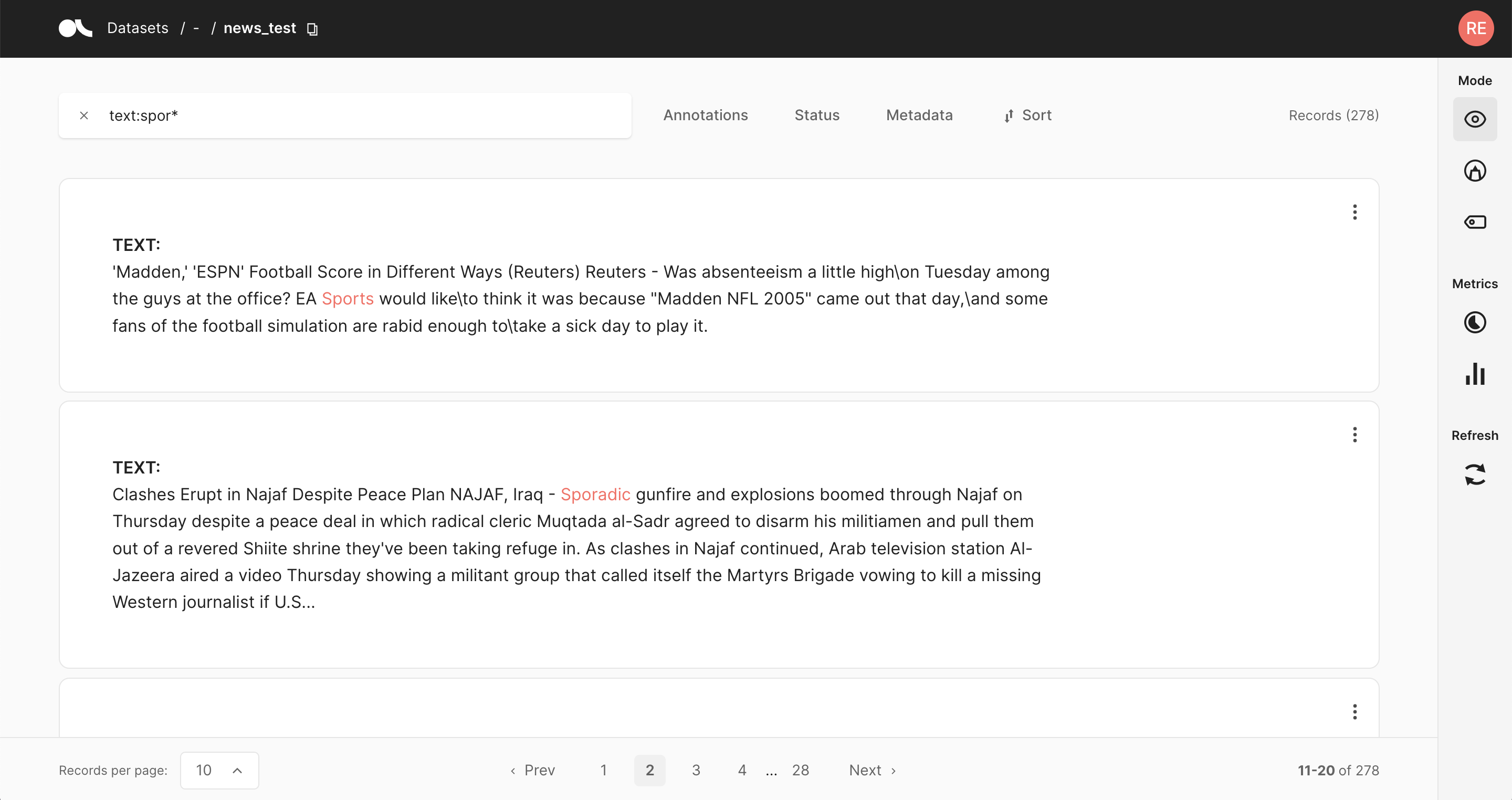
The search in Argilla is driven by Elasticsearch’s powerful query string syntax. It allows you to perform simple fuzzy searches of words and phrases, or complex queries taking full advantage of Argilla’s data model.
