🪄 Fine-tuning and evaluating GPT-3.5 with human feedback for RAG#
This guide explains how to fine-tune OpenAI’s GPT3.5-turbo with your own data and Argilla to improve a RAG (Retrieval Augmented Generation) system.
It includes the following steps:
Setting up a RAG pipeline using LlamaIndex and Unstructured to answer questions using a document about Argilla Cloud.
Generating potential questions with LlamaIndex to build a training and test set.
Building a dataset for collecting human written responses with Argilla.
Fine-tuning GPT3.5-turbo with high-quality data.
Evaluating the fine-tuned model vs. the base model with human preference data from Argilla.
The goal of the tutorial is to demonstrate how to incorporate human feedback into your LLM development for two critical stages:
Gathering high-quality data for fine-tuning,
Gathering human feedback for evaluation of LLM applications.
Given the ongoing debate between Retrieval Augmented Generation (RAG) and fine-tuning, we selected a real-world RAG use case to demonstrate how fine-tuning enhances the style, utility, and relevance of responses within a RAG application. The resulting system will be a Hybrid RAG system (RAG using fine-tuned models) as described in this article.
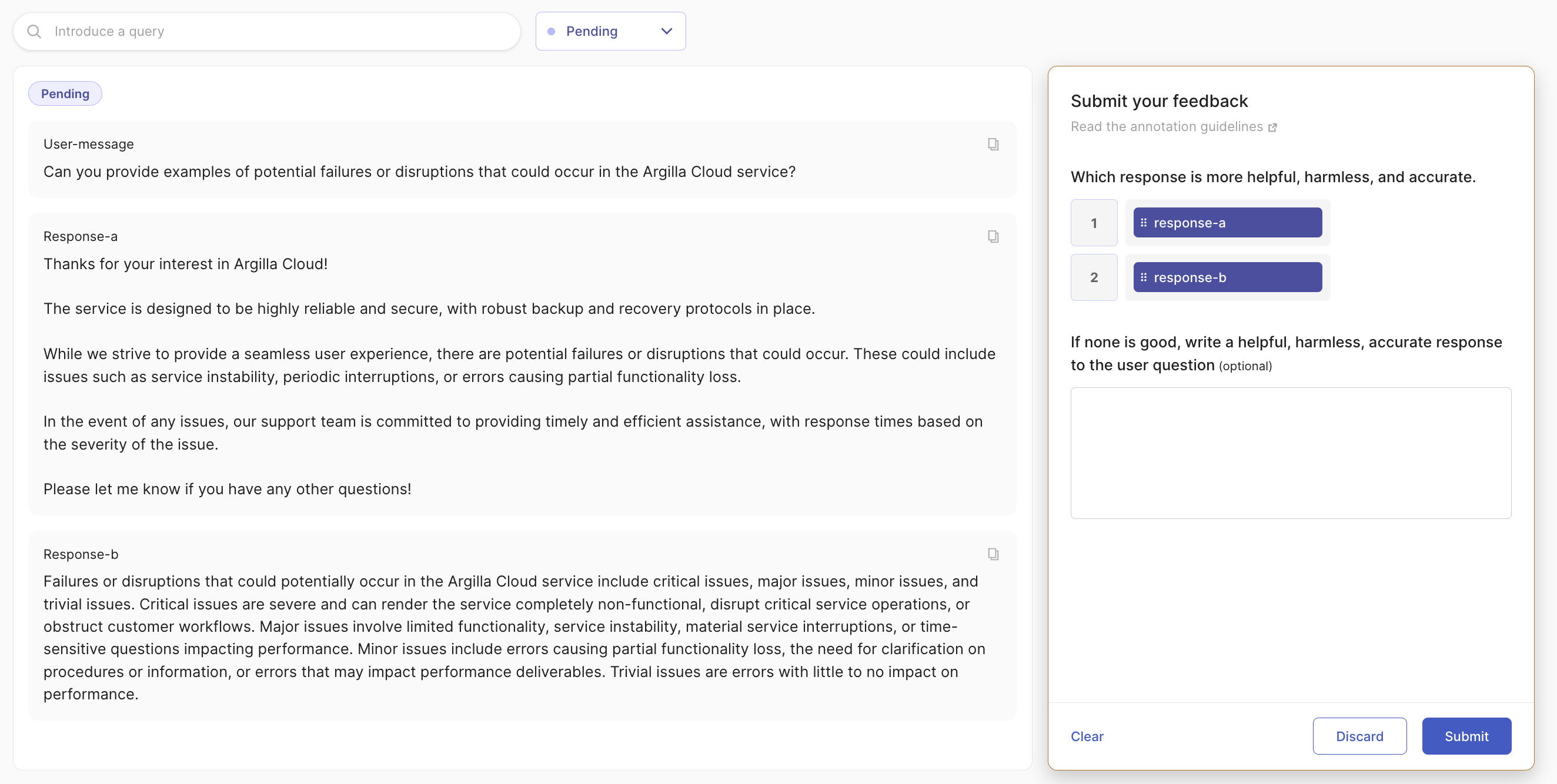
The screenshot below displays the evaluation dataset, termed the “human preference dataset.” In it, response-a is produced by the fine-tuned model, while response-b comes from the base GPT-3.5 model. With just minor fine-tuning and without altering the system message, we’ve directed the LLM’s behavior towards generating responses that are more helpful, faithful, friendly, and aligned with our brand.
Fine-tuning effectively mitigates common RAG challenges, like the LLM referring to the context using phrases such as “The context does not provide information about this.” This enhancement is notable even when we had incorporated directives in the system message to deter such references, like “2. Avoid phrases such as ‘Based on the context, …’ or ‘The context information …’.” (see Llama Index default prompt later).
You can also browse the datasets hosted with Argilla Hugging Face Spaces. User and password: argilla / 12345678. The dataset for this stage is customer-assistant and for the evaluation step is finetuned-vs-base-preference.
By the end of the tutorial, you’ll be using a fine-tuned model for RAG and have a human evaluation workflow in place to continuously evaluate your LLM application (see below for a comparison of the base gpt3.5 vs. the fine-tuned gpt3.5 for this application).

