sentence-transformers: Add semantic vectors to your dataset#
In this tutorial, we will add semantic representations for searching similar records using the SentenceTransformersExtractor integration with Argilla.
We will cover the following topics:
📂 Load an example dataset
📃 Add
vectorsto records🗒️ Add
VectorSettingsto a FeedbackDataset
Introduction#
The basic idea is to use a pre-trained model to generate a vector representation for each relevant TextFields within the records. These vectors are then indexed within our databse and can then used to search based the similarity between texts. This should be useful for searching similar records based on the semantic meaning of the text.
To get the these vectors and config, we will use the SentenceTransformersExtractor based on the sentence-transformers library. The default model we use for this is the TaylorAI/bge-micro-v2, which offers a nice trade-off between speed and accuracy, but you can use any model from the sentence-transformers library or from the Hugging Face
Hub.
Running Argilla#
For this tutorial, you will need to have an Argilla server running. There are two main options for deploying and running Argilla:
Deploy Argilla on Hugging Face Spaces: If you want to run tutorials with external notebooks (e.g., Google Colab) and you have an account on Hugging Face, you can deploy Argilla on Spaces with a few clicks:

For details about configuring your deployment, check the official Hugging Face Hub guide.
Launch Argilla using Argilla’s quickstart Docker image: This is the recommended option if you want Argilla running on your local machine. Note that this option will only let you run the tutorial locally and not with an external notebook service.
For more information on deployment options, please check the Deployment section of the documentation.
Tip
This tutorial is a Jupyter Notebook. There are two options to run it:
Use the Open in Colab button at the top of this page. This option allows you to run the notebook directly on Google Colab. Don’t forget to change the runtime type to GPU for faster model training and inference.
Download the .ipynb file by clicking on the View source link at the top of the page. This option allows you to download the notebook and run it on your local machine or on a Jupyter Notebook tool of your choice.
Set up the Environment#
To complete this tutorial, you will need to install the Argilla client and a few third-party libraries using pip:
[ ]:
# %pip install --upgrade pip
%pip install argilla -qqq
%pip install datasets
%pip install sentence-transformers
Let’s make the needed imports:
[ ]:
import argilla as rg
from argilla.client.feedback.integrations.sentencetransformers import SentenceTransformersExtractor
If you are running Argilla using the Docker quickstart image or a public Hugging Face Spaces, you need to init the Argilla client with the URL and API_KEY:
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
# Replace workspace with the name of your workspace
rg.init(
api_url="http://localhost:6900",
api_key="owner.apikey",
workspace="argilla"
)
If you’re running a private Hugging Face Space, you will also need to set the HF_TOKEN as follows:
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="admin.apikey",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
Enable Telemetry#
We gain valuable insights from how you interact with our tutorials. To improve ourselves in offering you the most suitable content, using the following lines of code will help us understand that this tutorial is serving you effectively. Though this is entirely anonymous, you can choose to skip this step if you prefer. For more info, please check out the Telemetry page.
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
Load the Dataset#
For this example, we will use the squad dataset from Hugging Face, which is a reading comprehension dataset composed of questions on a collection of Wikipedia articles, the given context and the answers.
[ ]:
# Load the dataset and select the first 100 examples
dataset = rg.FeedbackDataset.from_huggingface("argilla/squad", split="train[:100]")
dataset
[ ]:
dataset.records[0]
[ ]:
ds_remote = dataset.push_to_argilla("sentence-transformers")
Add Sentence Transformers Vectors#
Our dataset currently lacks vectors. To address this, we will add sentence transformers vectors using the SentenceTransformersExtractor, which has the following arguments:
model: the model to use for extracting the embeddings.
show_progress: whether to show the progress bar.
For more information about the SentenceTransformersExtractor, please check the practical guide. We can add metadata to local or remote records or datasets. Let’s see how to do both.
First, we will add the vector embeddings to the records we have defined above. To do so, we will initialize the SentenceTransformersExtractor where we will compute them only for the question field.
[ ]:
# Initialize the SentenceTransformersExtractor
ste = SentenceTransformersExtractor(
model = "TaylorAI/bge-micro-v2", # Use a model from https://huggingface.co/models?library=sentence-transformers
show_progress = False,
)
To records#
We can now add the vectors to the records using the update_records method. This method takes the following arguments:
records: the records to update.
fields: the field to update.
overwrite: whether to overwrite the existing vectors.
[ ]:
# Update the records
updated_records = ste.update_records(
records=ds_remote.records,
fields=None, # Use all fields
overwrite=True, # Overwrite existing fields
)
As we can see below, the default metrics for the indicated field vectors have been added to the records as metadata.
[ ]:
updated_records[0].vectors.keys()
Note that these updated records are not stored in the dataset yet. They can be added to a dataset with the correct settings through the update_records methods. If not present, will need to add the correct to the dataset.