The same query can be used in the search bar of the Argilla web app, or with the Python client as optional arguments.
import argilla as rg
rg.load("my_dataset", query="text.exact:example")
Also, we provide a brief summary of the syntax, but for a complete overview, dive deep into the docs below.
The text field uses Elasticsearch’s standard analyzer that ignores capitalization and removes most of the punctuation;
The text.exact field uses the whitespace analyzer that differentiates between lower and upper case, and does take into account punctuation;
text:dog.ortext:fox: matches both of the records.text.exact:dogortext.exact:FOX: matches none of the records.text.exact:dog.ortext.exact:fox: matches only the first record.text.exact:DOGortext.exact:FOX\!: matches only the second record.
Similar reasoning holds for the inputs to look for records in which the subject-key contains the word news, you would search for
inputs.subject:news
Again, as with the text field, you can also use the white space analyzer to perform more fine-grained searches by specifying the exact field.
inputs.subject.exact:NEWS
Imagine you provided the split to which the record belongs as metadata, that is metadata={"split": "train"} or metadata={"split": "test"}.
Then you could only search your training data by specifying the corresponding field in your query:
metadata.split:train
Just like the metadata, you can also use the filter fields in your query. A few examples to emulate the filters in the query string are:
status:Validatedannotated_as:HAMpredicted_by:Model A
Ranges can be specified for date, numeric or string fields. Inclusive ranges are specified with square brackets and exclusive ranges are with curly brackets:
score:[0.5 TO 0.6]score:{0.9 TO *}event_timestamp:[1984-01-01T01:01:01.000000 TO *]last_updated:{* TO 1984-01-01T01:01:01.000000}
You can combine an arbitrary amount of terms and fields in your search using the familiar boolean operators AND, OR and NOT.
The following examples showcase the power of these operators:
text:(quick AND fox): Returns records that contain the word quick and fox. TheANDoperator is the default operator, sotext:(quick fox)is equivalent.text:(quick OR brown): Returns records that contain either the word quick or brown.text:(quick AND fox AND NOT news): Returns records that contain the words quick and fox, and do not contain news.metadata.split:train AND text:fox: Returns records that contain the word fox and that have the metadata “split: train”.NOT _exists_:metadata.split: Returns records that don’t have a metadata split.
Regular expression patterns can be embedded in the query string by wrapping them in forward slashes “/”:
text:/joh?n(ath[oa]n)/: Matches jonathon, jonathan, johnathon, and johnathan.
The supported regular expression syntax is explained in the official Elasticsearch documentation.
You can search for terms that are similar to, but not exactly like the search terms, using the fuzzy operator. This is useful to cover human misspellings:
text:quikc~: Matches quick and quikc.
Wildcard searches can be run on individual search terms, using ? to replace a single character, and * to replace zero or more characters:
text:(qu?ck bro*)text.exact:"Lazy Dog*": Matches, for example, “Lazy Dog”, “Lazy Dog.”, or “Lazy Dogs”.inputs.\*:news: Searches all input fields for the word news.
Search fields#
An important concept when searching with Elasticsearch is the field concept.
Every search term in Argilla is directed to a specific field of the record’s underlying data model.
For example, writing text:fox in the search bar will search for records with the word fox in the field text.
If you do not provide any fields in your query string, by default Argilla will search in the text field.
For a complete list of available fields and their content, have a look at the field glossary below.
Note
The default behavior when not specifying any fields in the query string changed in version >=0.16.0.
Before this version, Argilla searched in a mixture of the the deprecated word and word.extended fields that allowed searches for special characters like ! and ..
If you want to search for special characters now, you have to specify the text.exact field.
For example, this is the query if you want to search for words with an exclamation mark at the end: text.exact:*\!
If you do not retrieve any results after a version update, you should use the words and words.extended fields in your search query for old datasets instead of the text and text.exact ones.
text and text.exact#
The (arguably) most important fields are the text and text.exact fields.
They both contain the text of the records, however in two different forms:
the
textfield uses Elasticsearch’s standard analyzer that ignores capitalization and removes most of the punctuation;the
text.exactfield uses the whitespace analyzer that differentiates between lower and upper case, and does take into account punctuation;
Let’s have a look at a few examples. Suppose we have 2 records with the following text:
The quick brown fox jumped over the lazy dog.
THE LAZY DOG HATED THE QUICK BROWN FOX!