Let’s get started!
Setup#
To run this tutorial, you need to install and launch Argilla, as well as some other packages.
[ ]:
%pip install argilla openai datasets llama-index unstructured -qqq
[ ]:
# Import the needed libraries
import os
import random
from tqdm import tqdm
import matplotlib.pyplot as plt
import openai
import argilla as rg
from argilla.feedback import TrainingTask
from argilla.feedback import ArgillaTrainer
from typing import Union, Tuple, List
from llama_index.core import ServiceContext, VectorStoreIndex, download_loader
from llama_index.llms.openai import OpenAI
from llama_index.core.evaluation import DatasetGenerator
from datasets import load_dataset
If you are running Argilla using the Docker quickstart image or Hugging Face Spaces, you need to init the Argilla client with the URL and API_KEY:
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
# Replace workspace with the name of your workspace
rg.init(
api_url="http://localhost:6900",
api_key="owner.apikey",
workspace="admin"
)
If you’re running a private Hugging Face Space, you will also need to set the HF_TOKEN as follows:
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# # Replace workspace with the name of your workspace
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="owner.apikey",
# workspace="admin",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
[ ]:
# Your openAI key is needed for generation and fine-tuning
os.environ['OPENAI_API_KEY'] = 'sk-...'
openai.api_key = os.environ["OPENAI_API_KEY"]
Enable Telemetry#
We gain valuable insights from how you interact with our tutorials. To improve ourselves in offering you the most suitable content, using the following lines of code will help us understand that this tutorial is serving you effectively. Though this is entirely anonymous, you can choose to skip this step if you prefer. For more info, please check out the Telemetry page.
from argilla.utils.telemetry import tutorial_running
tutorial_running()
Generating responses with LlamaIndex and GPT3.5#
We generate responses for the generated questions using this dataset about Argilla Cloud. We have generated this dataset using a source document and LlamaIndex’s question generator (see appendix about how to generate these questions).
If you want to skip this process (it will take several minutes), we have shared the resulting dataset on Hugging Face.
