🧸 Using LLMs for Text Classification and Summarization Suggestions with spacy-llm#
In this tutorial, we’ll implement a spacy-llm pipeline to obtain model suggestions with GPT3.5 and add them to our FeedbackDataset as suggestions. The flow of the tutorial will be:
Run Argilla and load
spacy-llmalong with other librariesDefine config for your pipeline and initialize it
Create your
FeedbackDatasetinstanceGenerate predictions on data and add them to
recordsPush to Argilla
Introduction#
spacy-llm is a package that integrates the strength of LLMs into regular spaCy pipelines, thus allowing quick and practical prompting for various tasks. Besides, since it requires no training data, the models are ready to use in your pipeline. If you want to train your own model or create your custom task, spacy-llm also helps to implement any custom pipeline.
It is quite easy to use this powerful package with Argilla Feedback datasets. We can make inferences with the pipeline we will create and add them to our FeedbackDataset.
Running Argilla#
For this tutorial, you will need to have an Argilla server running. There are two main options for deploying and running Argilla:
Deploy Argilla on Hugging Face Spaces: If you want to run tutorials with external notebooks (e.g., Google Colab) and you have an account on Hugging Face, you can deploy Argilla on Spaces with a few clicks:

For details about configuring your deployment, check the official Hugging Face Hub guide.
Launch Argilla using Argilla’s quickstart Docker image: This is the recommended option if you want Argilla running on your local machine. Note that this option will only let you run the tutorial locally and not with an external notebook service.
For more information on deployment options, please check the Deployment section of the documentation.
Tip
This tutorial is a Jupyter Notebook. There are two options to run it:
Use the Open in Colab button at the top of this page. This option allows you to run the notebook directly on Google Colab. Don’t forget to change the runtime type to GPU for faster model training and inference.
Download the .ipynb file by clicking on the View source link at the top of the page. This option allows you to download the notebook and run it on your local machine or on a Jupyter notebook tool of your choice.
Setup#
Let us first install the required libraries for our task,
[ ]:
pip install "spacy-llm[transformers]" "transformers[sentencepiece]" argilla datasets -qqq
and import them as well.
[ ]:
import os
import spacy
from spacy_llm.util import assemble
import argilla as rg
from datasets import load_dataset
import configparser
from collections import Counter
from heapq import nlargest
You need to initialize the Argilla client with API_URL and API_KEY:
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
rg.init(
api_url="http://localhost:6900",
api_key="admin.apikey"
)
If you’re running a private Hugging Face Space, you will also need to set the HF_TOKEN as follows:
[ ]:
# # Set the HF_TOKEN environment variable
# import os
# os.environ['HF_TOKEN'] = "your-hf-token"
# # Replace api_url with the url to your HF Spaces URL
# # Replace api_key if you configured a custom API key
# rg.init(
# api_url="https://[your-owner-name]-[your_space_name].hf.space",
# api_key="admin.apikey",
# extra_headers={"Authorization": f"Bearer {os.environ['HF_TOKEN']}"},
# )
Enable Telemetry#
We gain valuable insights from how you interact with our tutorials. To improve ourselves in offering you the most suitable content, using the following lines of code will help us understand that this tutorial is serving you effectively. Though this is entirely anonymous, you can choose to skip this step if you prefer. For more info, please check out the Telemetry page.
[ ]:
try:
from argilla.utils.telemetry import tutorial_running
tutorial_running()
except ImportError:
print("Telemetry is introduced in Argilla 1.20.0 and not found in the current installation. Skipping telemetry.")
spacy-llm pipeline#
To be able to use GPT3.5 and other models from OpenAI with spacy-llm, we’ll need an API key from openai.com and set it as an environment variable.
[ ]:
os.environ["OPENAI_API_KEY"] = "<YOUR_OPEN_AI_API_KEY>"
There are two ways to implement a spacy-llm pipeline for your LLM task: running the pipeline in the source code or using a config.cfg file to define all settings and hyperparameters of your pipeline. In this tutorial, we’ll work with a config file and you can have more info about running directly in Python here.
Let us first define the settings of our pipeline as parameters in our config file. We’ll implement two tasks: text classification and summarization, which we define them in the pipeline command. Then, we add our components to our pipeline to specify each task with their respective models and hypermeters.