To a Dataset#
Now, we will update our dataset with the vectors and vector setting in one run. In this case, we will re-use the initialized SentenceTransformersExtractor. The update_dataset method takes the following arguments:
dataset: the dataset to update.
fields: the fields to update.
update_records: whether to update the records directly.
overwrite: whether to overwrite the existing vectors.
[ ]:
# Update the dataset
ste.update_dataset(
dataset=ds_remote,
fields=["context"], # Only update the context field
update_records=True, # Update the records in the dataset
overwrite=False, # Overwrite existing fields
)
In this case, it is a remote dataset so it will be updated directly on Argilla. Note this integration does not keep the vectors locally to avoid memory issues, hence ds_remote.records[0].vectors.keys() will not show any vectors. As we can see below, the vectors have been added to the dataset.
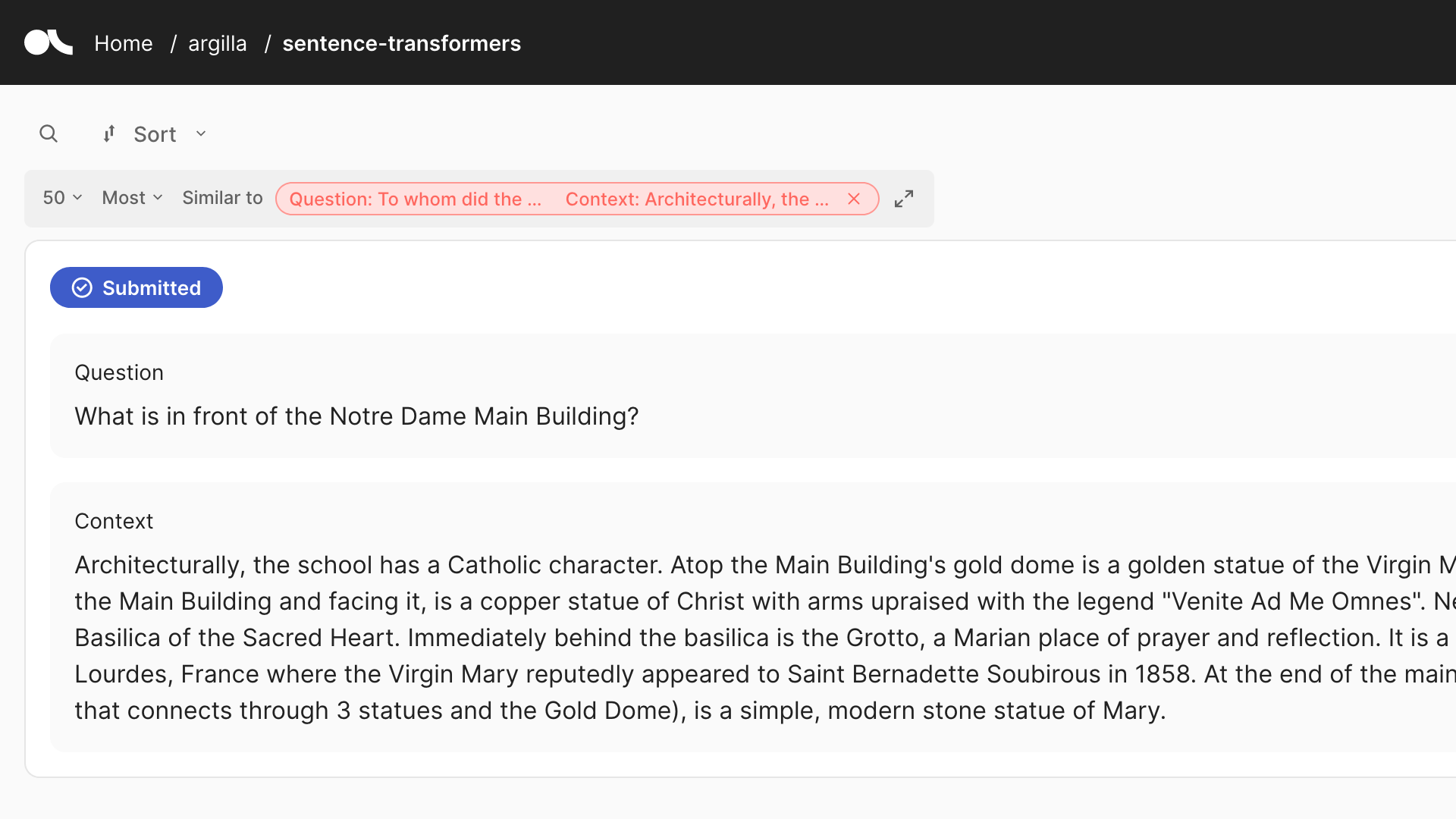
Conclusions#
In this tutorial, we have explored how to add vector embeddings to records and datasets using the SentenceTransformers integrated on Argilla, what it is really useful for annotation projects.