[ ]:
# Read our source questions
dataset = load_dataset("argilla/cloud_assistant_questions")
[ ]:
# Read and parse the document using Unstructured
UnstructuredReader = download_loader("UnstructuredReader", refresh_cache=True)
loader = UnstructuredReader()
# You can download this doc from: https://huggingface.co/datasets/argilla/cloud_assistant_questions/raw/main/argilla_cloud.txt
documents = loader.load_data("argilla_cloud.txt")
# Set up the Llama index context
gpt_35_context = ServiceContext.from_defaults(
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.3)
)
# Index the document and set up the engine
index = VectorStoreIndex.from_documents(documents, service_context=gpt_35_context)
query_engine = index.as_query_engine(similarity_top_k=2)
contexts = []
answers = []
questions = dataset["train"]["question"]
# Inference over the questions
for question in tqdm(questions):
response = query_engine.query(question)
contexts.append([x.node.get_content() for x in response.source_nodes])
answers.append(str(response))
[ ]:
# Show an example of q, a, and context
print(f"Question: {questions[0]}")
print(f"Answer: {answers[0]}")
print(f"Context: {contexts[0]}")
Question: What is the ticketing system used by Argilla for customer support?
Answer: The ticketing system used by Argilla for customer support is not specified in the given context information.
Context: ["This process ensures the client administrator has full control over their team's access and can manage their workspace efficiently.Plans The plans for the Argilla Cloud service depend on the volume of records processed, with several tiers available to suit varying needs.Each tier has a corresponding monthly and annual price, with a 10% discount applied to the annual pricing option.The tier selection and associated price will be determined by the client's selection in the Service Order Form section of the Terms of Service document.Plans are: Starter 1 Million records Base 3 Million records Medium 4 Million records Large 6 million records\n\nSupport Argilla Cloud offers comprehensive support services to address various issues that may arise during the use of our service.Support levels are categorized into four distinct tiers, based on the severity of the issue, and a separate category for feature requests.The support process, response times, and procedures differ for each category.(1) Critical Issues Critical issues are characterized by: Severe impact on the Service, potentially rendering it completely non-functional.Disruption of critical service operations or functions.Obstruction of entire customer workflows.In the case of a critical issue, Argilla will: Assign specialist(s) to correct the issue on an expedited basis.Provide ongoing communication on the status via email and/or phone, according to the customer's preference.Begin work towards identifying a temporary workaround or fix.(2) Major Issues Major issues involve: Limited functionality of the Service.Service instability with periodic interruptions.Material service interruptions in mission-critical functions.Time-sensitive questions impacting performance or deliverables to end-clients.Upon encountering a major issue, Argilla will: Assign a specialist to begin a resolution.Implement additional, escalated procedures as reasonably determined necessary by Argilla Support Services staff.(3) Minor Issues Minor issues include: Errors causing partial, non-critical functionality loss.The need for clarification on procedures or information in documentation.Errors in service that may impact performance deliverables.(4) Trivial Issues Trivial issues are characterized by: Errors in system development with little to no impact on performance.Feature Requests Feature requests involve: Requesting a product enhancement.For feature requests, Argilla will: Respond regarding the relevance and interest in incorporating the requested feature.In summary, Argilla Cloud's support services are designed to provide timely and efficient assistance for issues of varying severity, ensuring a smooth and reliable user experience.All plans include Monday to Friday during office hours (8am to 17pm CEST) with additional support upon request.The Support Channels and features of each tier are shown below:\n\nStarter: Slack Community.Severity 1 - Response time < 4 hours.Severity 2 - Response time < 8 hours.Severity 3 - Response time < 48 hours.Severity 4 not specified.Base: Ticketing System, Severity 1 - Response time < 4 hours.Severity 2 - Response time < 8 hours.Severity 3 - Response time < 24 hours.Severity 4 not specified.Medium: Ticketing System and dedicated Slack channel, Severity 1 - Response time < 4 hours.Severity 2 - Response time < 8 hours.Severity 3 - Response time < 24 hours.Severity 4 one week\n\nLarge: Ticketing System and dedicated Slack channel, Severity 1 - Response time < 4 hours.Severity 2 - Response time < 8 hours.Severity 3 - Response time < 24 hours.Severity 4 one week.Data backup and recovery plan Argilla Cloud is committed to ensuring the safety and availability of your data.Our system is designed to run six data backups per day as a standard procedure.These backups capture a snapshot of the system state at the time of the backup, enabling restoration to that point if necessary.Our Recovery Point Objective (RPO) is four hours.This means that in the event of a system failure, the maximum data loss would be up to the last four hours of data input.We achieve this by running regular backups throughout the day, reducing the time window of potential data loss.Our Recovery Time Objective (RTO) is one hour.This is the maximum acceptable length of time that your system could be down following a failure or disruption.It represents our commitment to ensuring that your services are restored as quickly as possible.In the event of a disruption, our team will first evaluate the issue to determine the best course of action.If data recovery is necessary, we will