Workflow other datasets#
Welcome! This will cover a default workflow from logging data to preparing for training.
info
This workflow covers the FeedbackDataset. The workflow for the DatasetForTextClassification, DatasetForTokenClassification, and DatasetForText2Text can be found here. Not sure which dataset to use? Check out our section on choosing a dataset.
Install Libraries#
Install Argilla lastest version in Colab, along with other libraries and models used in this notebook.
[ ]:
!pip install argilla datasets transformers evaluate spacy-transformers transformers[torch]
!python -m spacy download de_core_news_sm
Set Up Argilla#
You can quickly deploy Argilla Server on HF Spaces.
Alternatively, if you want to run Argilla locally on your own computer, the easiest way to get Argilla UI up and running is to deploy on Docker:
docker run -d --name quickstart -p 6900:6900 argilla/argilla-quickstart:latest
More info on Installation here.
Connect to Argilla#
It is possible to connect to our Argilla instance by simply importing Argilla library, which internally connects to Argilla Server using the ARGILLA_API_URL and ARGILLA_API_KEY environment variables.
[ ]:
import os
#set your variable here
os.environ["ARGILLA_API_URL"] = "your_argilla_URL"
os.environ["ARGILLA_API_KEY"] = "owner.apikey"
[ ]:
import argilla as rg
rg.init(workspace="admin")
"owner.apikey" is the default value for ARGILLA_API_KEY variable.
admin is the name of default workspace. A workspace is a “space” inside your Argilla instance where authorized users can collaborate.
If you want to initialize a connection manually you can use rg.init(). For more info about custom configurations like headers and workspace separation, check our config page.
If you want to customize the access credentials, take a look at our user management section.
Upload data#
The main component of the Argilla data model is called a record. Records can be of different types depending on the currently supported tasks:
TextClassificationRecordTokenClassificationRecordText2TextRecord
The most critical attributes of a record that are common to all types are:
text: The input text of the record (Required);annotation: Annotate your record in a task-specific manner (Optional);prediction: Add task-specific model predictions to the record (Optional);metadata: Add some arbitrary metadata to the record (Optional);
A Dataset in Argilla is a collection of records of the same type.
[ ]:
# Create a basic text classification record
textcat_record = rg.TextClassificationRecord(
text="Hello world, this is me!",
prediction=[("LABEL1", 0.8), ("LABEL2", 0.2)],
annotation="LABEL1",
multi_label=False,
)
# Create a basic token classification record
tokencat_record = rg.TokenClassificationRecord(
text="Michael is a professor at Harvard",
tokens=["Michael", "is", "a", "professor", "at", "Harvard"],
prediction=[("NAME", 0, 7), ("LOC", 26, 33)],
)
# Create a basic text2text record
text2text_record = rg.Text2TextRecord(
text="My name is Sarah and I love my dog.",
prediction=["Je m'appelle Sarah et j'aime mon chien."],
)
# Upload (log) the records to corresponding datasets in the Argilla web app
rg.log(textcat_record, "my_textcat_dataset")
rg.log(tokencat_record, "my_tokencat_dataset")
rg.log(tokencat_record, "my_text2text_dataset")
Now you can access your datasets in the Argilla web app and look at your first records.
However, most of the time, you will have your data in some file format, like TXT, CSV, or JSON. Argilla relies on two well-known Python libraries to read these files: pandas and datasets. After reading the files with one of those libraries, Argilla provides shortcuts to create your records automatically.
Let’s look at a few examples for each of the record types.
As mentioned earlier, you choose the record type depending on the task you want to tackle.
1. TextClassification#
In this example, we will read a CSV file from a Kaggle competition that contains reviews for the Snapchat app. The underlying task here could be to classify the reviews by their sentiment.
Let us read the file with pandas
Note
If the file is too big to fit in memory, try using the datasets library with no memory constraints, as shown in the next section.
[ ]:
import pandas as pd
# Read the CSV file into a pandas DataFrame
dataframe = pd.read_csv("Snapchat_app_store_reviews.csv")
and have a quick look at the first three rows of the resulting pandas DataFrame:
[ ]:
dataframe.head(3)
| Unnamed: 0 | userName | rating | review | isEdited | date | title | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | Savvanananahhh | 4 | For the most part I quite enjoy Snapchat it’s ... | False | 10/4/20 6:01 | Performance issues |
| 1 | 1 | Idek 9-101112 | 3 | I’m sorry to say it, but something is definite... | False | 10/14/20 2:13 | What happened? |
| 2 | 2 | William Quintana | 3 | Snapchat update ruined my story organization! ... | False | 7/31/20 19:54 | STORY ORGANIZATION RUINED! |
We will choose the review column as input text for our records. For Argilla to know, we must rename the corresponding column to text.
