Fast active learning with classy-classification#
In this tutorial, we will show you how we can use an intuitive few-shot learning package in a straightforward active learning loop. It will walk you through the following steps:
💿 load data into Argilla
⏱ train a few-shot classifier using
classy-classification🕵🏽♂️ define active learning heuristics
🔁 set-up an active-learning loop
🎥 A live demo video
Introduction#
One of the potential difficulties that arise with active learning, is the speed by which the model is able to update. Transformer models are amazing but do require a GPU to fine-tune and people do not always have access to those. Similarly, fine-tuning transformer models requires a fair amount of initial data. Luckily, classy-classification can be used to solve both of these problems!
These other active learning methods can be found here.
Let’s get started!
Setup#
Apart from Argilla, we’ll need a few third party libraries that can be installed via pip:
[ ]:
%pip install "classy-classification[onnx]==0.6.0" -qqq
%pip install "argilla[listeners]>=1.1.0" -qqq
%pip install datasets -qqq
💿 load data into Argilla#
For this analysis, we will be using our news dataset from the HuggingFace hub. This is a news classification task, which requires the texts to be classified into 4 categories: ["World", "Sports", "Sci/Tech", "Business"]. Due to the nice integration with the HuggingFace hub, we can easily do this within several lines of code.
[7]:
import argilla as rg
from datasets import load_dataset
# load from datasets
my_dataset = load_dataset("argilla/news")
dataset_rg = rg.read_datasets(my_dataset["train"], task="TextClassification")
# log subset into argilla
rg.log(dataset_rg[:500], "news-unlabelled")
500 records logged to https://pre.argilla.io/datasets/recognai/news-unlabelled
[7]:
BulkResponse(dataset='news-unlabelled', processed=500, failed=0)
Now, we have loaded the data, we can start creating some training examples for our few-shot classifier. To get a nice headstart, we will label roughly 4 labels per class within the Argilla UI.
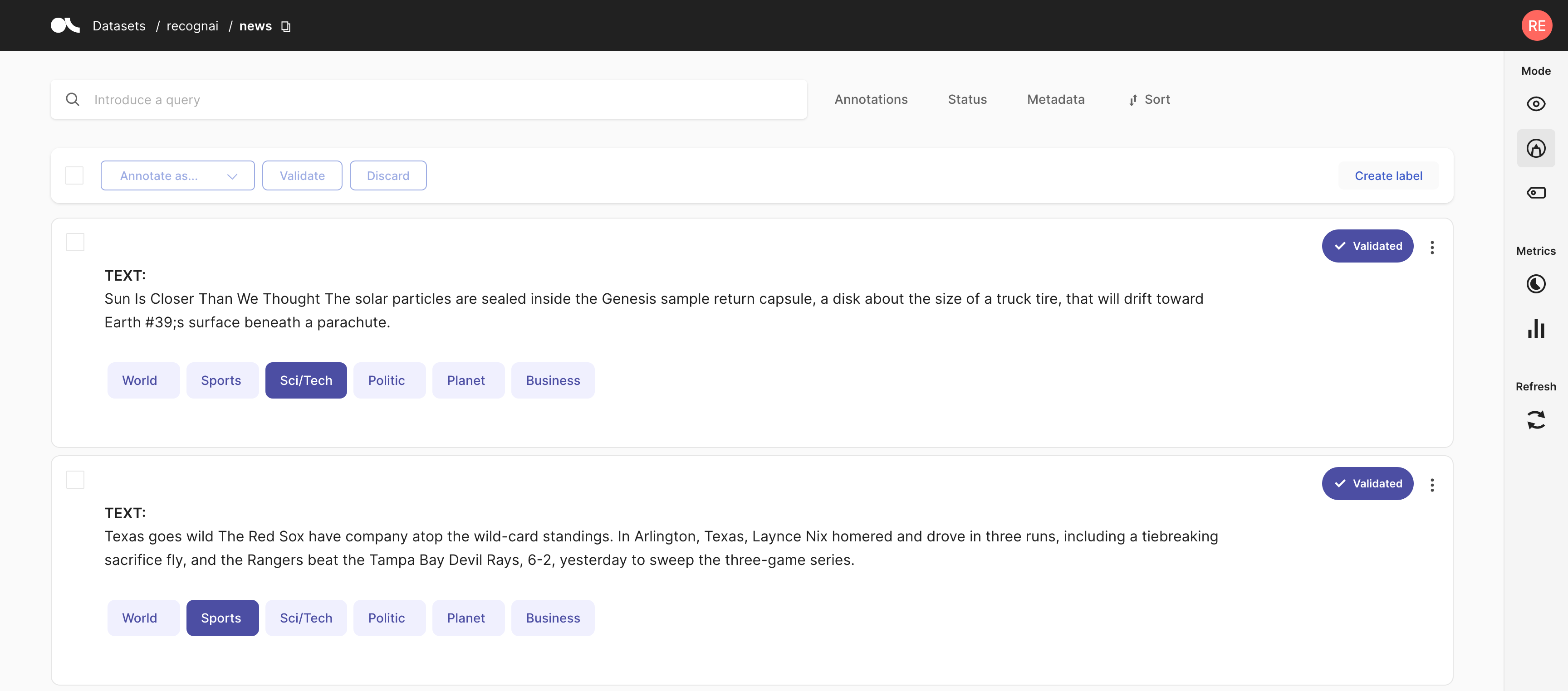
⏱ train a few-shot classifier#
Using the labelled data, we can now obtain training samples for our few-shot classifier.