restore from the most recent backup.We will then work to identify and resolve the root cause of the disruption to prevent a recurrence.Finally, we conduct regular test restores to ensure that our backup system is working as intended.These tests verify the integrity of the backup data and the functionality of the restore process.", "This documents an overview of the Argilla Cloud service - a comprehensive Software as a Service (SaaS) solution for data labeling and curation.The service is specifically designed to meet the needs of businesses seeking a reliable, secure, and user-friendly platform for data management.The key components of our service include advanced security measures, robust data backup and recovery protocols, flexible pricing options, and dedicated customer support.The onboarding process is efficient, enabling clients to start using the service within one business day.The scope of this proposal includes details on the aforementioned aspects, providing a clear understanding of the service offerings and associated processes.Argilla Cloud offers four plans:\n\nStarter: Ideal for teams initiating their journey in scaling data curation and labelling projects.Perfect for environments where production monitoring is not a requirement.Base: Tailored for teams seeking to amplify their data curation, labelling efforts, and model monitoring, with enhanced support from Argilla.Medium: Designed for teams expanding their language model pipelines, requiring robust ML lifecycle management fortified by Argilla's comprehensive support.Large: Geared towards teams heavily dependent on language model pipelines, human feedback, and applications, requiring complete ML lifecycle management with robust support.Scope of services Argilla Cloud, a fully managed SaaS, encompasses the following functionalities: Unrestricted Users, Datasets, and Workspaces: The service imposes no limits on the number of users, datasets, or workspaces, supporting scalability of operations.Role-Based Access Control: Administrators and annotators have differentiated access rights to ensure structured and secure data management.Custom Subdomain: Clients are provided with a distinct argilla.io subdomain for accessing the platform.Regular Updates and Upgrades: The service includes regular platform patches and upgrades as part of routine maintenance to uphold system integrity and security.Managed Service: Infrastructure maintenance, backend operations, and other technical aspects are managed by Argilla, eliminating the need for client-side management.Security The security framework of the Argilla Cloud service involves a multi-faceted approach: Data Encryption at Rest: Data stored within the system is encrypted, forming a crucial layer of security.This process automatically encrypts data prior to storage, guarding against unauthorized access.Network Security Measures: The infrastructure has been designed to prevent unauthorized intrusion and to ensure consistent service availability.Measures include firewall protections, intrusion detection systems, and scheduled vulnerability scans to detect and address potential threats.Role-Based Access Control: The system implements role-based access control, defining access levels based on user roles.This mechanism controls the extent of access to sensitive information, aligning it with the responsibilities of each role.Security Audits: Regular audits of security systems and protocols are conducted to detect potential vulnerabilities and verify adherence to security standards.Employee Training: All personnel receive regular security training, fostering an understanding of the latest threats and the importance of security best practices.Incident Response Protocol: In the case of a security incident, a pre-defined incident response plan is activated.This plan outlines the procedures for managing different types of security events, and aims to ensure swift mitigation of potential damage.In summary, the security measures in place include data encryption, network security protocols, role-based access control, regular audits, employee training, and a comprehensive incident response plan.These measures contribute to a secure environment for data management.Setup and onboarding The process for setup and onboarding for Argilla Cloud is designed to be efficient and straightforward.The procedure involves a sequence of steps to ensure a smooth transition and optimal use of the service.Step 1: Account Creation The setup process begins with the creation of the client owner account.We require the client to provide the following details: Full name of the administrator Preferred username Administrator's email address Once these details are received, we send an onboarding email to sign up.Step 2: Platform Orientation Once logged in, the administrator has full access to the Argilla Cloud platform.They can familiarize themselves with the platform interface and various features.If required, a guided tour or tutorial can be provided to walk the administrator through the platform.Step 3: User Management The administrator is then responsible for setting up additional user accounts.They can invite users via email, manage roles (admin, annotator, etc.), and assign access permissions to different workspaces and datasets.Step 4: Workspace and Dataset Configuration The administrator can create and manage multiple workspaces and datasets.They have the option to configure settings as per their team's requirements, including assigning datasets to specific workspaces and managing access permissions.Step 5: Training and Support Argilla provides open resources and support to aid in the onboarding process.This includes user manuals, tutorials, and access to our support team for any queries or issues that may arise during the setup and onboarding process.By following these steps, new users can be quickly onboarded and begin using the Argilla Cloud service with minimal downtime."]
