🖼️ Curate an instruction dataset for supervised fine-tuning#
The internet is flooding with open-source datasets for fine-tuning LLMs, some created by humans, others generated with generative models. However, these datasets often have many problematic and low-quality examples. By curating them, we can make the fine-tuning step more efficient.
In this example, we will demonstrate how to replicate the Databricks’ Dolly dataset cleaning effort started by the Argilla community. This will show how you can build an instruction dataset for your fine-tuning projects by cleaning a public dataset using Argilla’s Feedback Task.
Let’s get started!
Note
This tutorial is a Jupyter Notebook. There are two options to run it:
Use the Open in Colab button at the top of this page. This option allows you to run the notebook directly on Google Colab. Don’t forget to change the runtime type to GPU for faster model training and inference.
Download the .ipynb file by clicking on the View source link at the top of the page. This option allows you to download the notebook and run it on your local machine or on a Jupyter notebook tool of your choice.
Setup#
For this tutorial, you will need to have an Argilla server running. If you don’t have one already, check out our Quickstart or Installation pages. Once you do, complete the following steps:
Install the Argilla client and the required third party libraries using
pip:
[ ]:
%pip install argilla datasets pandas httpx plotly -qqq
Let’s make the necessary imports:
[ ]:
import argilla as rg
from datasets import Dataset, load_dataset
import pandas as pd
import httpx
import random
from collections import defaultdict, Counter
import plotly.express as px
If you are running Argilla using the Docker quickstart image or Hugging Face Spaces, you need to init the Argilla client with the
URLandAPI_KEY:
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
rg.init(
api_url="http://localhost:6900",
api_key="admin.apikey"
)
Define the project#
As a first step, let’s load the dataset and quickly explore the data:
[ ]:
data = load_dataset("argilla/databricks-dolly-15k-curated-multilingual", split="en")
[4]:
df = data.to_pandas()
df
[4]:
| instruction | context | response | category | instruction_original_en | context_original_en | response_original_en | id | |
|---|---|---|---|---|---|---|---|---|
| 0 | When did Virgin Australia start operating? | Virgin Australia, the trading name of Virgin A... | Virgin Australia commenced services on 31 Augu... | closed_qa | When did Virgin Australia start operating? | Virgin Australia, the trading name of Virgin A... | Virgin Australia commenced services on 31 Augu... | 0 |
| 1 | Which is a species of fish? Tope or Rope | Tope | classification | Which is a species of fish? Tope or Rope | Tope | 1 | ||
| 2 | Why can camels survive for long without water? | Camels use the fat in their humps to keep them... | open_qa | Why can camels survive for long without water? | Camels use the fat in their humps to keep them... | 2 | ||
| 3 | Alice's parents have three daughters: Amy, Jes... | The name of the third daughter is Alice | open_qa | Alice's parents have three daughters: Amy, Jes... | The name of the third daughter is Alice | 3 | ||
| 4 | When was Tomoaki Komorida born? | Komorida was born in Kumamoto Prefecture on Ju... | Tomoaki Komorida was born on July 10,1981. | closed_qa | When was Tomoaki Komorida born? | Komorida was born in Kumamoto Prefecture on Ju... | Tomoaki Komorida was born on July 10,1981. | 4 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 15010 | How do i accept the change | Embrace the change and see the difference | brainstorming | How do i accept the change | Embrace the change and see the difference | 15010 | ||
| 15011 | What is a laser and who created it? | A laser is a device that emits light through a... | A laser is a device that emits light from an e... | summarization | What is a laser and who created it? | A laser is a device that emits light through a... | A laser is a device that emits light from an e... | 15011 |
| 15012 | What is the difference between a road bike and... | Road bikes are built to be ridden on asphalt a... | open_qa | What is the difference between a road bike and... | Road bikes are built to be ridden on asphalt a... | 15012 | ||
| 15013 | How does GIS help in the real estate investmen... | Real estate investors depend on precise, accur... | general_qa | How does GIS help in the real estate investmen... | Real estate investors depend on precise, accur... | 15013 | ||
| 15014 | What is the Masters? | The Masters Tournament is a golf tournament he... | general_qa | What is the Masters? | The Masters Tournament is a golf tournament he... | 15014 |
15015 rows × 8 columns
For our project, we would like to make sure that the instruction, the context and the response are formulated clearly and concisely, and that they provide correct information. We will add those fields to our records. The category will help our annotators know what these fields should look like, so we will add it too. We can also keep the id so we can identify the records easily on post-processing.
