🤔 Work with suggestions and responses#
Feedback Dataset#
Note
The dataset class covered in this section is the FeedbackDataset. This fully configurable dataset will replace the DatasetForTextClassification, DatasetForTokenClassification, and DatasetForText2Text in Argilla 2.0. Not sure which dataset to use? Check out our section on choosing a dataset.

Unlike metadata and vectors, suggestions and responses are not defined as part of the FeedbackDataset schema. Instead, they are added to the records as you create them.
Format suggestions#
Suggestions refer to suggested responses (e.g. model predictions) that you can add to your records to make the annotation process faster. These can be added during the creation of the record or at a later stage. Only one suggestion can be provided for each question, and suggestion values must be compliant with the pre-defined questions e.g. if we have a RatingQuestion between 1 and 5, the suggestion should have a valid value within that range.
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "relevant",
"value": "YES",
"agent": model_name,
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "content_class",
"value": ["hate", "violent"],
"agent": model_name,
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "preference",
"value":[
{"rank": 1, "value": "reply-2"},
{"rank": 2, "value": "reply-1"},
{"rank": 3, "value": "reply-3"},
],
"agent": model_name,
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "quality",
"value": 5,
"agent": model_name,
}
]
)
from argilla.client.feedback.schemas import SpanValueSchema
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "entities",
"value": [
SpanValueSchema(
start=0, # position of the first character of the span
end=10, # position of the character right after the end of the span
label="ORG",
score=1.0
)
],
"agent": model_name,
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "corrected-text",
"value": "This is a *suggestion*.",
"agent": model_name,
}
]
)
Add suggestions#
To add suggestions to the records, it slightly depends on whether you are using a FeedbackDataset or a RemoteFeedbackDataset. For an end-to-end example, check our tutorial on adding suggestions and responses.
Note
The dataset not yet pushed to Argilla or pulled from HuggingFace Hub is an instance of FeedbackDataset whereas the dataset pulled from Argilla is an instance of RemoteFeedbackDataset. The difference between the two is that the former is a local one and the changes made on it stay locally. On the other hand, the latter is a remote one and the changes made on it are directly reflected on the dataset on the Argilla server, which can make your process faster.
for record in dataset.records:
record.suggestions = [
{
"question_name": "relevant",
"value": "YES",
"agent": model_name,
}
]
modified_records = []
for record in dataset.records:
record.suggestions = [
{
"question_name": "relevant",
"value": "YES",
"agent": model_name,
}
]
modified_records.append(record)
dataset.update_records(modified_records)
Note
You can also follow the same strategy to modify existing suggestions.
Format responses#
If your dataset includes some annotations, you can add those to the records as you create them. Make sure that the responses adhere to the same format as Argilla’s output and meet the schema requirements for the specific type of question being answered. Also make sure to include the user_id in case you’re planning to add more than one response for the same question. You can only specify one response with an empty user_id: the first occurrence of user_id=None will be set to the active user_id, while the rest of the responses with user_id=None will be discarded.
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"relevant":{
"value": "YES"
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"content_class":{
"value": ["hate", "violent"]
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"preference":{
"value":[
{"rank": 1, "value": "reply-2"},
{"rank": 2, "value": "reply-1"},
{"rank": 3, "value": "reply-3"},
],
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"quality":{
"value": 5
}
}
}
]
)
from argilla.client.feedback.schemas import SpanValueSchema
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"entities":{
"value": [
SpanValueSchema(
start=0,
end=10,
label="ORG"
)
]
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"corrected-text":{
"value": "This is a *response*."
}
}
}
]
)
Add responses#
To add responses to the records, it slightly depends on whether you are using a FeedbackDataset or a RemoteFeedbackDataset. For an end-to-end example, check our tutorial on adding suggestions and responses.
Note
The dataset not yet pushed to Argilla or pulled from HuggingFace Hub is an instance of FeedbackDataset whereas the dataset pulled from Argilla is an instance of RemoteFeedbackDataset. The difference between the two is that the former is a local one and the changes made on it stay locally. On the other hand, the latter is a remote one and the changes made on it are directly reflected on the dataset on the Argilla server, which can make your process faster.
for record in dataset.records:
record.responses = [
{
"values":{
"label":{
"value": "YES",
}
}
}
]
from datetime import datetime
modified_records = []
for record in dataset.records:
record.responses = [
{
"values":{
"label":{
"value": "YES",
}
},
"inserted_at": datetime.now(),
"updated_at": datetime.now(),
}
]
modified_records.append(record)
dataset.update_records(modified_records)
Note
You can also follow the same strategy to modify existing responses.