Create Argilla dataset and collect feedback#
We set up an Argilla Dataset for gathering human feedback.
For fine-tuning, we need to set up a text question to gather the human written or edited responses. This data is known as completion or demonstration data.
Additionally, leveraging the multi-aspect feedback capabilities of Argilla, we set up two additional feedback dimensions to rate the relevance of the question (as they’re synthetic they might be irrelevant or bad quality) and the quality of the context retrieved from our retriever component (can be used to improve the RAG configuration).
[ ]:
dataset = rg.FeedbackDataset(
fields=[rg.TextField(name="user-message"), rg.TextField(name="context")],
questions=[
rg.RatingQuestion(name="question-rating", title="Rate the relevance of the user question", values=[1,2,3,4,5], required=False),
rg.RatingQuestion(name="context-rating", title="Rate the quality and relevancy of context for the assistant", values=[1,2,3,4,5], required=False),
rg.TextQuestion(name="response", title="Write a helpful, harmless, accurate response to the user question"),
]
)
We use the questions, context, and generated responses to build our feedback records. We pre-fill the responses in the UI with OpenAI’s responses using suggestions and ask our labelers to edit them if necessary.
[ ]:
records = []
for question, answer, context in tqdm(zip(questions, answers, contexts), total=len(questions)):
# Instantiate the FeedbackRecord
feedback_record = rg.FeedbackRecord(
fields={"user-message": question, "context": "\n".join(context)},
suggestions=[
{
"question_name": "response",
"value": answer,
}
]
)
records.append(feedback_record)
# Publish dataset in Argilla UI
dataset = dataset.push_to_argilla(name="customer_assistant", workspace="admin")
dataset.add_records(records)
# Optional: store and version dataset in the Hub
#dataset = dataset.push_to_huggingface("argilla/rg_customer_assistant")
Now, the dataset is available for collecting feedback with the Argilla UI. Here’s a video showing the workflow for labelers:
Prepare Argilla dataset for fine-tuning#
We now read the responses from Argilla and prepare the dataset for fine-tuning following the fine-tuning format from OpenAI guides.
We use the quick adaptation of LlamaIndex’s TEXT_QA_PROMPT system prompt and the fine-tuned responses from our Argilla dataset.
[ ]:
# Read the dataset from Argilla
dataset = rg.FeedbackDataset.from_argilla("customer_assistant", workspace="admin")
If you have skipped the previous steps run this to get the pre-built dataset.
dataset = rg.FeedbackDataset.from_huggingface("argilla/customer_assistant")
[ ]:
# Adaptation from LlamaIndex's TEXT_QA_PROMPT_TMPL_MSGS[1].content
user_message_prompt ="""Context information is below.
---------------------
{context_str}
---------------------
Given the context information and not prior knowledge but keeping your Argilla Cloud assistant style, answer the query.
