🎡 Create synthetic data and annotations with LLMs#
LLMs are diverse and can be used for many different tasks. Besides cool chat interactions, LLMs can be powerful tools for creating synthetic data and providing initial suggestions for labelling tasks for which you don’t have any data yet. This way anyone can easily get a head start on bootstrapping a project.
In this example, we will demonstrate how to use different LLM tools, like openai, transformers, langchain and outlines, to create synthetic data and we can leverage those same LLMs for providing initial annotation or suggestions.
If you want a more basic introduction to synthetic data with our ArgillaCallbackHandler for langchain, you can take a look at this practical guide.
Warning
Do keep in mind that LLMs have licenses and not every LLM can be used for creating synthetic data in every operational setting. Please check the license of the LLM you are using before using it for creating synthetic data.
Let’s get started!
Note
This tutorial is a Jupyter Notebook. There are two options to run it:
Use the Open in Colab button at the top of this page. This option allows you to run the notebook directly on Google Colab. Don’t forget to change the runtime type to GPU for faster model training and inference.
Download the .ipynb file by clicking on the View source link at the top of the page. This option allows you to download the notebook and run it on your local machine or on a Jupyter notebook tool of your choice.
Setup#
For this tutorial, you will need to have an Argilla server running. If you don’t have one already, check out our Quickstart or Installation pages. Once you do, complete the following steps:
Install the Argilla client and the required third-party libraries using
pip:
[ ]:
!pip install argilla openai langchain outlines tiktoken transformers ipywidgets jupyter
Let’s make the necessary imports:
[13]:
import argilla as rg
import os
import random
from langchain import OpenAI, PromptTemplate, LLMChain
from langchain.output_parsers import CommaSeparatedListOutputParser
from outlines import models, text
from outlines.text import generate
If you are running Argilla using the Docker quickstart image or Hugging Face Spaces, you need to init the Argilla client with the
URLandAPI_KEY:
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
rg.init(
api_url="http://localhost:6900",
api_key="admin.apikey"
)
If you’re running a private Hugging Face Space, you will also need to set the HF_TOKEN as follows:
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="admin.apikey",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
We also need to set your OpenAI API credentials by creating an API key and setting defining the
OPENAI_API_KEYenvironment variable.
Enable Telemetry#
We gain valuable insights from how you interact with our tutorials. To improve ourselves in offering you the most suitable content, using the following lines of code will help us understand that this tutorial is serving you effectively. Though this is entirely anonymous, you can choose to skip this step if you prefer. For more info, please check out the Telemetry page.
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
Define a FeedbackDataset#
In this example, we will create a synthetic dataset for a banking customer care scenario. We assume that customers will write text requests. These requests should then be classified for sentiment and topics. The topics will be a multi-label classification and can be used to route the request to the correct department. The sentiment will be used using a single-label classification to determine if the request needs to be handled with priority.
[33]:
sentiment = ["positive", "neutral", "negative"]
topic = ["new_card", "mortgage", "application", "payments"]
dataset = rg.FeedbackDataset(
fields = [rg.TextField(name="text")],
questions = [
rg.LabelQuestion(
name="sentiment",
title="What is the sentiment of the message?",
labels=sentiment
),
rg.MultiLabelQuestion(
name="topics",
title="Select the topic(s) of the message?",
labels=topic,
visible_labels=4
)
],
guidelines=(
"This dataset contains messages from a bank's customer support chatbot. "
"The goal is to label the sentiment and topics of the messages."
)
)
Create synthetic data#
We will use LLMs to generate the synthetic data for each step of the NLP task. First, we will create text requests from customers for a bank. Next, we will create input for the LabelQuestion to assess the sentiment of the requests and lastly, we will create input for the MultiLabelQuestion to classify the requests.
We will do this using OpenAI models in combination with the LangChain and open-source transformer-based models in combination with Outlines packages.
| The LangChain framework is a wrapper around LLM models that allows for easier data-aware and agent-based LLM models.
| Outlines is a Python library to write reliable programs for conditional generation during interactions with generative models.
Note
The process of prompt engineering is a trial-and-error process. Changes somewhere might result in undesirable effects in another place in the language chain. The examples below are just a starting point and can be improved by experimenting with different prompts and templates.
Initialize Generative model#
LangChain with OpenAI#
For the usage of LangChain you need to pass the OPENAI_API_KEY environment variable to the OpenAI class. You can do this by using the os package. The model variable is then ready to use in the examples below.
[8]:
os.environ["OPENAI_API_KEY"] = "sk-..."
openai_model = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
Outlines with Transformers#
Even though Outlines does provide some support for OpenAI, we will use basic transformers for this example. You can use any generative model from the HuggingFace model hub by passing the name of the model to the transformers function. The model variable is then ready to use in the examples below.