We will choose the rating column as label. For Argilla to know, we must rename the corresponding column to annotation.
Other columns can be conveniently wrapped in a dictionary and mapped as metadata column, as expected by the TextClassificationRecord class.
[ ]:
#wrap metadata in a dictionary
def metadata_to_dict(dataframe):
metadata = {}
metadata["userName"] = dataframe["userName"]
metadata["isEdited"] = dataframe["isEdited"]
metadata["date"] = dataframe["date"]
metadata["title"] = dataframe["title"]
return metadata
dataframe["metadata"] = dataframe.apply(metadata_to_dict, axis=1)
# Drop unused the columns
dataframe = dataframe.drop(
["Unnamed: 0", "userName", "isEdited", "date", "title"],
axis=1
)
# Rename the 'review' column to 'text',
dataframe = dataframe.rename(
columns={"review": "text", "rating":"annotation"}
)
dataframe.head()
| annotation | text | metadata | |
|---|---|---|---|
| 0 | 4 | For the most part I quite enjoy Snapchat it’s ... | {'userName': 'Savvanananahhh', 'isEdited': Fal... |
| 1 | 3 | I’m sorry to say it, but something is definite... | {'userName': 'Idek 9-101112', 'isEdited': Fals... |
| 2 | 3 | Snapchat update ruined my story organization! ... | {'userName': 'William Quintana', 'isEdited': F... |
| 3 | 5 | I really love the app for how long i have been... | {'userName': 'an gonna be unkown😏', 'isEdited'... |
| 4 | 1 | This is super frustrating. I was in the middle... | {'userName': 'gzhangziqi', 'isEdited': False, ... |
We can now read this DataFrame with Argilla, which will automatically create the records and put them in a Dataset
[ ]:
import argilla as rg
# Read DataFrame into a Argilla Dataset
dataset_rg = rg.read_pandas(dataframe, task="TextClassification")
We will upload this dataset to the web app and give it the name snapchat_reviews
[ ]:
# Upload (log) the Dataset to the web app
rg.log(dataset_rg, "snapchat_reviews")
You can configure labels programmatically by using configure_dataset_settings method:
[ ]:
labels = ["1", "2", "3", "4" , "5"]
settings = rg.TextClassificationSettings(label_schema=labels)
rg.configure_dataset_settings(name="snapchat_reviews", settings=settings)
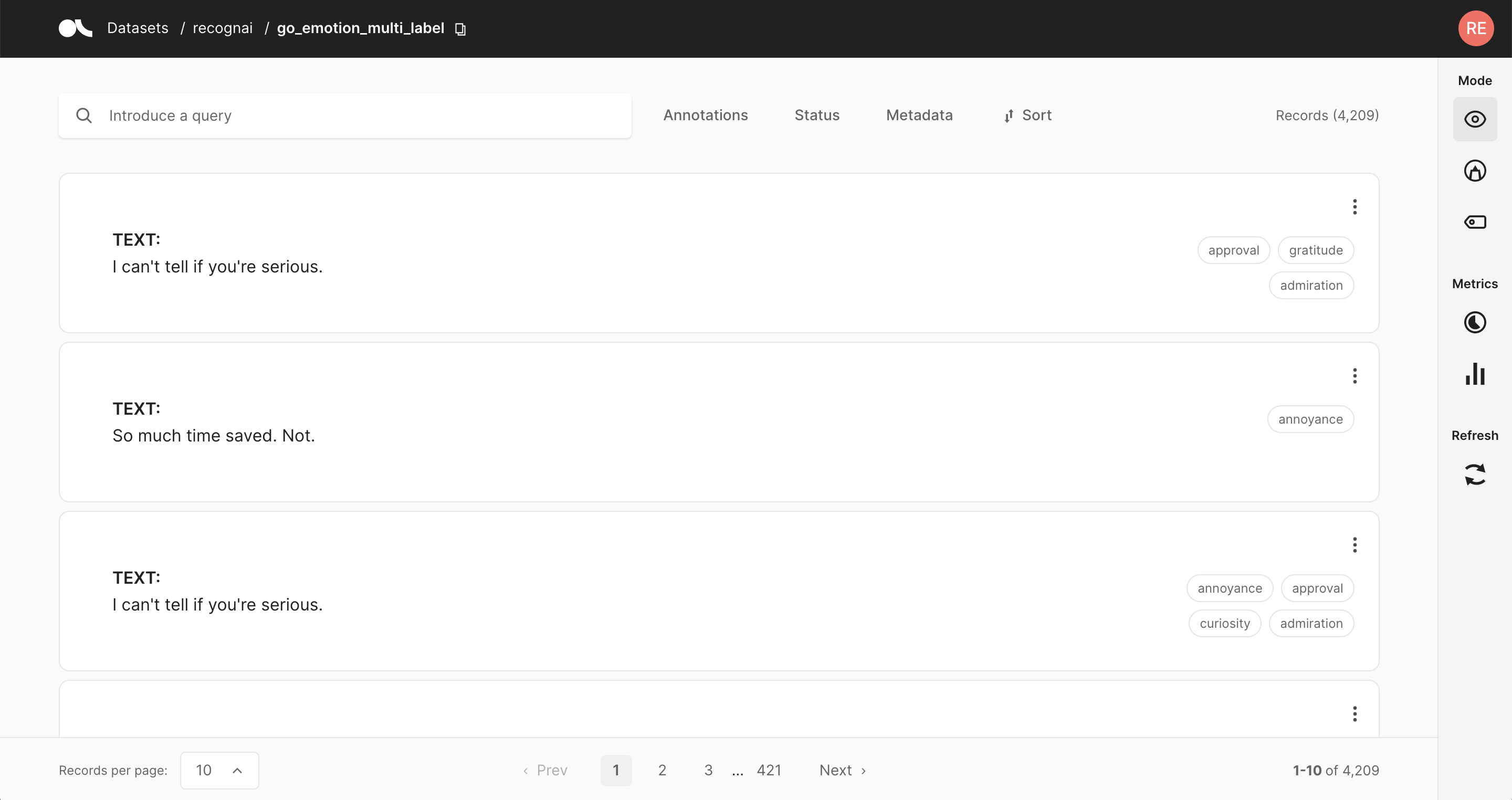
2. TokenClassification#
We will use German reviews of organic coffees in a CSV file for this example. The underlying task here could be to extract all attributes of an organic coffee.
This time, let’s read the file with datasets.
[ ]:
from datasets import Dataset