Query: {query_str}
Answer:
"""
# Adaptation from LlamaIndex's TEXT_QA_SYSTEM_PROMPT
system_prompt = """You are an expert customer service assistant for the Argilla Cloud product that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like 'Based on the context, ...' or 'The context information ...' or anything along those lines.
"""
[ ]:
def formatting_func(sample: dict) -> Union[Tuple[str, str, str, str], List[Tuple[str, str, str, str]]]:
from uuid import uuid4
if sample["response"]:
chat = str(uuid4())
user_message = user_message_prompt.format(context_str=sample["context"], query_str=sample["user-message"])
return [
(chat, "0", "system", system_prompt),
(chat, "1", "user", user_message),
(chat, "2", "assistant", sample["response"][0]["value"])
]
task = TrainingTask.for_chat_completion(formatting_func=formatting_func)
Fine-tune GPT3.5 with high-quality feedback#
We fine-tune gpt-3.5-turbo with the exported dataset using the Argilla Trainer.
[ ]:
trainer = ArgillaTrainer(
dataset=dataset,
task=task,
framework="openai",
)
trainer.train(output_dir="my-ft-openai-model")
Evaluating base vs fine-tuned with human preference data#
We set up a new feedback dataset for gathering human feedback to evaluate the fine-tuned model against the base model, using the test dataset.
There are many ways to collect feedback for this phase. The most suitable in this case is human preference data over responses from the two models: asking our labelers which response is the most accurate and helpful. We can easily do this with Argilla’s RankingQuestion.
Additionally, as both responses can be equally bad, we can ask labelers to write down a correct response. In this case, we would be collecting demonstration data to add to our fine-tuning workflow.
Create dataset and collect feedback#
We set up and publish a new dataset with a RankingQuestion and TextQuestion, showing our labelers the user-message and two responses (from the base and the fine-tuned models).
[ ]:
dataset = rg.FeedbackDataset(
fields=[rg.TextField(name="user-message"), rg.TextField(name="response-a"), rg.TextField(name="response-b")],
questions=[
rg.RankingQuestion(name="preference", title="Which response is more helpful, harmless, and accurate.", values=["response-a", "response-b"]),
rg.TextQuestion(name="response", title="If none is good, write a helpful, harmless, accurate response to the user question", required=False),
]
)
[ ]:
# Read our test questions
questions = load_dataset("argilla/cloud_assistant_questions", split="test")["question"]
[ ]:
# Generate responses with base model
index = VectorStoreIndex.from_documents(documents, service_context=gpt_35_context)
query_engine = index.as_query_engine(similarity_top_k=2)
contexts = []
base_model_responses = []
for question in tqdm(questions):
response = query_engine.query(question)
base_model_responses.append(str(response))
[ ]:
# Generate responses with ft model: replace with the id of your ft model
ft_context = ServiceContext.from_defaults(
llm=OpenAI(model="ft:gpt-3.5-turbo-...", temperature=0.3)
)
index = VectorStoreIndex.from_documents(documents, service_context=ft_context)
query_engine = index.as_query_engine(similarity_top_k=2)
contexts = []
ft_model_responses = []
for question in tqdm(questions):
response = query_engine.query(question)
ft_model_responses.append(str(response))
An important step here is to randomize the order in which responses are shown.
If we show the fine-tuned model response always as the first option, we can introduce position bias (labelers always choosing a certain position) or make it evident to users that there are two obviously different models.
To avoid this, we randomize the position and keep two metadata fields indicating which model has produced response-a and response-b. When collecting the responses, we’ll use this metadata to map the ranking with each model.
[ ]:
records = []
for base, ft, question in zip(base_model_responses, ft_model_responses, questions):
# Randomizing the position is a highly important step to mitigate labeler biases
# Shuffle the order of base and ft
response_a, response_b = random.sample([base, ft], 2)
# Map the responses back to their model names
models = {
base: "base_model",
ft: "ft_model"
}
feedback_record = rg.FeedbackRecord(
fields={"user-message": question, "response-a": response_a, "response-b": response_b},
metadata={"response-a-model": models[response_a], "response-b-model": models[response_b]}
)
records.append(feedback_record)
dataset = dataset.push_to_argilla(name="finetuned-vs-base-preference", workspace="admin")
dataset.add_records(records)
Now, the dataset is available for collecting feedback with the Argilla UI. Here’s a video showing the workflow for labelers:
Retrieve and analyze responses#
We can dynamically collect the responses from our labelers. In this case, we will compute the win rate and ties (as users can indicate both responses are equally good or bad).