Other datasets#
Note
The records classes covered in this section correspond to three datasets: DatasetForTextClassification, DatasetForTokenClassification, and DatasetForText2Text. These will be deprecated in Argilla 2.0 and replaced by the fully configurable FeedbackDataset class. Not sure which dataset to use? Check out our section on choosing a dataset.
Add suggestions#
Suggestions refer to suggested responses (e.g. model predictions) that you can add to your records to make the annotation process faster. These can be added during the creation of the record or at a later stage. We allow for multiple suggestions per record.
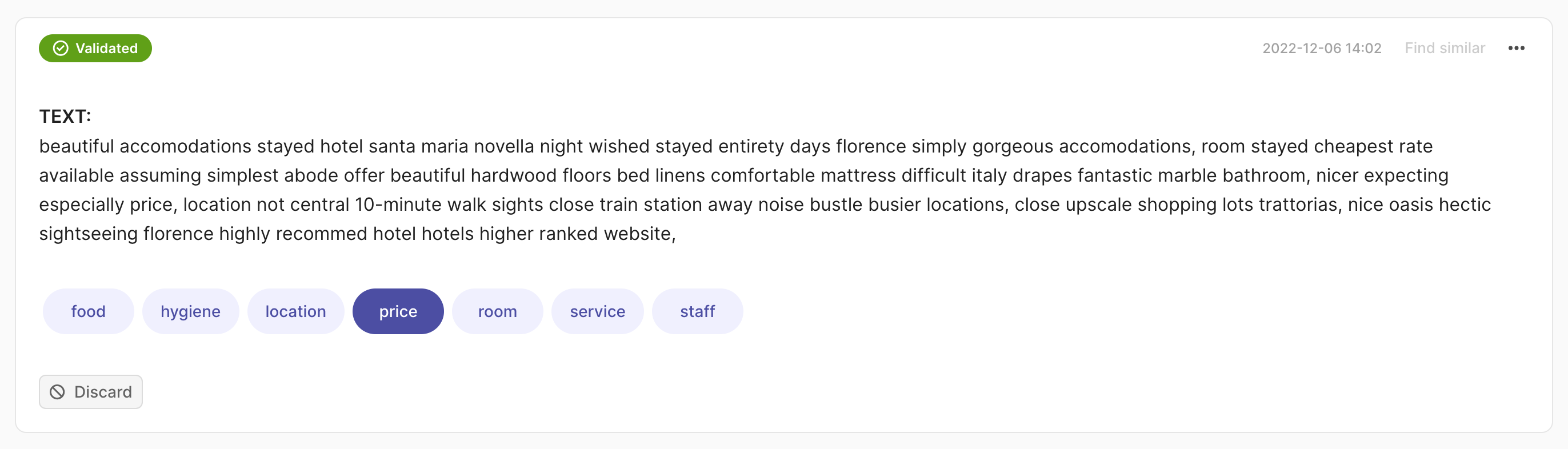
In this case, we expect a List[Tuple[str, float]] as the prediction, where the first element of the tuple is the label and the second the confidence score.
import argilla as rg
rec = rg.TextClassificationRecord(
text=...,
prediction=[("label_1", 0.75), ("label_2", 0.25)],
)
In this case, we expect a List[Tuple[str, float]] as the prediction, where the second element of the tuple is the confidence score of the prediction. In the case of multi-label, the multi_label attribute of the record should be set to True.