[4]:
transformer_model = models.transformers("gpt2")
TextField#
For creating a review, we rely on free text generation based on a prompt. This should be good enough for our purposes of creating a synthetic dataset as well as keeping the process as simple as possible.
LangChain#
OpenAI models have been instruction-tuned and can thus be used via LangChain to generate synthetic data. This is done using a PrompTemplate that infers information from topic and sentiment variables that are passed to the predict() method.
[35]:
template = (
"Write a customer review for a bank. "
"Do that for topic of {topic}. "
"Do that with one a {sentiment} sentiment."
)
prompt = PromptTemplate(template=template, input_variables=["topic", "sentiment"])
llm_chain_review = LLMChain(prompt=prompt, llm=openai_model)
def generate_langchain_review():
return llm_chain_review.predict(
topic=random.choice(topic),
sentiment=random.choice(sentiment)
).strip()
generate_langchain_review()
[35]:
'I recently had the pleasure of working with the mortgage team at this bank, and I can confidently say that their level of service and expertise was second to none. They answered all of my questions quickly and took the time to explain the process to me in detail. I felt like they genuinely had my best interests at heart and they made the process of obtaining a mortgage as smooth and stress-free as possible. I would highly recommend this bank for anyone looking to take out a mortgage.'
We will now create a function that can generate n-random examples to evaluate the performance. As we can expect from the recent generation of OpenAI models, the results look good and seem diverse enough to be used as synthetic data.
[38]:
def generate_n_langchain_reviews(n=2):
reviews = []
for n in range(n):
reviews.append(generate_langchain_review())
return reviews
langchain_reviews = generate_n_langchain_reviews()
langchain_reviews
[38]:
["I've been a customer of this bank for over 5 years, and I've been completely satisfied with their payment services. The online payment system is easy to use and the customer service team is always quick to respond to any questions I have. I never have to worry about my payments being delayed or lost, which is always reassuring. Highly recommend this bank for anyone looking for reliable payment services!",
"I recently secured a mortgage with this bank and was so impressed with the level of service I received. From the start, the staff was friendly, knowledgeable, and willing to go above and beyond to get me the best deal. The process was straightforward and the paperwork was easy to understand. I'm thrilled with my new mortgage and would highly recommend this bank to anyone looking for a mortgage."]
Outlines#
Not all generative models are instruction tuned and as useful as modern-day LLMs. So take into account that this should be reflected in your prompt and the expected quality of the generated text.
[35]:
@text.prompt
def generator(topic, sentiment):
"""
The customer service for {{ topic }} of the bank is {{ sentiment }} because
"""
def generate_outlines_review():
prompt = generator(random.choice(topic), random.choice(sentiment))
answer = text.generate.continuation(transformer_model, max_tokens=100)(prompt)
answer = "Because"+ answer
return answer
generate_outlines_review()
[35]:
"Because of technical questions and consumer protection. Telephone orders are not placed in the bank's database because where homeowners need to know that their bank is registered here, this protection providing a system to check their record is not protected by even their own state laws, which is why I don't believe criminal laws should be used to enforce the bank ATM login, nor should neutral other town or guild banking providers be regulated. These accountants have followed the local law explanations, and they do not deserve criminal sanction for allowing a"
We will now create a function that can generate n-random examples. Looking at the examples, the model seems to generate roughly related texts but in general, the quality proves poorer. It can therefore be recommended to use another type of models, which might be instruction tuned to ensure a higher quality generation. Additionally, Outlines offers more dynamic control over the generation process, which might be used to improve the quality of the generated text too.
[53]:
def generate_n_outlines_reviews(n=2):
reviews = []
for n in range(n):
reviews.append(generate_outlines_review())
return reviews
outlines_reviews = generate_n_outlines_reviews()
outlines_reviews
[53]:
['Because of damaged card and adds some other attachments from other data on the ToS or database file."',
'Because of jurisdictional issues," said the FTC\'s executive director, Paul R. Matthewi. "Technology seems to be without limits in the fraud marketplace as we moved toward a new way of remote law enforcement and convenience."\n\nIt is unclear, however, how people will get paid—or how many will be affected. In TekSavvy, which relies on similar technology many consumer goods companies rely on to keep their customers healthy, some of America\'s top credit card holders appear to still need money,']
LabelQuestion#
For this step, we will re-use the generated reviews from langchain_reviews and outlines_reviews and label their sentiment using the respective frameworks. This will be done by assuming a str to be returned from both of the lists of sentiment defined above.
LangChain#
We are using a jinja-like template, which requires us to define the basic prompt as an input_variable for LangChain. For the initial example, we are using a demo.
[24]:
template = (
f'Choose from the sentiments: {sentiment}. '
'Return a single sentiment.'