[57]:
# format the data as Argilla records
records = [rg.FeedbackRecord(fields={"category": record["category"], "instruction": record["instruction"], "response": record["response"], "context": record["context"]}, external_id=record['id']) for record in data]
# list of fields that we will use later for our dataset settings
fields = [
rg.TextField(name="category", title="Task category"),
rg.TextField(name="instruction"),
rg.TextField(name="context", title="Input", required=False),
rg.TextField(name="response")
]
Now we can think of the questions that we would like to ask about these records and we will provide some guidelines for the annotators. We will ask them to mark if the record needs changes or not. If the answer is yes, they will need to provide
[7]:
# list of questions to display in the feedback form
questions =[
rg.TextQuestion(
name="new-instruction",
title="Final instruction:",
description="Write the final version of the instruction, making sure that it matches the task category. If the original instruction is ok, copy and paste it here.",
required=True
),
rg.TextQuestion(
name="new-input",
title="Final input:",
description="Write the final version of the input, making sure that it makes sense with the task category. If the original input is ok, copy and paste it here. If an input is not needed, leave this empty.",
required=False
),
rg.TextQuestion(
name="new-response",
title="Final response:",
description="Write the final version of the response, making sure that it matches the task category and makes sense for the instruction (and input) provided. If the original response is ok, copy and paste it here.",
required=True
)
]
guidelines = "In this dataset, you will find a collection of records that show a category, an instruction, an input and a response to that instruction. The aim of the project is to correct the instructions, intput and responses to make sure they are of the highest quality and that they match the task category that they belong to. All three texts should be clear and include real information. In addition, the response should be as complete but concise as possible.\n\nTo curate the dataset, you will need to provide an answer to the following text fields:\n\n1 - Final instruction:\nThe final version of the instruction field. You may copy it using the copy icon in the instruction field. Leave it as it is if it's ok or apply any necessary corrections. Remember to change the instruction if it doesn't represent well the task category of the record.\n\n2 - Final input:\nThe final version of the instruction field. You may copy it using the copy icon in the input field. Leave it as it is if it's ok or apply any necessary corrections. If the task category and instruction don't need of an input to be completed, leave this question blank.\n\n3 - Final response:\nThe final version of the response field. You may copy it using the copy icon in the response field. Leave it as it is if it's ok or apply any necessary corrections. Check that the response makes sense given all the fields above.\n\nYou will need to provide at least an instruction and a response for all records. If you are not sure about a record and you prefer not to provide a response, click Discard."
Split the workload and import to Argilla#
For this specific project, we don’t want any overlap between our annotation team, as we only want one unique version of each record. We’ll assume that the annotations of our team have the desired quality to work as demonstration data for our instruction-following model.
Tip
For extra quality assurance, you can make a new dataset where annotators rate the quality of the human annotated dataset.
To avoid having multiple responses for a record, we will split the workload between all of our annotators and import the records assigned to them in a dataset in their personal workspace.
First, let’s get the list of users using the Argilla Client.
[9]:
# make a request using your Argilla Client to get the list of users
rg_client= rg.active_client().client
auth_headers = {"X-Argilla-API-Key": rg_client.token}
http=httpx.Client(base_url=rg_client.base_url, headers=auth_headers)
users = http.get("/api/users").json()
# filter users to get only those with annotator role
users = [user for user in users if user['role']=='annotator']
When we’re happy with the list of users, we can move on to do the assignments:
[13]:
# shuffle the records to get a random assignment
random.shuffle(records)
# build a dictionary where the key is the username and the value is the list of records assigned to them
assignments = defaultdict(list)
# divide your records in chunks of the same length as the users list and make the assignments
# you will need to follow the instructions to create and push a dataset for each of the key-value pairs in this dictionary
n = len(users)
chunked_records = [records[i:i + n] for i in range(0, len(records), n)]
for chunk in chunked_records:
for idx, record in enumerate(chunk):
assignments[users[idx]['username']].append(record)
# create a dataset for each annotator and push it to their personal workspace
for username,records in assignments.items():
dataset = rg.FeedbackDataset(
guidelines=guidelines,
fields=fields,
questions=questions
)
dataset.add_records(records)
dataset.push_to_argilla(name='curate_dolly', workspace=username)
Collect feedback and publish the results#
At this point, the datasets are ready to start the annotation. Once the annotations are done, we will collect all the feedback from our team and combine it in a single dataset.