# Read the csv file
dataset = Dataset.from_csv("kaffee_reviews.csv")
and have a quick look at the first three rows of the resulting dataset Dataset:
[ ]:
# The best way to visualize a Dataset is actually via pandas
dataset.select(range(3)).to_pandas()
| Unnamed: 0 | brand | rating | review | |
|---|---|---|---|---|
| 0 | 0 | GEPA Kaffee | 5 | Wenn ich Bohnenkaffee trinke (auf Arbeit trink... |
| 1 | 1 | GEPA Kaffee | 5 | Für mich ist dieser Kaffee ideal. Die Grundvor... |
| 2 | 2 | GEPA Kaffee | 5 | Ich persönlich bin insbesondere von dem Geschm... |
We will choose the review column as input text for our records. For Argilla to know, we have to rename the corresponding column to text.
Other columns can be conveniently wrapped in a dictionary and mapped as metadata column as expected by the TokenClassificationRecord class.
[ ]:
#wrap metadata in a dictionary
def metadata_to_dict(row):
metadata = {}
metadata["brand"] = row["brand"]
metadata["rating"] = row["rating"]
row['metadata'] = metadata
return row
dataset = dataset.map(metadata_to_dict, remove_columns=["Unnamed: 0","brand","rating"])
dataset = dataset.rename_column("review", "text")
dataset.select(range(3)).to_pandas()
In contrast to the other types, token classification records need the input text and the corresponding tokens. So let us tokenize our input text in a small helper function and add the tokens to a new column called tokens.
Note
We will use spaCy to tokenize the text, but you can use whatever library you prefer.
[ ]:
import spacy
# Load a german spaCy model to tokenize our text
nlp = spacy.load("de_core_news_sm")
# Define our tokenize function
def tokenize(row):
tokens = [token.text for token in nlp(row["text"])]
return {"tokens": tokens}
# Map the tokenize function to our dataset
dataset = dataset.map(tokenize)
Let us have a quick look at our extended Dataset:
[ ]:
dataset.select(range(3)).to_pandas()
| text | metadata | tokens | |
|---|---|---|---|
| 0 | Wenn ich Bohnenkaffee trinke (auf Arbeit trink... | {'brand': 'GEPA Kaffee', 'rating': 5} | [Wenn, ich, Bohnenkaffee, trinke, (, auf, Arbe... |
| 1 | Für mich ist dieser Kaffee ideal. Die Grundvor... | {'brand': 'GEPA Kaffee', 'rating': 5} | [Für, mich, ist, dieser, Kaffee, ideal, ., Die... |
| 2 | Ich persönlich bin insbesondere von dem Geschm... | {'brand': 'GEPA Kaffee', 'rating': 5} | [Ich, persönlich, bin, insbesondere, von, dem,... |
We can now read this Dataset with Argilla, which will automatically create the records and put them in a Argilla Dataset.