'{prompt}'
)
prompt = PromptTemplate(template=template, input_variables=["prompt"])
llm_chain_sentiment = LLMChain(prompt=prompt, llm=openai_model)
def get_sentiment_from_langchain(text: str) -> str:
return llm_chain_sentiment.predict(prompt=text).strip().lower()
get_sentiment_from_langchain("I love langchain and openai for sentiment labelling.")
[24]:
'positive'
We get the sentiment labels for the generated langchain_reviews. We can see that the sentiment labels are not always correct, but they are mostly correct. This is because the LLMs are not perfect, but they are good enough to be used for synthetic data generation and providing suggestions for human annotators.
[46]:
langchain_sentiment = [get_sentiment_from_langchain(reviews) for reviews in langchain_reviews]
langchain_sentiment
[46]:
['positive', 'positive']
Outlines#
Outlines provide an out-of-the-box implementation for guided labeling with generative, however, in some cases (zero-shot) classification models from the HuggingFace library can be used to provide a good point for the providing suggestions during a labeling process too. Take a look at our example with SetFit.
[51]:
def get_sentiment_from_outlines(text: Union[str, list]) -> str:
return generate.choice(transformer_model, sentiment)(text)
get_sentiment_from_outlines("I love outlines and transformers for sentiment labelling.")
[51]:
'positive'
We can use the choice-methods with a list of strings too.
[55]:
outlines_sentiment = get_sentiment_from_outlines(outlines_reviews)
outlines_sentiment
[55]:
['neutral', 'positive']
MultiLabelQuestion#
For this step, we will re-use the generated reviews from lanchain_reviews and outlines_reviews and label their topics as part of a multi-label classification problem.
Langchain#
Note that we are now using an output parser as a post-processing step for the returned output. We do this to ensure that we can obtain a List[str]. We will use the built-in CommaSeparatedListOutputParser, which split strings by comma and returns a list of strings as output. And we are using the jinja-like templating in a similar way as with the SingleLabelQuestion.
[30]:
output_parser = CommaSeparatedListOutputParser()
template = (
f'Classify the text as the following topics: {topic}. '
'Return zero or more topics as a comma-separated list. If zero return an empty string. '
'{prompt}'
)
prompt = PromptTemplate(template=template, input_variables=["prompt"], output_parser=output_parser)
llm_chain_topics = LLMChain(prompt=prompt, llm=openai_model, output_parser=output_parser)
def get_topics_from_langchain(text: str) -> str:
return [topic.lower() for topic in llm_chain_topics.predict(prompt=text) if topic != '']
get_topics_from_langchain(f"I love extracting {topic} with and openai and langchain for topic labelling.")
[30]:
['new_card', 'mortgage', 'application', 'payments']
We get the topic labels for the generated langchain_reviews.
[67]:
langchain_topics = [get_topics_from_langchain(review) for review in langchain_reviews]
langchain_topics
[67]:
[['new_card'], ['mortgage', 'application']]
Outlines#
Outlines does not have a direct way to generate data from choices but we are able to leverage their Pydantic integration to generate a json schema. Note that this is a hacky way to facilitate this guided generation and is not officially mentioned in the paper behind the outlines package.
Additionally, the use of json requires pydantic>=2.
# DEMO CODE
class Topic(BaseModel):
new_card: bool = False
mortgage: bool = False
application: bool = False
payments: bool = False
def get_topics_from_outlines(text: str) -> str:
topics = []
json_data = generate.json(transformer_model, Topic)(langchain_reviews[0])
for key, value in json_data.items():
if value:
topics.append(key)
return topics
get_topics_from_outlines(f"I love extracting {topic} with and outlines and transformers for topic labelling.")
Create synthetic records#
Now we have our synthetic data and predictions, we can use them to create Argilla records. We will create completely artificial records from the text for the TextField and we will assign the sentiment and topics as model suggestions for the LabelQuestion and MultiLabelQuestion, respectively. These suggestions will help the annotators to label the data faster and more accurately, but instead of using them as suggestions, you would also be able to apply them as annotated
responses directly.
For demo purposes, we will only create records with synthetic data obtained from langchain.