[ ]:
config_string = """
[nlp]
lang = "en"
pipeline = ["llm_textcat","llm_summarization","sentencizer"]
[components]
[components.llm_textcat]
factory = "llm"
[components.llm_textcat.task]
@llm_tasks = "spacy.TextCat.v2"
labels = ["HISTORY","MUSIC","TECHNOLOGY","SCIENCE","SPORTS","POLITICS"]
[components.llm_textcat.model]
@llm_models = "spacy.GPT-3-5.v1"
[components.llm_summarization]
factory = "llm"
[components.llm_summarization.task]
@llm_tasks = "spacy.Summarization.v1"
[components.llm_summarization.model]
@llm_models = "spacy.GPT-3-5.v1"
[components.sentencizer]
factory = "sentencizer"
punct_chars = null
"""
With these settings, we create an LLM pipeline for text classification and summarization in English with GPT3.5.
spacy-llm offers various models to implement in your pipeline. You can have a look at the available OpenAI models as well as check the HuggingFace models offered if you want to work with open-source models.
Now, with ConfigParser, we can create the config file.
[ ]:
config = configparser.ConfigParser()
config.read_string(config_string)
with open("config.cfg", 'w') as configfile:
config.write(configfile)
Let us assemble the config file.
[ ]:
nlp = assemble("config.cfg")
We are ready to make inferences with the pipeline we have created.
[ ]:
doc = nlp("No matter how hard they tried, Barcelona lost the match.")
doc.cats
Inference#
We need two functions that will ease the inferencing process and give us the text category and summary that we want.
[ ]:
#returns the category with the highest score
def get_textcat_suggestion(doc):
model_prediction = doc.cats
return max(model_prediction, key=model_prediction.get)
#selects the top N sentences with the highest scores and return combined string
def get_summarization_suggestion(doc):
sentence_scores = Counter()
for sentence in doc.sents:
for word in sentence:
sentence_scores[sentence] += 1
summary_sentences = nlargest(2, sentence_scores, key=sentence_scores.get)
summary = ' '.join(str(sentence) for sentence in summary_sentences)
return summary
Load Data#
We will use squad_v2 from HuggingFace library in this tutorial. squad_v2 is a dataset consisting of questions and their answers along with the context to search for the answer within. We’ll use only the context column for our purposes.
[ ]:
dataset_hf = load_dataset("squad_v2", split="train").shard(num_shards=10000, index=235)
FeedbackDataset#
Now that we have our pipeline for inference and the data, we can create our Argilla FeedbackDataset to make and store model suggestions. For this tutorial, we will create both a text classification task and a summarization task. Argilla Feedback lets us implement both tasks with LabelQuestion and TextQuestion, respectively.
[ ]:
dataset = rg.FeedbackDataset(
fields=[
rg.TextField(name="text")
],
questions=[
rg.LabelQuestion(
name="label-question",
title="Classify the text category.",
#make sure that the labels are in line with the labels we have defined in config.cfg
labels=["HISTORY","MUSIC","TECHNOLOGY","SCIENCE","SPORTS","POLITICS"]
),
rg.TextQuestion(
name="text-question",
title="Provide a summary for the text."
)
]
)
We can create the records for our dataset by iterating over the dataset we loaded. While doing this, we will make inferences and save them in the suggestions with get_textcat_suggestion() and get_summarization_suggestion() functions.
[ ]:
records = [
rg.FeedbackRecord(
fields={
"text": doc.text
},
suggestions=[
{"question_name": "label-question",
"value": get_textcat_suggestion(doc)},
{"question_name":"text-question",
"value": get_summarization_suggestion(doc)}
]
) for doc in [nlp(item) for item in dataset_hf["context"]]
]
We have created the records, let us add them to the FeedbackDataset.
[ ]:
dataset.add_records(records)
Push to Argilla#
We are now ready to push our dataset to Argilla and can start to collect annotations.