[ ]:
# Read Dataset into a Argilla Dataset
dataset_rg = rg.read_datasets(dataset, task="TokenClassification")
We will upload this dataset to the web app and give it the name coffee_reviews
[ ]:
# Log the dataset to the Argilla web app
rg.log(dataset_rg, "coffee-reviews")
You can create labels in Dataset:nbsphinx-math:`Settings` and start annotating:
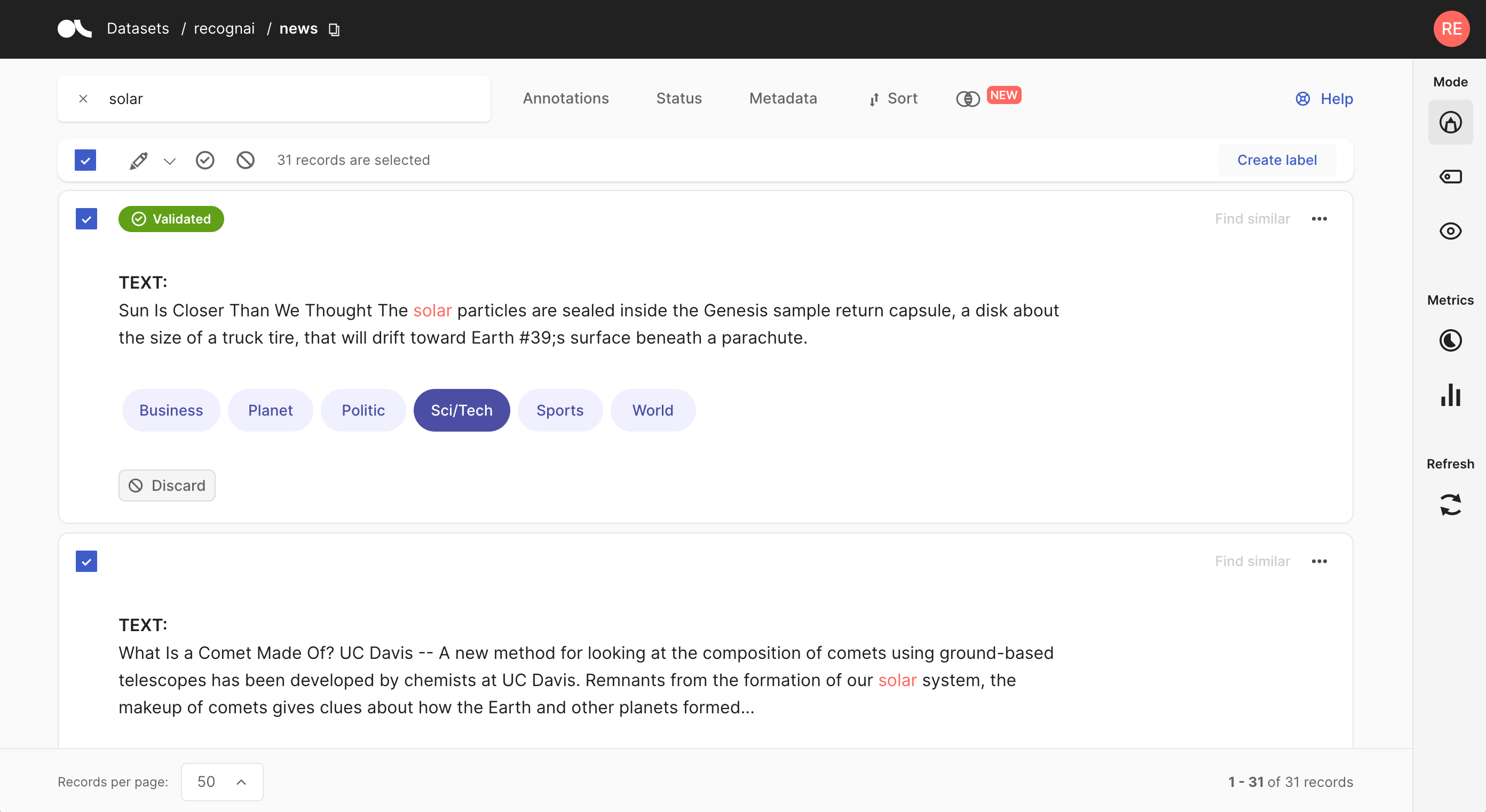
3. Text2Text#
In this example, we will use English sentences from the European Center for Disease Prevention and Control available at the Hugging Face Hub. The underlying task here could be to translate the sentences into other European languages.