[ ]:
feedback = []
for username in assignments.keys():
feedback.extend(rg.FeedbackDataset.from_argilla('curate_dolly', workspace=username))
Let’s explore the dataset a bit so we can draw some conclusions about it:
[53]:
responses = []
for record in feedback:
if record.responses is None or len(record.responses) == 0:
continue
# we should only have 1 response per record, so we can safely use the first one only
response = record.responses[0]
if response.status != 'submitted':
changes = []
else:
changes = []
if response.values['new-instruction'].value != record.fields['instruction']:
changes.append('instruction')
if response.values['new-input'].value != record.fields['context']:
changes.append('input')
if response.values['new-response'].value != record.fields['response']:
changes.append('response')
responses.append({'status': response.status, 'category': record.fields['category'], 'changes': ','.join(changes)})
responses_df = pd.DataFrame(responses)
responses_df = responses_df.replace('', 'None')
[ ]:
fig = px.histogram(responses_df, x='status')
fig.show()
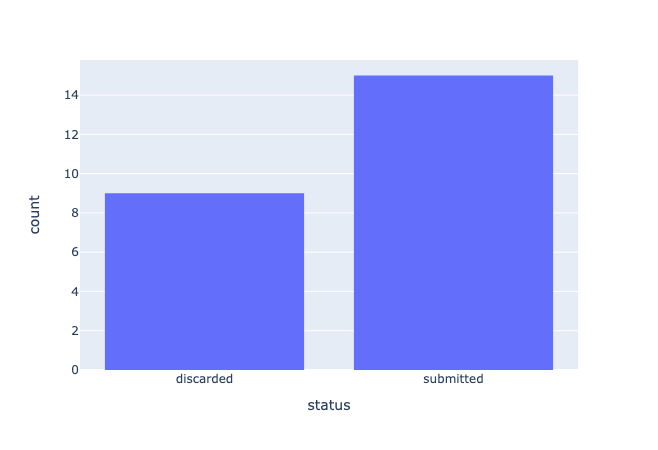
We can see that the majority of the records have submitted responses. That means that we are not losing too much data during the annotation project.
Tip
If an important percentage of the records have a discarded response, you can take all the discarded records and serve them to a different annotator as long as you are using the Discard button as a way for your annotation team to skip records.
Now, let’s check how many of our submitted responses proposed modifications to the original text:
[ ]:
fig = px.histogram(responses_df.loc[responses_df['status']=='submitted'], x='changes')
fig.update_xaxes(categoryorder='total descending')
fig.update_layout(bargap=0.2)
fig.show()
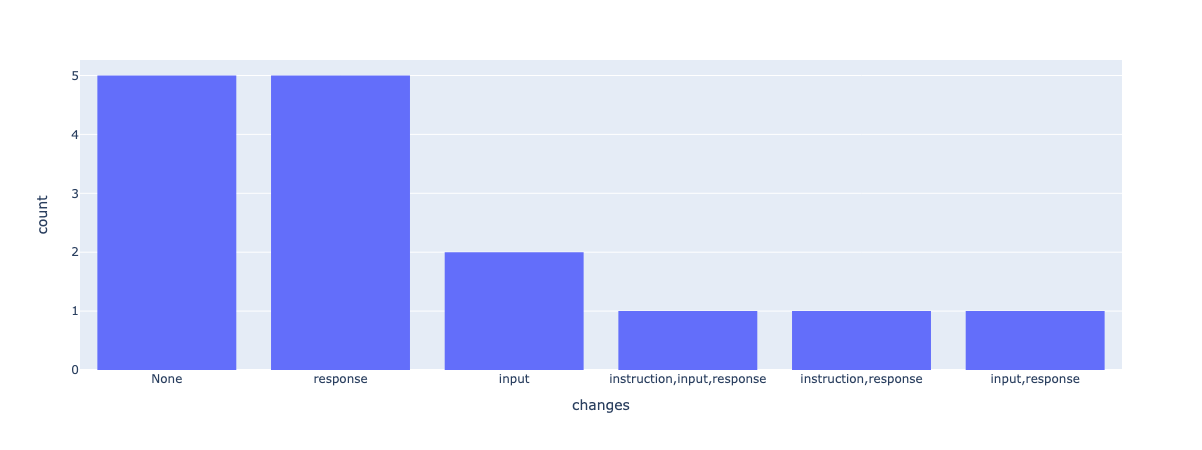
As we can see here, an important percentage of the submitted responses considered that the records needed at least one modification and that the response is the field most likely to be modified.