For the tutorial, we only have one user but Argilla Feedback is fully multi-user, which means you can collect feedback from several users for each data point, increasing the quality of the evaluation.
You can read more about multi-user scenarios and built-in unification methods on this guide.
With a very small evaluation set, we can see that the fine-tuned model responses are preferred ~60% of the time, 3x over the base model, and they are both equally good or bad ~20% of the time.
Even with a very small fine-tuning and evaluation dataset, this already shows promising benefits of fine-tuning models for enhancing RAG systems.
[ ]:
# Retrieve the dataset from Argilla
dataset = rg.FeedbackDataset.from_argilla(name="finetuned-vs-base-preference", workspace="admin")
win_rates = {
'ft_model': 0,
'base_model': 0,
'tie': 0
}
# Compute the win and tie rates
for record in dataset.records:
if len(record.responses) > 0:
for response in record.responses:
model_a = record.metadata["response-a-model"]
model_b = record.metadata["response-b-model"]
preference = response.values['preference'].value
if preference[0].rank > preference[1].rank:
win_rates[model_a] = win_rates[model_a] + 1
elif preference[1].rank > preference[0].rank:
win_rates[model_b] = win_rates[model_b] + 1
else:
win_rates['tie'] = win_rates['tie'] + 1
win_rates
# {'ft_model': 17, 'base_model': 6, 'tie': 5}
[ ]:
# Let's make the labels more explicit
data = {'gpt3.5-fine-tuned': 17, 'gpt3.5-base': 6, 'tie': 5}
total = sum(data.values())
# Calculate percentages
percentages = [value / total * 100 for value in data.values()]
# Settings
colors = ['blue', 'grey', 'black']
labels = [f"{key} ({value:.2f}%)" for key, value in zip(data.keys(), percentages)]
# Plotting
plt.figure(figsize=(12, 2))
# The cumulative percentage is used to shift the starting point of each subsequent segment
cumulative_percentages = 0
for percent, color, label in zip(percentages, colors, labels):
plt.barh('Models', percent, color=color, label=label, left=cumulative_percentages)
plt.text(cumulative_percentages + percent/2, 0, label, ha='center', va='center', color='white', fontsize=10)
cumulative_percentages += percent
plt.gca().axes.get_yaxis().set_visible(False)
plt.xlim(0, 100)
plt.title('Model Win Rates')
plt.legend(loc="upper center", bbox_to_anchor=(0.5, -0.25), ncol=3)
plt.tight_layout()
# Display
plt.show()
Appendix: Generating questions with Llama Index#
We use the DatasetGenerator from Llama Index to generate a set of questions using a document about Argilla Cloud.
[ ]:
UnstructuredReader = download_loader("UnstructuredReader", refresh_cache=True)
loader = UnstructuredReader()
# You can download this doc from: https://huggingface.co/datasets/argilla/cloud_assistant_questions/raw/main/argilla_cloud.txt
documents = loader.load_data("argilla_cloud.txt")
gpt_35_context = ServiceContext.from_defaults(
llm=OpenAI(model="gpt-3.5-turbo", temperature=0.4),
chunk_size=60
)
[ ]:
question_gen_query = (
"You are customer support and sales expert of Argilla. Your task is to setup "
"a set of frequently asked questions about the Argilla Cloud service, offer and plans"
"formulate a single question that could be asked by a potential B2B client interested in Argilla Cloud "
". Restrict the question to the context information provided and don't ask general questions not related to the service and the context provided."
)
dataset_generator = DatasetGenerator.from_documents(
documents,
question_gen_query=question_gen_query,
service_context=gpt_35_context,
num_questions_per_chunk=100
)
questions = dataset_generator.generate_questions_from_nodes(num=300)