import argilla as rg
rec = rg.TextClassificationRecord(
text=...,
prediction=[("label_1", 0.75), ("label_2", 0.75)],
multi_label=True
)
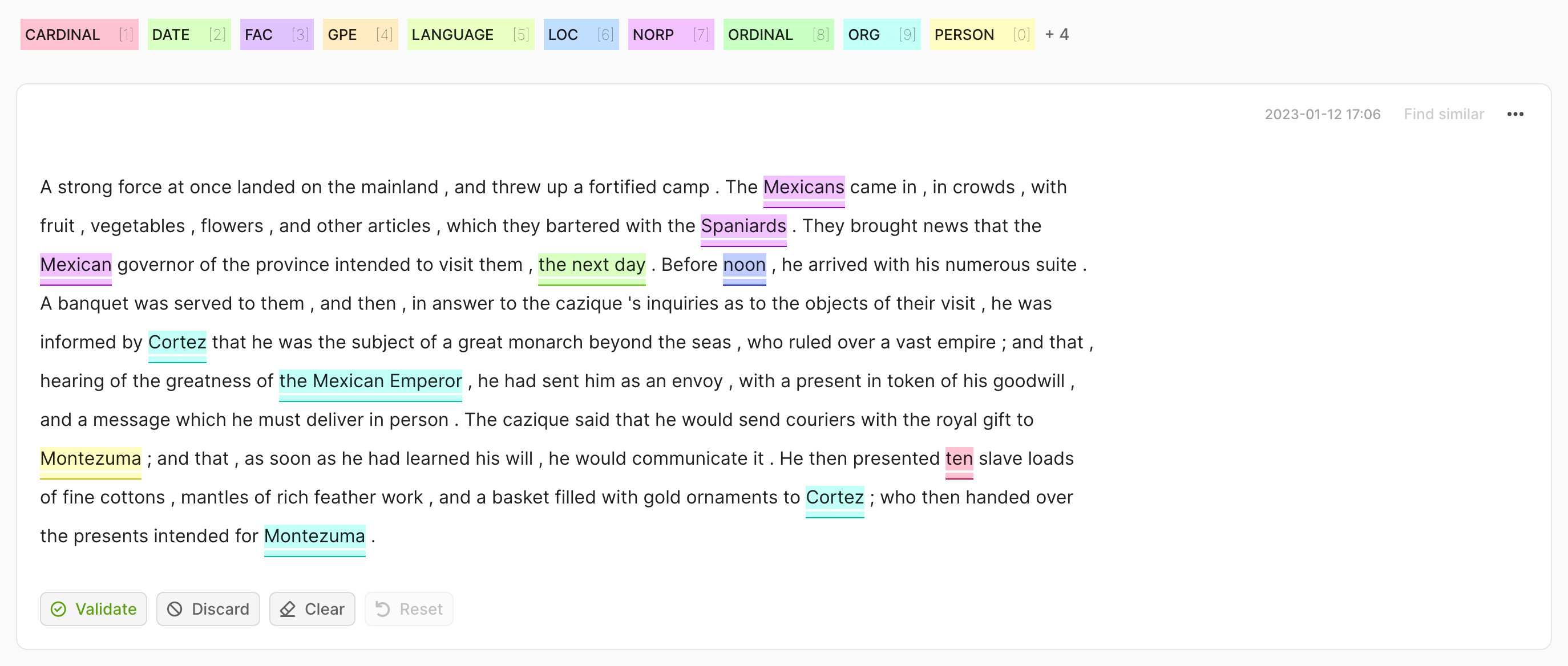
In this case, we expect a List[Tuple[str, int, int, float]] as the prediction, where the second and third elements of the tuple are the start and end indices of the token in the text.
import argilla as rg
rec = rg.TokenClassificationRecord(
text=...,
tokens=...,
prediction=[("label_1", 0, 7, 0.75), ("label_2", 26, 33, 0.8)],
)
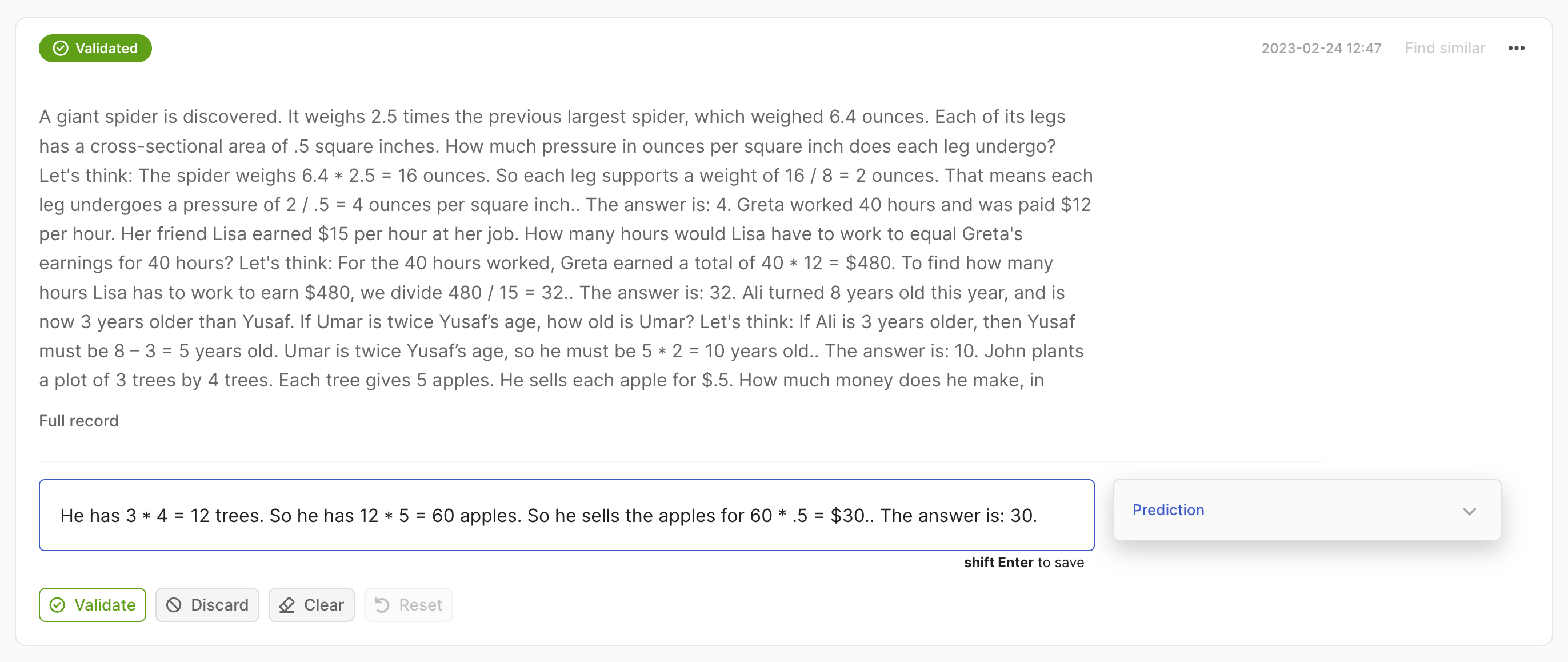
In this case, we expect a List[str] as the prediction.
import argilla as rg
rec = rg.Text2TextRecord(
text=...,
prediction=["He has 3*4 trees. So he has 12*5=60 apples."],
)
Add responses#
If your dataset includes some annotations, you can add those to the records as you create them. Make sure that the responses adhere to the same format as Argilla’s output and meet the schema requirements.