Let us load the data with datasets from the Hub.
[ ]:
from datasets import load_dataset
# Load the Dataset from the Hugging Face Hub and extract the train split
dataset = load_dataset("europa_ecdc_tm", "en2fr", split="train")
and have a quick look at the first row of the resulting dataset Dataset:
[ ]:
dataset[0]
{'translation': {'en': 'Vaccination against hepatitis C is not yet available.',
'fr': 'Aucune vaccination contre l’hépatite C n’est encore disponible.'}}
We can see that the English sentences are nested in a dictionary inside the translation column.
To extract English sentences into a new text column we will write a quick helper function and map the whole Dataset with it.
French sentences will be extracted into a new prediction column, wrapped in “[ ]”, as the prediction field of Text2TextRecord accepts a list of strings or tuples.
[ ]:
# Define our helper extract function
def extract(row):
return {"text": row["translation"]["en"], "prediction":[row["translation"]["fr"]]}
# Map the extract function to our dataset
dataset = dataset.map(extract, remove_columns = ["translation"])
Let us have a quick look at our extended Dataset:
[ ]:
dataset.select(range(3)).to_pandas()
| text | prediction | |
|---|---|---|
| 0 | Vaccination against hepatitis C is not yet ava... | [Aucune vaccination contre l’hépatite C n’est ... |
| 1 | HIV infection | [Infection à VIH] |
| 2 | The human immunodeficiency virus (HIV) remains... | [L’infection par le virus de l’immunodéficienc... |
We can now read this Dataset with Argilla, which will automatically create the records and put them in a Argilla Dataset.
[ ]:
# Read Dataset into a Argilla Dataset
dataset_rg = rg.read_datasets(dataset, task="Text2Text")
We will upload this dataset to the web app and give it the name ecdc_en
[ ]:
# Log the dataset to the Argilla web app
rg.log(dataset_rg, "ecdc_en")
Label datasets#
Argilla provides several ways to label your data. Using Argilla’s UI, you can mix and match the following options:
Manually labeling each record using the specialized interface for each task type;