Now consider these queries:
text:dog.ortext:fox: matches both of the records.text.exact:dogortext.exact:FOX: matches none of the records.text.exact:dog.ortext.exact:fox: matches only the first record.text.exact:DOGortext.exact:FOX\!: matches only the second record.
You can see how the text.exact field can be used to search in a more fine-grained manner.
TextClassificationRecord’s inputs#
For text classification records you can take advantage of the multiple inputs when performing a search.
For example, if we uploaded records with inputs={"subject": ..., "body": ...}, you can direct your searches to only one of those inputs by specifying the inputs.subject or inputs.body field in your query.
So to look for records in which the subject contains the word news, you would search for
inputs.subject:news
Again, as with the text field, you can also use the white space analyzer to perform more fine-grained searches by specifying the exact field:
inputs.subject.exact:NEWS
Words and phrases#
Apart from single words you can also search for phrases by surrounding multiple words with double quotes. This searches for all the words in the phrase, in the same order.
If we take the two examples from above, then the following query will only return the second example:
text:"lazy dog hated"
Metadata fields#
You also have the metadata of your records available when performing a search.
Imagine you provided the split to which the record belongs as metadata, that is metadata={"split": "train"} or metadata={"split": "test"}.
Then you could only search your training data by specifying the corresponding field in your query:
metadata.split:train
Metadata are indexed as keywords. This means you cannot search for single words in them, and capitalization and punctuation are taken into account. You can, however, use wild cards.
Warning
The metadata field has by default a maximum length of 128 characters and a field limit of 50. If you wish to change these values, you can do so by setting your own ARGILLA_METADATA_FIELD_LENGTH in the server environment variables. Learn more here
The metadata field has by default a maximum length of 128 characters and a field limit of 50. If you wish to change these values, you can do so by setting your own ARGILLA_METADATA_FIELD_LENGTH in the server environment variables. Learn more here
Non-searchable metadata fields#
If you intend to only store metadata with records and not use it for searches, you can achieve this by defining
the metadata field with a leading underscore. For instance, if you use metadata._my_hidden_field, the field will be
accessible at the record level, but it won’t be used in searches.
Hint
You can use this field to add an image to your record by pointing to its URL like so:
metadata = {"_image_url": "https://..."}
Note that the URL cannot exceed the metadata length limit.
Vector fields#
It is also possible to query the presence of vector field. Imagine you only want to include records with vectors={"vector_1": vector_1}. You can then define a query vectors.vector_1: *.
Filters as query string#
Just like the metadata, you can also use the filter fields in your query. A few examples to emulate the filters in the query string are:
status:Validatedannotated_as:HAMpredicted_by:Model A
The field values are treated as keywords, that is you cannot search for single words in them, and capitalization and punctuation are taken into account. You can, however, use wild cards.
Combine terms and fields#
You can combine an arbitrary amount of terms and fields in your search using the familiar boolean operators AND, OR and NOT.
The following examples showcase the power of these operators:
text:(quick AND fox): Returns records that contain the word quick and fox. TheANDoperator is the default operator, sotext:(quick fox)is equivalent.text:(quick OR brown): Returns records that contain either the word quick or brown.text:(quick AND fox AND NOT news): Returns records that contain the words quick and fox, and do not contain news.metadata.split:train AND text:fox: Returns records that contain the word fox and that have a metadata “split: train”.NOT _exists_:metadata.split: Returns records that don’t have a metadata split.
Query string features#
The query string syntax has many powerful features that you can use to create complex searches. The following is just a hand-selected subset of the many features you can look up on the official Elasticsearch documentation.
Wildcards#
Wildcard searches can be run on individual search terms, using ? to replace a single character, and * to replace zero or more characters:
text:(qu?ck bro*)text.exact:"Lazy Dog*": Matches, for example, “Lazy Dog”, “Lazy Dog.”, or “Lazy Dogs”.inputs.\*:news: Searches all input fields for the word news.
Regular expressions#
Regular expression patterns can be embedded in the query string by wrapping them in forward slashes “/”:
text:/joh?n(ath[oa]n)/: Matches jonathon, jonathan, johnathon, and johnathan.
The supported regular expression syntax is explained in the official Elasticsearch documentation.