In this case, we expect a str as the annotation.
import argilla as rg
rec = rg.TextClassificationRecord(
text=...,
annotation="label_1",
)
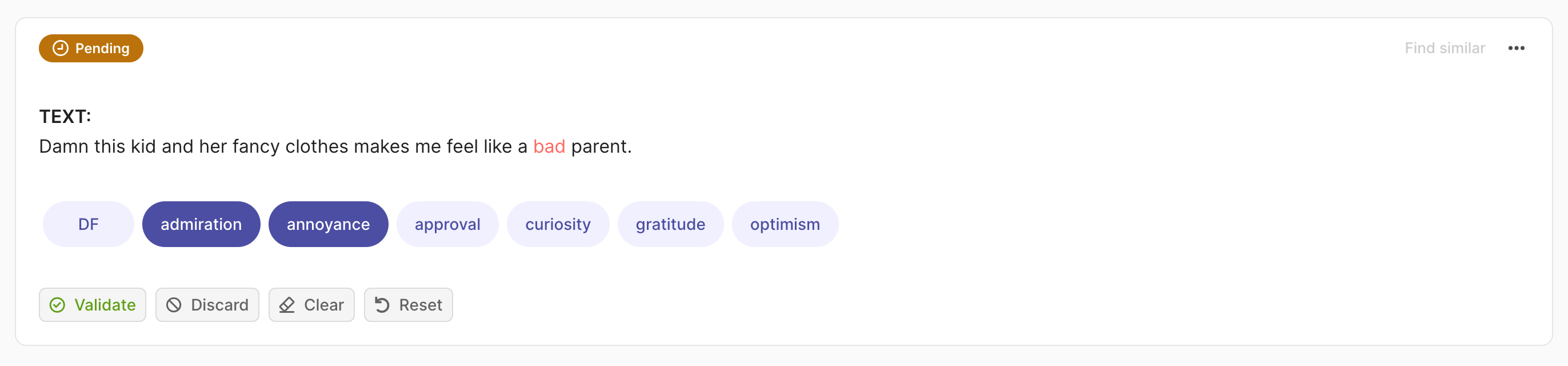
In this case, we expect a List[str] as the annotation. In case of multi-label, the multi_label attribute of the record should be set to True.
import argilla as rg
rec = rg.TextClassificationRecord(
text=...,
annotation=["label_1", "label_2"],
multi_label=True
)
In this case, we expect a List[Tuple[str, int, int]] as the annotation, where the second and third elements of the tuple are the start and end indices of the token in the text.
import argilla as rg
rec = rg.TokenClassificationRecord(
text=...,
tokens=...,
annotation=[("label_1", 0, 7), ("label_2", 26, 33)],
)
In this case, we expect a str as the annotation.
import argilla as rg
rec = rg.Text2TextRecord(
text=...,
annotation="He has 3*4 trees. So he has 12*5=60 apples.",
)