Leveraging a user-provided model and validating its predictions;
Defining heuristic rules to produce “noisy labels” which can then be combined with weak supervision;
Each way has its pros and cons, and the best match largely depends on your individual use case.
Annotation guideline#
Before starting the annotation process with a team, it is important to align the different truths everyone in the team thinks they have. Because the same text is going to be annotated by multiple annotators independently or we might want to revisit an old dataset later on. Besides a set of obvious mistakes, we also often encounter uncertain grey areas. Consider the following phrase for NER-annotation Harry Potter and the prisoner of Azkaban can be interpreted in many ways. The entire phrase
is as the movie title, Harry Potter is a person, and Azkaban is location. Maybe we don´t even want to annotate fictional locations and characters. Therefore, it is important to define these assumptions beforehand and iterate over them together with the team. Take a look at this blog from our friends over at suberb.ai or this
blog from Grammarly for more context.
1. Manual labeling#
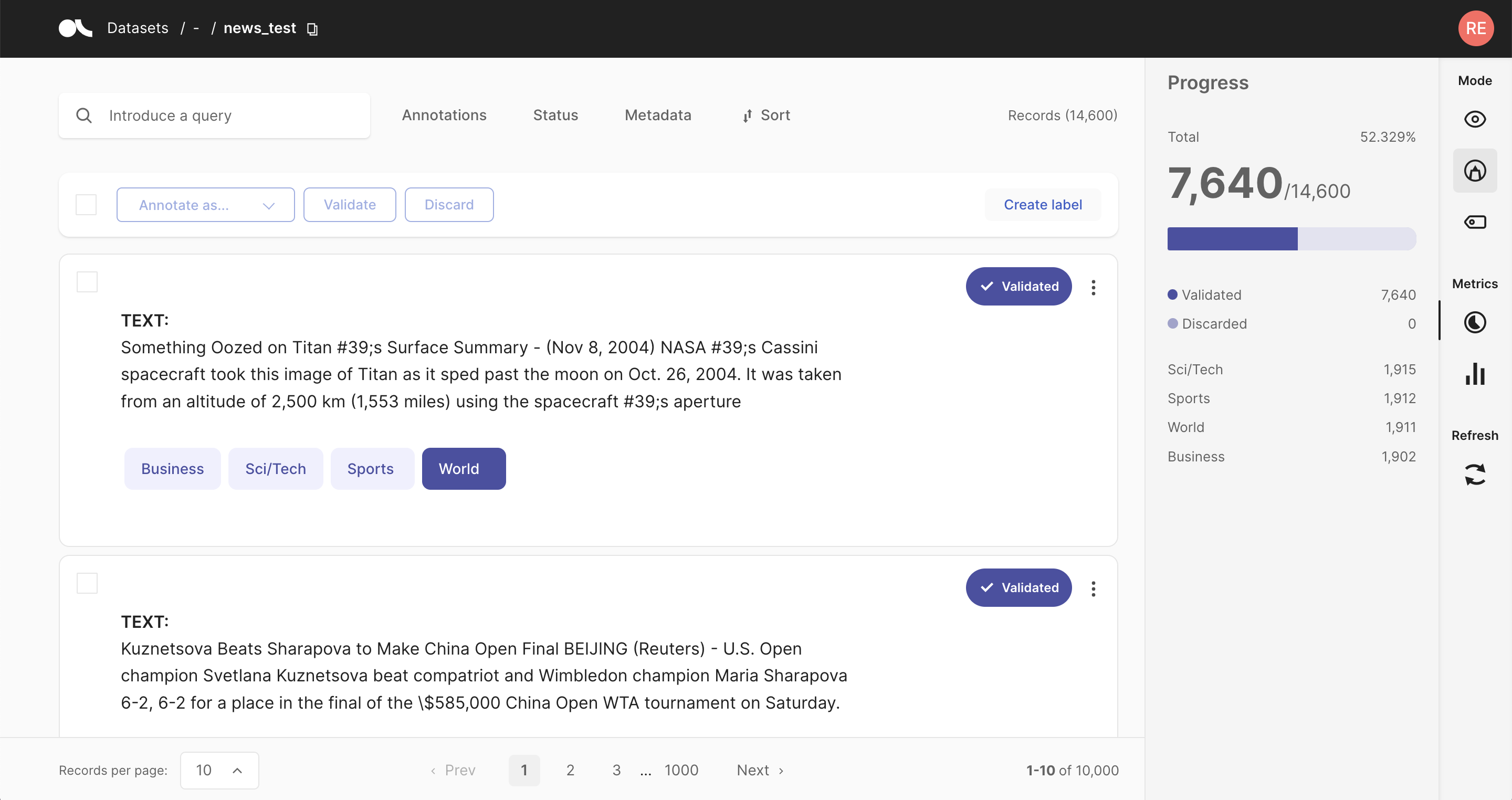
The straightforward approach of manual annotations might be necessary if you do not have a suitable model for your use case or cannot come up with good heuristic rules for your dataset. It can also be a good approach if you dispose of a large annotation workforce or require few but unbiased and high-quality labels.
Argilla tries to make this relatively cumbersome approach as painless as possible. Via an intuitive and adaptive UI, its exhaustive search and filter functionalities, and bulk annotation capabilities, Argilla turns the manual annotation process into an efficient option.
Look at our dedicated feature reference for a detailed and illustrative guide on manually annotating your dataset with Argilla.
2. Validating predictions#
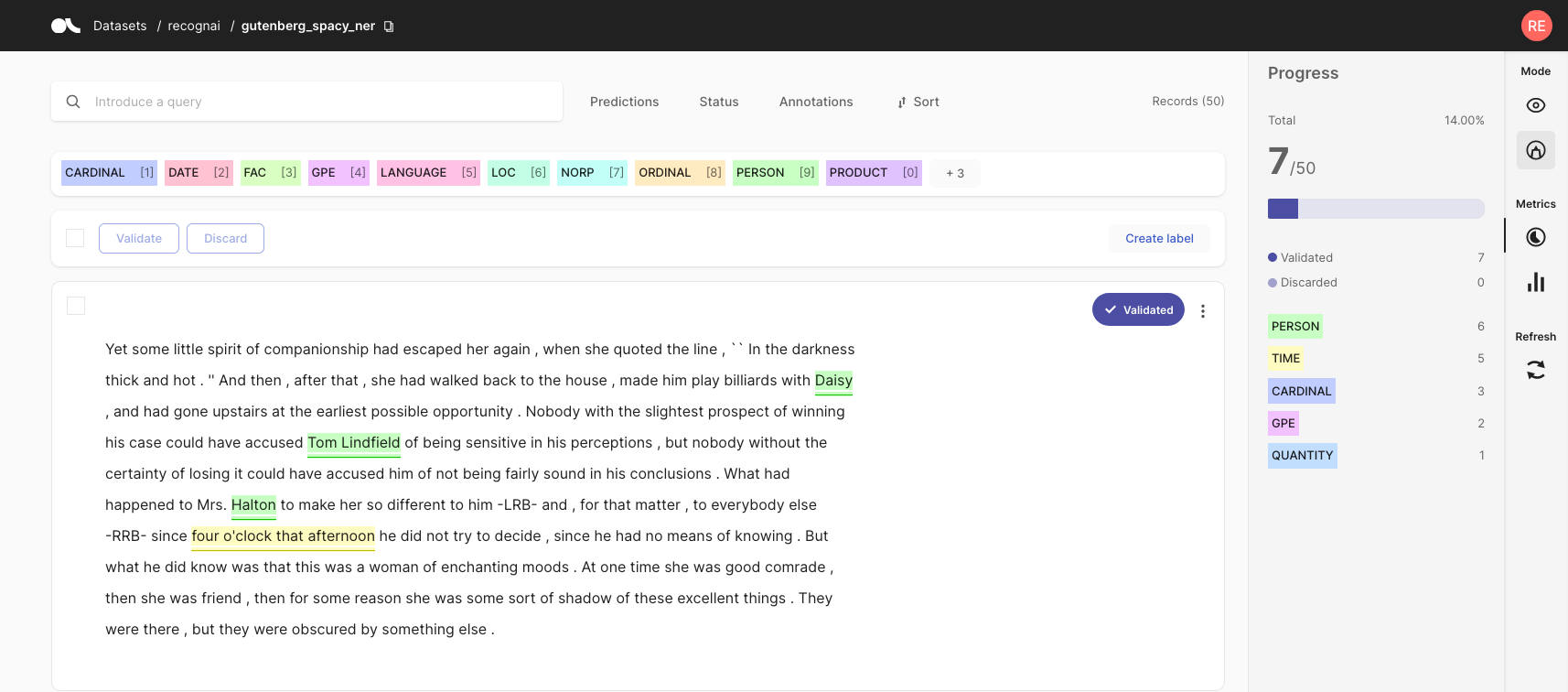