Fuzziness#
You can search for terms that are similar to, but not exactly like the search terms, using the fuzzy operator. This is useful to cover human misspellings:
text:quikc~: Matches quick and quikc.
Ranges#
Ranges can be specified for date, numeric or string fields. Inclusive ranges are specified with square brackets and exclusive ranges with curly brackets:
score:[0.5 TO 0.6]score:{0.9 TO *}
Datetime Ranges#
Datetime ranges are a special kind of range query that can be defined for the event_timestamp and last_updated fields.
The formatting is similar to normal range queries, but they require an iso-formatted datetime, which can be obtained via datetime.now().isoformat(), resulting in 1984-01-01T01:01:01.000000. Note that the * can be used interchangeably for the end of time or beginning of time.
event_timestamp:[1984-01-01T01:01:01.000000 TO *]last_updated:{* TO 1984-01-01T01:01:01.000000}
Escaping special characters#
The query string syntax has some reserved characters that you need to escape if you want to search for them.
The reserved characters are: + - = && || > < ! ( ) { } [ ] ^ " ~ * ? : \ /
For instance, to search for “(1+1)=2” you need to write:
text:\(1\+1\)\=2
Field glossary#
This is a table with available fields that you can use in your query string:
Field name |
Description |
TextClass. |
TokenClass. |
TextGen. |
|---|---|---|---|---|
annotated_as |
annotation |
✔ |
✔ |
✔ |
annotated_by |
annotation agent |
✔ |
✔ |
✔ |
event_timestamp |
timestamp |
✔ |
✔ |
✔ |
id |
id |
✔ |
✔ |
✔ |
inputs.* |
inputs |
✔ |
||
metadata.* |
metadata |
✔ |
✔ |
✔ |
vectors.* |
vectors |
✔ |
✔ |
✔ |
last_updated |
date of the last update |
✔ |
✔ |
✔ |
predicted_as |
prediction |
✔ |
✔ |
✔ |
predicted_by |
prediction agent |
✔ |
✔ |
✔ |
score |
prediction score |
✔ |
||
status |
status |
✔ |
✔ |
✔ |
text |
text, standard analyzer |
✔ |
✔ |
✔ |
text.exact |
text, whitespace analyzer |
✔ |
✔ |
✔ |
tokens |
tokens |
✔ |
||
- |
- |
- |
- |
- |
metrics.text_lengt |
Input text length |
✔ |
✔ |
✔ |
metrics.tokens.idx |
Token idx in record |
✔ |
||
metrics.tokens.value |
Text of the token |
✔ |
||
metrics.tokens.char_start |
Start char idx of token |
✔ |
||
metrics.tokens.char_end |
End char idx of token |
✔ |
||
metrics.annotated.mentions.value |
Text of the mention (annotation) |
✔ |
||
metrics.annotated.mentions.label |
Label of the mention (annotation) |
✔ |
||
metrics.annotated.mentions.score |
Score of the mention (annotation) |
✔ |
||
metrics.annotated.mentions.capitalness |
Mention capitalness (annotation) |
✔ |
||
metrics.annotated.mentions.density |
Local mention density (annotation) |
✔ |
||
metrics.annotated.mentions.tokens_length |
Mention length in tokens (annotation) |
✔ |
||
metrics.annotated.mentions.chars_length |
Mention length in chars (annotation) |
✔ |
||
metrics.annotated.tags.value |
Text of the token (annotation) |
✔ |
||
metrics.annotated.tags.tag |
IOB tag (annotation) |
✔ |
||
metrics.predicted.mentions.value |
Text of the mention (prediction) |
✔ |
||
metrics.predicted.mentions.label |
Label of the mention (prediction) |
✔ |
||
metrics.predicted.mentions.score |
Score of the mention (prediction) |
✔ |
||
metrics.predicted.mentions.capitalness |
Mention capitalness (prediction) |
✔ |
||
metrics.predicted.mentions.density |
Local mention density (prediction) |
✔ |
||
metrics.predicted.mentions.tokens_length |
Mention length in tokens (prediction) |
✔ |
||
metrics.predicted.mentions.chars_length |
Mention length in chars (prediction) |
✔ |
||
metrics.predicted.tags.value |
Text of the token (prediction) |
✔ |
||
metrics.predicted.tags.tag |
IOB tag (prediction) |
✔ |