[3]:
from classy_classification import ClassyClassifier
import argilla as rg
# load the dataset
train_rg = rg.load("news-unlabelled", query="status: Validated")
# Get some annotated examples per class
n_samples_per_class = 5
data = {"World": [], "Sports": [], "Sci/Tech": [], "Business": []}
while not all([len(value)== n_samples_per_class for key,value in data.items()]):
for idx, rec in enumerate(train_rg):
if len(data[rec.annotation]) < n_samples_per_class:
data[rec.annotation].append(rec.text)
# train a few-shot classifier
classifier = ClassyClassifier(data=data, model="all-MiniLM-L6-v2")
classifier("This texts is about games, goals, matches and sports.")
[3]:
{'Business': 0.2686566277246892,
'Sci/Tech': 0.2415910117784897,
'Sports': 0.22240821993980525,
'World': 0.267344140557016}
The predictions are not good yet, but they will get better once we start our active-learning loop.
🕵🏽♂️ active learning heuristics#
During an active learning loop, we want to simplify the annotation progress during each training iteration. We will do this by:
use
5samples per loop.defining a certainty threshold of
0.9, for which we will assume that the prediction can be validated automatically.infer the record prediction scores using the model from the previous loop.
check and annotate the samples that do not reach the automatic validation.
adding the annotated samples to our training data.
make predictions for a second loop of
5samples.
Throughout these loops, our predictions will produce more certain scores, which will make the annotation process easier.
[4]:
import argilla as rg
# Define heristic variables variables
NUM_SAMPLES_PER_LOOP = 5
CERTAINTY_THRESHOLD = 0.9
loop_data = data
# load input data
ds = rg.load("news-unlabelled", query="status: Default", limit=1000)
# create active learning dataset
DATASET_NAME = "news-active-learning"
try:
rg.delete(DATASET_NAME)
except Exception:
pass
settings = rg.TextClassificationSettings(label_schema=list(data.keys()))
rg.configure_dataset(name=DATASET_NAME, settings=settings)
# evalaute and update records
def evaluate_records(records, idx = 0):
texts = [rec.text for rec in records]
predictions = [list(pred.items()) for pred in classifier.pipe(texts)]
for pred, rec in zip(predictions, records):
max_score = max(pred, key=lambda item: item[1])
if max_score[1] > CERTAINTY_THRESHOLD:
rec.annotation = max_score[0]
rec.status = "Validated"
rec.prediction = pred
rec.metadata = {"idx": idx}
return records
# log initial predictions
ds_slice = evaluate_records(ds[:NUM_SAMPLES_PER_LOOP])
rg.log(ds[:NUM_SAMPLES_PER_LOOP], DATASET_NAME)
5 records logged to https://pre.argilla.io/datasets/recognai/news-active-learning
[4]:
BulkResponse(dataset='news-active-learning', processed=5, failed=0)
🔁 set-up an active-learning loop#
We will set-up the active-learning loop using Argilla Listeners. Argilla Listeners enable you to build fine-grained complex workflows as background processes, like a low-key alternative to job scheduling directly integrated with Argilla. So, they are a perfect fit for waiting on new annotations and adding logging newly inferred predictions in the background.
Note that restarting the loop, also requires a reset of the data used for the initial classifier training.
prepare
start the loop
set status filter to
Defaultvalidate the 10 initially logged record
don`t forget to refresh the record page
update the classifier with the annotated data
make predictions on new data
log predictions
annotate the second loop
[5]:
from argilla import listener
# Set up the active learning loop with the listener decorator
@listener(
dataset=DATASET_NAME,
query="(status:Validated OR status:Discarded) AND metadata.idx:{idx}",
condition=lambda search: search.total == NUM_SAMPLES_PER_LOOP,
execution_interval_in_seconds=1,
idx=0,
)
def active_learning_loop(records, ctx):
idx = ctx.query_params["idx"]
new_idx = idx+NUM_SAMPLES_PER_LOOP
print("1. train a few-shot classifier with validated data")
for rec in records:
if rec.status == "Validated":
loop_data[rec.annotation].append(rec.text)
classifier.set_training_data(loop_data)
print("2. get new record predictions")
ds_slice = ds[new_idx: new_idx+NUM_SAMPLES_PER_LOOP]
records_to_update = evaluate_records(ds_slice, new_idx)
texts = [rec.text for rec in ds_slice]
predictions = [list(pred.items()) for pred in classifier.pipe(texts)]
print("3. update query params")
ctx.query_params["idx"] = new_idx
print("4. Log the batch to Argilla")
rg.log(records_to_update, DATASET_NAME)
print("Done!")
print(f"Waiting for next {new_idx} annotations ...")
[6]:
active_learning_loop.start()
1. train a few-shot classifier with validated data
2. get new record predictions
3. update query params
4. Log the batch to Argilla
5 records logged to https://pre.argilla.io/datasets/recognai/news-active-learning
Done!
Waiting for next 5 annotations ...
🎥 A live demo video#
To show you the actual usesage from within our UI, we´ve created a live demo which you can watch underneath.
Summary#
In this tutorial, we learned how to use an active learner with Argilla and what heuristics we can apply for defining an active learner. This can help us reduce the development time required for creating a new text classification model.
Next steps#
⭐ Argilla Github repo to stay updated.
📚 Argilla documentation for more guides and tutorials.
🙋♀️ Join the Argilla community! A good place to start is the discussion forum.