[ ]:
remote_dataset = dataset.push_to_argilla(name="squad_spacy-llm", workspace="admin")
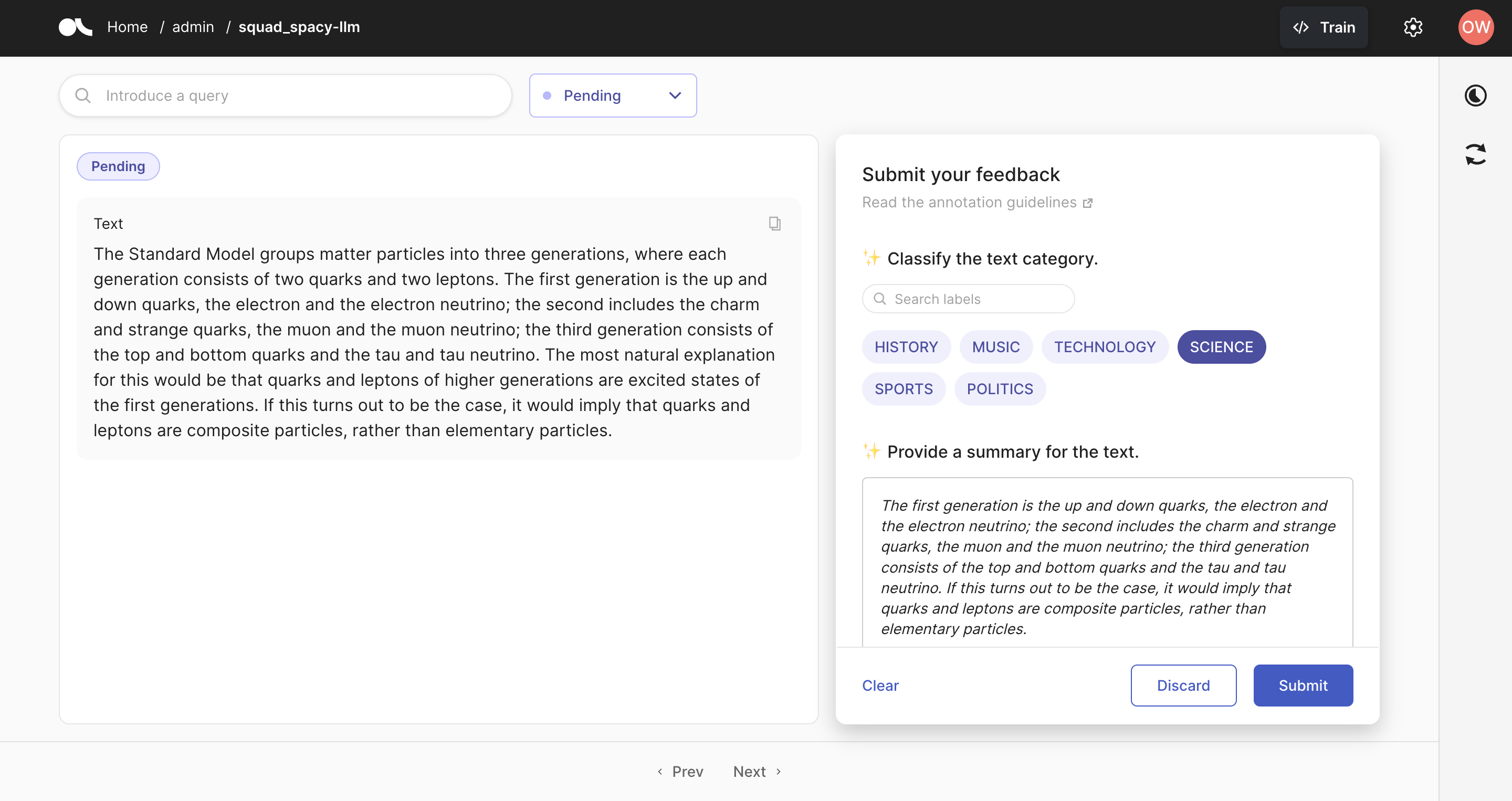
You should see the Argilla page ready to annotate as below.
In this tutorial, we have implemented a spacy-llm pipeline for text classification and summarization tasks. By Argilla Feedback datasets, we have been able to add the model predictions as suggestions to our dataset so that our annotators can utilize them. For more info on spacy-llm, you can go to their LLM page, and for other uses of Argilla Feedback datasets, you can refer to our guides.