Nowadays, many pre-trained or zero-shot models are available online via model repositories like the Hugging Face Hub. Most of the time, you probably will find a model that already suits your specific dataset task to some degree. In Argilla, you can pre-annotate your data by including predictions from these models in your records. Assuming that the model works reasonably well on your dataset, you can filter for records with high prediction scores and validate the predictions. In this way, you will rapidly annotate part of your data and alleviate the annotation process.
One downside of this approach is that your annotations will be subject to the possible biases and mistakes of the pre-trained model. When guided by pre-trained models, it is common to see human annotators get influenced by them. Therefore, it is advisable to avoid pre-annotations when building a rigorous test set for the final model evaluation.
Check the introduction tutorial to learn to add predictions to the records. And our feature reference includes a detailed guide on validating predictions in the Argilla web app.
3. Weak labeling rules#
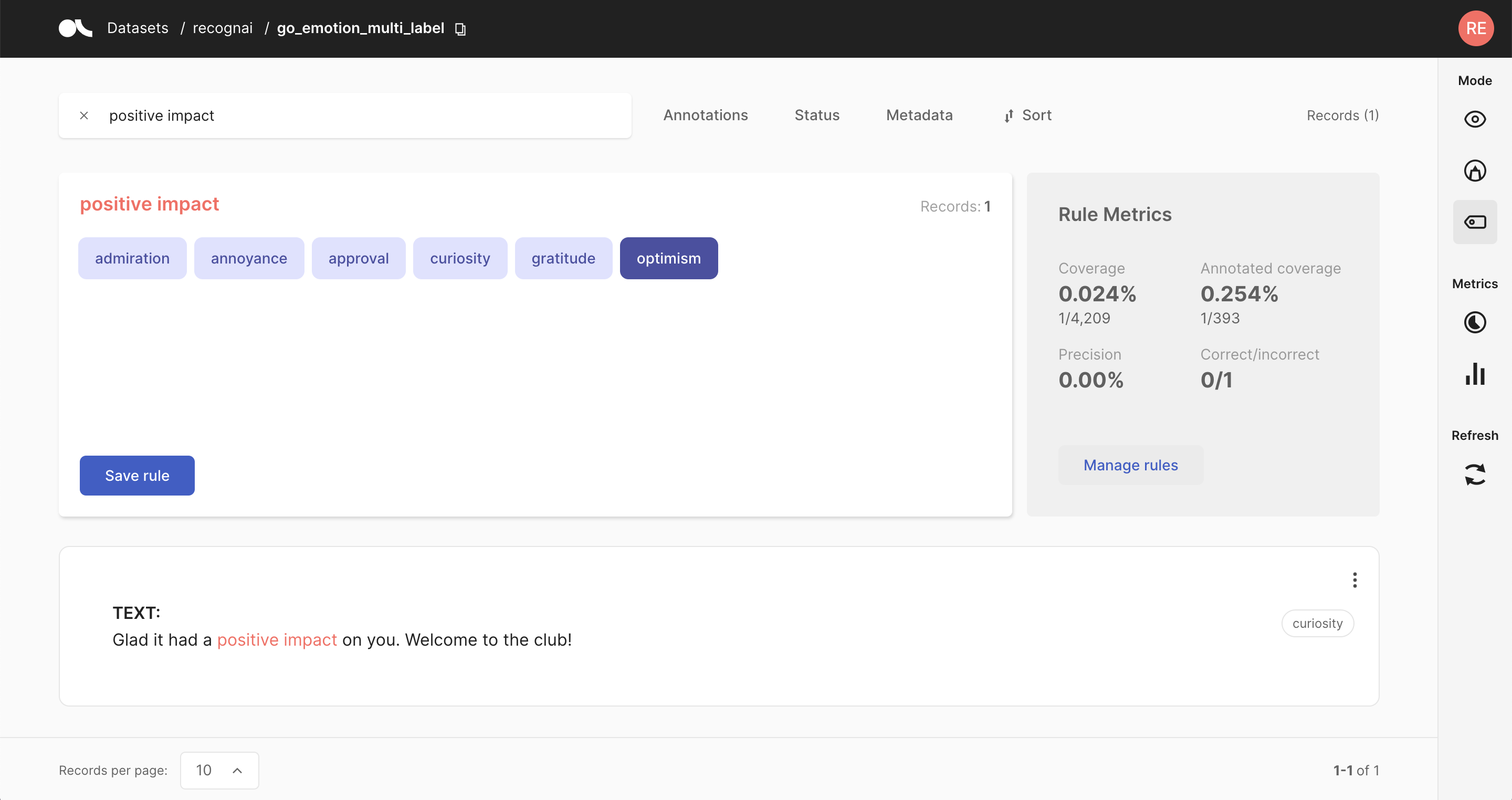
Another approach to annotating your data is to define heuristic rules tailored to your dataset. For example, let us assume you want to classify news articles into the categories of Finance, Sports, and Culture. In this case, a reasonable rule would be to label all articles that include the word “stock” as Finance.
Rules can get arbitrarily complex and can also include the record’s metadata. The downsides of this approach are that it might be challenging to come up with working heuristic rules for some datasets. Furthermore, rules are rarely 100% precise and often conflict with each other.These noisy labels can be cleaned up using weak supervision and label models, or something as simple as majority voting. It is usually a trade-off between the amount of annotated data and the quality of the labels.
Check our guide for an extensive introduction to weak supervision with Argilla. Also, check the feature reference for the Define rules mode of the web app and our various tutorials to see practical examples of weak supervision workflows.
Train a model#
The ArgillaTrainer is a wrapper around many of our favorite NLP libraries. It provides a very intuitive abstract workflow to facilitate simple training workflows using decent default pre-set configurations without having to worry about any data transformations from Argilla. More info here.
[ ]:
from argilla.training import ArgillaTrainer
sentence = "I love Snapchat, but the new update is terrible. I can't find anything anymore."
trainer = ArgillaTrainer(
name="snapchat_reviews",
workspace="admin",
framework="spacy",
train_size=0.8
)
trainer.update_config(max_epochs=2)
trainer.train(output_dir="my_easy_model")
records = trainer.predict(sentence, as_argilla_records=True)
# Print the prediction
print("\ntesting predicitons...")
print(sentence)
print(f"Predicted_label: {records.prediction}")
Argilla helps you to create and curate training data. It is not a complete framework for training a model but we do provide integrations. You can use Argilla complementary with other excellent open-source frameworks that focus on developing and training NLP models.
Here we list three of the most commonly used open-source libraries, but many more are available and may be more suited for your specific use case:
transformers: This library provides thousands of pre-trained models for various NLP tasks and modalities. Its excellent documentation focuses on fine-tuning those models to your specific use case;
spaCy: This library also comes with pre-trained models built into a pipeline tackling multiple tasks simultaneously. Since its a purely NLP library, it comes with much more NLP features than just model training;
spark-nlp: Spark NLP is an open-source text processing library for advanced natural language processing for the Python, Java and Scala programming languages. The library is built on top of Apache Spark and its Spark ML library.
scikit-learn: This de facto standard library is a powerful swiss army knife for machine learning with some NLP support. Usually, their NLP models lack the performance when compared to transformers or spacy, but give it a try if you want to train a lightweight model quickly;