We could publish the dataset as it is now, but for this example we’ll do a little post-processing to simplify the fields and substitute the old instruction and response with the new version provided by our annotators. That way, we have a dataset that’s fully ready for fine-tuning.
[55]:
new_records = []
for record in feedback:
if record.responses:
continue
# we should only have 1 response per record, so we can safely use the first one only
response = record.responses[0]
# we will skip records where our annotators didn't submit their feedback
if response.status != 'submitted':
continue
record.fields['instruction'] = response.values['new-instruction'].value
record.fields['context'] = response.values['new-input'].value
record.fields['response'] = response.values['new-response'].value
new_records.append(record.fields)
Let’s check how it looks:
[56]:
new_df = pd.DataFrame(new_records)
new_df
[56]:
| category | instruction | context | response | |
|---|---|---|---|---|
| 0 | open_qa | How do I get rid of mosquitos in my house? | You can get rid of mosquitos in your house by ... | |
| 1 | classification | Classify each country as "African" or "Europea... | Nigeria: African\nRwanda: African\nPortugal: E... | |
| 2 | information_extraction | Extract the unique names of composers from the... | To some extent, European and the US traditions... | Pierre Boulez, Luigi Nono, Karlheinz Stockhaus... |
| 3 | general_qa | Should investors time the market? | Timing the market is based on predictions of t... | |
| 4 | classification | I am looking at items on my desk right now, te... | Trident mint, Macbook Pro, Pixel 3, Apple Airp... | |
| 5 | summarization | How was basketball was invented? | Basketball began with its invention in 1891 in... | Basketball was invented as a less injury-prone... |
| 6 | general_qa | Is there an answer to the universe? | According to the novel Hitchhikers Guide to th... | |
| 7 | information_extraction | From the passage note down the name of the cou... | The World Bank is an international financial i... | U.S., Japan, China, Germany, U.K. |
| 8 | open_qa | Give me the list of top 10 movies of all time,... | These are the top 10 movies based on their IMD... | |
| 9 | creative_writing | Is social media good for you ? | There are conflicting views on the impact of s... | |
| 10 | open_qa | What is the difference between a pomelo and a ... | Both a pomelo and a grapefruit have similar ci... | |
| 11 | classification | Identify the bird from the list: Barn owl, Pyt... | Barn owl | |
| 12 | creative_writing | Create a 5 day itinerary for a trip to Japan. ... | Day 1: Arrive at Osaka, in the center of Japan... | |
| 13 | brainstorming | What are some ways to improve the value of you... | There are several things you do can to increas... | |
| 14 | summarization | Give me a summary about St Paul's Cathedral | St Paul's Cathedral is an Anglican cathedral i... | St Paul's Cathedral, an Anglican cathedral in ... |
Now we’re happy with the result, we can publish it in the Hugging Face Hub, so the whole open-source community can benefit from it.
[ ]:
#push to hub
new_dataset = Dataset(new_records)
new_dataset.push_to_hub(".../curated_databricks-dolly-15k")
This dataset is ready to be used as a demonstration dataset to fine-tune instruction-following models.
Summary#
In this tutorial, we learned how to create an instruction dataset by curating a public dataset with a permissive license, in this case the Dolly dataset made by Databricks employees. This can help us to fine-tune an instruction-following model using high-quality data that will help us get better results with a more efficient training.