[31]:
def create_synthetic_record():
review = generate_langchain_review()
record = rg.FeedbackRecord(
fields={
"text": review,
}
)
sentiment = get_sentiment_from_langchain(review)
topics = get_topics_from_langchain(review)
record.update(suggestions=[
{"question_name": "sentiment", "value": sentiment},
{"question_name": "topics", "value": topics}
])
return record
record = create_synthetic_record()
record
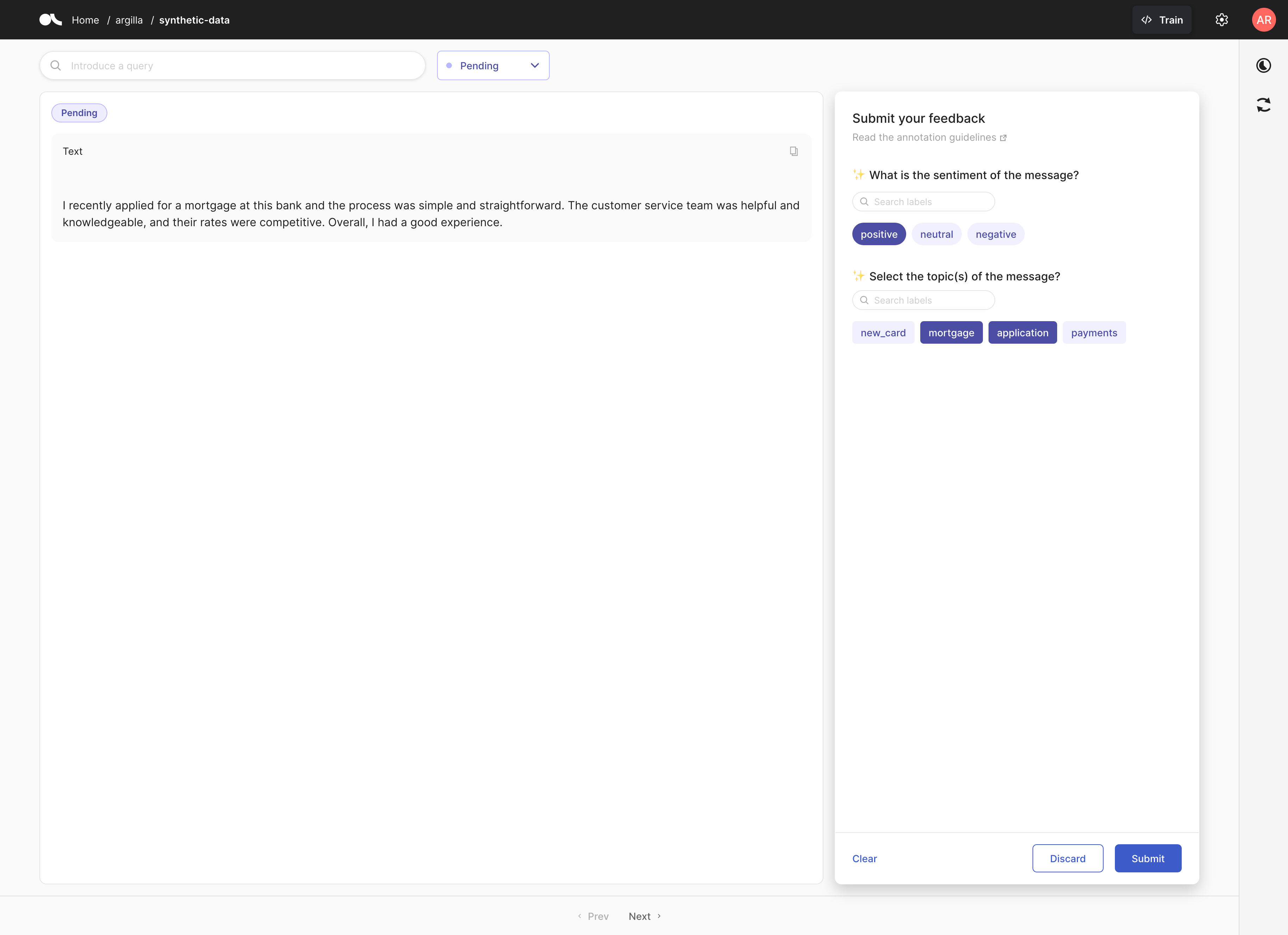
[31]:
FeedbackRecord(fields={'text': '\n\nI recently applied for a mortgage at this bank and the process was simple and straightforward. The customer service team was helpful and knowledgeable, and their rates were competitive. Overall, I had a good experience.'}, metadata={}, responses=[], suggestions=(SuggestionSchema(question_id=None, question_name='sentiment', type=None, score=None, value='positive', agent=None), SuggestionSchema(question_id=None, question_name='topics', type=None, score=None, value=['mortgage', 'application'], agent=None)), external_id=None)
We will then add the synthetic record to the dataset, and upload the model data and dataset to the Argilla server
[ ]:
dataset.add_records([record])
remote_dataset = dataset.push_to_argilla(name="synthetic-data", workspace="argilla")
Conclusion#
In this tutorial, we have covered how to create synthetic data using OpenAI and Lanchain, or Transformers and Outlines. We have highlighted some caveats to synthetic data generation when it comes to prompt engineering. Finally, we’ve shown how to use this synthesized data as input and suggestions for Argilla records.
To learn more about LLMs, LangChain and OpenAI check out these links: