📰 Train a text classifier with weak supervision#
In this tutorial, we will build a news classifier using rules and weak supervision:
📰 For this example, we use the AG News dataset but you can follow this process to programmatically label any dataset.
🤿 The train split without labels is used to build a training set with rules, Argilla and Snorkel’s Label model.
🔧 The test set is used for evaluating our weak labels, label model and downstream news classifier.
🤯 We achieve 0.82 macro avg. f1-score without using a single example from the original dataset and using a pretty lightweight model (scikit-learn’s
MultinomialNB).
The following diagram shows the overall process for using Weak supervision with Argilla:
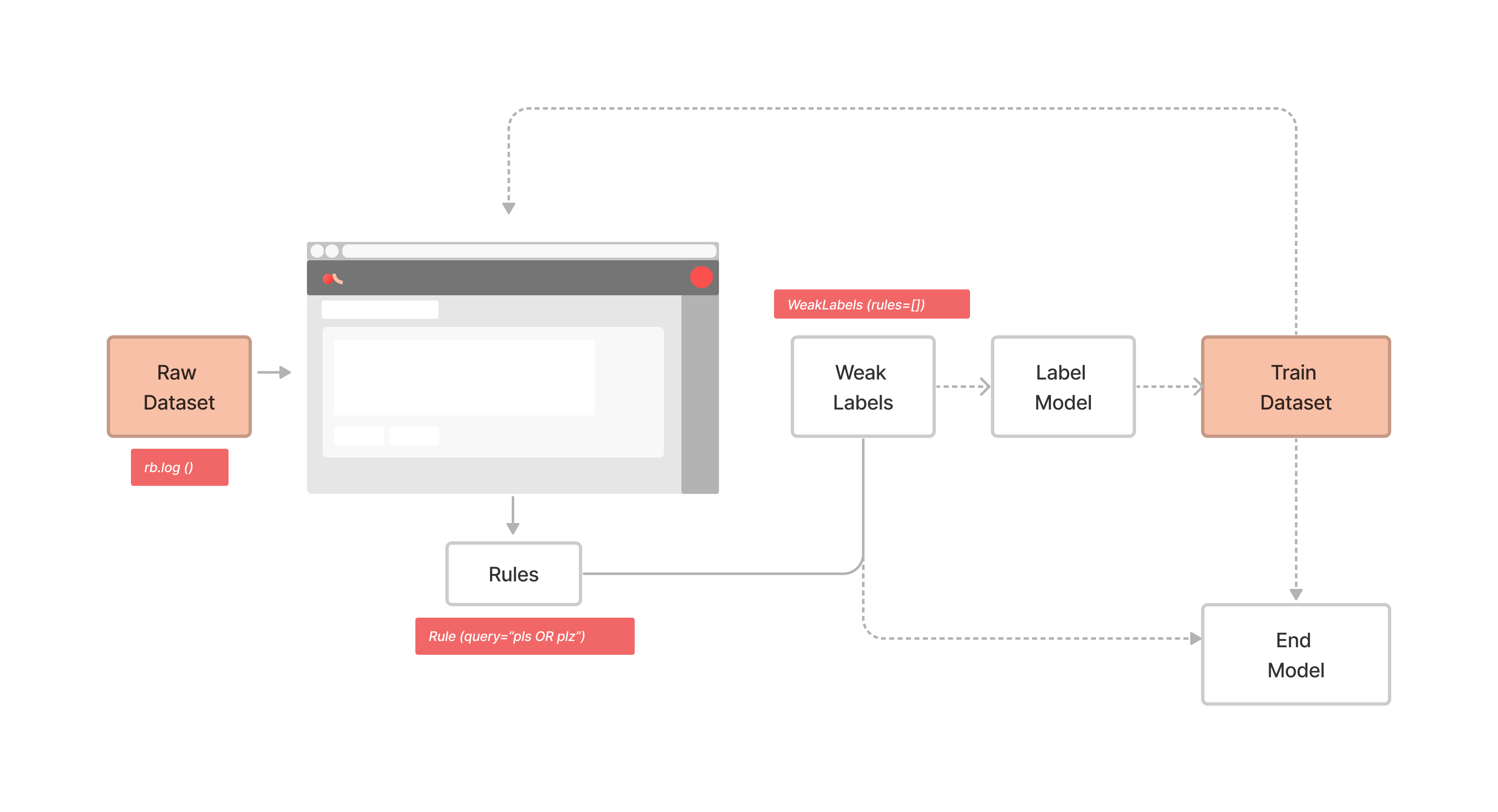
Introduction#
Weak supervision is a branch of machine learning where noisy, limited, or imprecise sources are used to provide supervision signal for labeling large amounts of training data in a supervised learning setting. This approach alleviates the burden of obtaining hand-labeled data sets, which can be costly or impractical. Instead, inexpensive weak labels are employed with the understanding that they are imperfect, but can nonetheless be used to create a strong predictive model. [Wikipedia]
For a broader introduction to weak supervision, as well as further references, we recommend the excellent overview by Alex Ratner et al..
This tutorial aims to be a practical introduction to weak supervision and will walk you through its entire process. First we will generate weak labels with Argilla, combine these labels with Snorkel, and finally train a classifier with Scikit Learn.
Running Argilla#
For this tutorial, you will need to have an Argilla server running. There are two main options for deploying and running Argilla:
Deploy Argilla on Hugging Face Spaces: If you want to run tutorials with external notebooks (e.g., Google Colab) and you have an account on Hugging Face, you can deploy Argilla on Spaces with a few clicks:

For details about configuring your deployment, check the official Hugging Face Hub guide.
Launch Argilla using Argilla’s quickstart Docker image: This is the recommended option if you want Argilla running on your local machine. Note that this option will only let you run the tutorial locally and not with an external notebook service.
For more information on deployment options, please check the Deployment section of the documentation.
Tip
This tutorial is a Jupyter Notebook. There are two options to run it:
Use the Open in Colab button at the top of this page. This option allows you to run the notebook directly on Google Colab. Don’t forget to change the runtime type to GPU for faster model training and inference.
Download the .ipynb file by clicking on the View source link at the top of the page. This option allows you to download the notebook and run it on your local machine or on a Jupyter notebook tool of your choice.
Setup#
For this tutorial, you’ll need to install the Argilla client and a few third party libraries using pip:
[ ]:
%pip install argilla snorkel datasets sklearn -qqq
Let’s import the Argilla module for reading and writing data:
[1]:
import argilla as rg
If you are running Argilla using the Docker quickstart image or Hugging Face Spaces, you need to init the Argilla client with the URL and API_KEY:
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# Replace api_key if you configured a custom API key
rg.init(
api_url="http://localhost:6900",
api_key="admin.apikey"
)
Finally, let’s include the imports we need:
[ ]:
from datasets import load_dataset
import pandas as pd
from argilla.labeling.text_classification import *
from sklearn.feature_extraction.text import TfidfTransformer, CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
from sklearn import metrics
Note
If you want to skip the first three sections of this tutorial, and only prepare the training set and train a downstream model, you can load the records directly from the Hugging Face Hub:
import argilla as rg
from datasets import load_dataset
# this replaces the `records = label_model.predict()` line of section 4
records = rg.read_datasets(
load_dataset("argilla/news", split="train"),
task="TextClassification",
)
1. Load test and unlabelled datasets into Argilla#
First, let’s download the ag_news data set and have a quick look at it.
[ ]:
# load our data
dataset = load_dataset("ag_news")
# get the index to label mapping
labels = dataset["test"].features["label"].names
[5]:
# quick look at our data
with pd.option_context("display.max_colwidth", None):
display(dataset["test"].to_pandas().head())
| text | label | |
|---|---|---|
| 0 | Fears for T N pension after talks Unions representing workers at Turner Newall say they are 'disappointed' after talks with stricken parent firm Federal Mogul. | 2 |
| 1 | The Race is On: Second Private Team Sets Launch Date for Human Spaceflight (SPACE.com) SPACE.com - TORONTO, Canada -- A second\team of rocketeers competing for the #36;10 million Ansari X Prize, a contest for\privately funded suborbital space flight, has officially announced the first\launch date for its manned rocket. | 3 |
| 2 | Ky. Company Wins Grant to Study Peptides (AP) AP - A company founded by a chemistry researcher at the University of Louisville won a grant to develop a method of producing better peptides, which are short chains of amino acids, the building blocks of proteins. | 3 |
| 3 | Prediction Unit Helps Forecast Wildfires (AP) AP - It's barely dawn when Mike Fitzpatrick starts his shift with a blur of colorful maps, figures and endless charts, but already he knows what the day will bring. Lightning will strike in places he expects. Winds will pick up, moist places will dry and flames will roar. | 3 |
| 4 | Calif. Aims to Limit Farm-Related Smog (AP) AP - Southern California's smog-fighting agency went after emissions of the bovine variety Friday, adopting the nation's first rules to reduce air pollution from dairy cow manure. | 3 |
Now we will log the test split of our data set to Argilla, which we will be using for testing our label and downstream models.
[ ]:
# build our test records
records = [
rg.TextClassificationRecord(
text=record["text"],
metadata={"split": "test"},
annotation=labels[record["label"]],
)
for record in dataset["test"]
]
# log the records to Argilla
rg.log(records, name="news")
In a second step we log the train split without labels. Remember, our goal is to programmatically build a training set using rules and weak supervision.
[ ]:
# build our training records without labels
records = [
rg.TextClassificationRecord(
text=record["text"],
metadata={"split": "unlabelled"},
)
for record in dataset["train"]
]
# log the records to Argilla
rg.log(records, name="news")
The result of the above is the following dataset in Argilla, with 127,600 records (120,000 unlabelled and 7,600 for testing).
You can use the web app to find good rules for programmatic labeling!
2. Define Rules#
Rules can be defined and managed (1) using the UI, and (2) using the Python client. We will add some rules with the Python Client that will be available in the UI where we can start our interactive weak labelling.
[32]:
# define queries and patterns for each category (using ES DSL)
queries = [
(["money", "financ*", "dollar*"], "Business"),
(["war", "gov*", "minister*", "conflict"], "World"),
(["footbal*", "sport*", "game", "play*"], "Sports"),
(["sci*", "techno*", "computer*", "software", "web"], "Sci/Tech"),
]
# define rules
rules = [Rule(query=term, label=label) for terms, label in queries for term in terms]
[13]:
# add rules to the dataset
add_rules(dataset="news", rules=rules)
3. Denoise weak labels with Snorkel’s Label Model#
The goal at this step is to denoise the weak labels we’ve just created using rules. There are several approaches to this problem using different statistical methods.
In this tutorial, we’re going to use Snorkel but you can actually use any other Label model or weak supervision method, such as FlyingSquid for example (see the Weak supervision guide for more details). For convenience, Argilla defines a simple wrapper over Snorkel’s Label Model so it’s easier to use with Argilla weak labels and datasets
Let’s first read the rules defined in our dataset and create our weak labels:
[15]:
weak_labels = WeakLabels(dataset="news")
weak_labels.summary()
[15]:
| label | coverage | annotated_coverage | overlaps | conflicts | correct | incorrect | precision | |
|---|---|---|---|---|---|---|---|---|
| money | {Business} | 0.008268 | 0.008816 | 0.002484 | 0.001983 | 30 | 37 | 0.447761 |
| financ* | {Business} | 0.019655 | 0.017763 | 0.005933 | 0.005227 | 80 | 55 | 0.592593 |
| dollar* | {Business} | 0.016591 | 0.016316 | 0.003582 | 0.002947 | 87 | 37 | 0.701613 |
| war | {World} | 0.015627 | 0.017105 | 0.004459 | 0.001732 | 101 | 29 | 0.776923 |
| gov* | {World} | 0.045086 | 0.045263 | 0.011191 | 0.006277 | 170 | 174 | 0.494186 |
| minister* | {World} | 0.030031 | 0.028289 | 0.007908 | 0.002821 | 193 | 22 | 0.897674 |
| conflict | {World} | 0.003025 | 0.002763 | 0.001097 | 0.000102 | 17 | 4 | 0.809524 |
| footbal* | {Sports} | 0.013158 | 0.015000 | 0.004953 | 0.000447 | 107 | 7 | 0.938596 |
| sport* | {Sports} | 0.021191 | 0.021316 | 0.007038 | 0.001223 | 139 | 23 | 0.858025 |
| game | {Sports} | 0.038738 | 0.037632 | 0.014060 | 0.002390 | 216 | 70 | 0.755245 |
| play* | {Sports} | 0.052453 | 0.050000 | 0.016991 | 0.005196 | 268 | 112 | 0.705263 |
| sci* | {Sci/Tech} | 0.016552 | 0.018421 | 0.002782 | 0.001340 | 114 | 26 | 0.814286 |
| techno* | {Sci/Tech} | 0.027210 | 0.028289 | 0.008534 | 0.003205 | 155 | 60 | 0.720930 |
| computer* | {Sci/Tech} | 0.027586 | 0.028158 | 0.011277 | 0.004514 | 159 | 55 | 0.742991 |
| software | {Sci/Tech} | 0.030188 | 0.029474 | 0.009828 | 0.003378 | 183 | 41 | 0.816964 |
| web | {Sci/Tech} | 0.017132 | 0.014737 | 0.004561 | 0.001779 | 87 | 25 | 0.776786 |
| total | {World, Sci/Tech, Business, Sports} | 0.320964 | 0.315000 | 0.055149 | 0.020039 | 2106 | 777 | 0.730489 |
[16]:
# create the label model
label_model = Snorkel(weak_labels)
# fit the model
label_model.fit()
100%|██████████| 100/100 [00:00<00:00, 1228.48epoch/s]
[17]:
print(label_model.score(output_str=True))
precision recall f1-score support
Business 0.66 0.35 0.46 455
World 0.70 0.81 0.75 522
Sci/Tech 0.78 0.77 0.77 784
Sports 0.78 0.96 0.86 633
accuracy 0.75 2394
macro avg 0.73 0.72 0.71 2394
weighted avg 0.74 0.75 0.73 2394
4. Prepare our training set#
Now, we already have a “denoised” training set, which we can prepare for training a downstream model. The label model predict returns TextClassificationRecord objects with the predictions from the label model.
We can either refine and review these records using the Argilla web app, use them as is, or filter them by score, for example.
In this case, we assume the predictions are precise enough and use them without any revision. Our training set has ~38,000 records, which corresponds to all records where the label model has not abstained.
[18]:
# get records with the predictions from the label model
records = label_model.predict()
# you can replace this line with
# records = rg.read_datasets(
# load_dataset("argilla/news", split="train"),
# task="TextClassification",
# )
# we could also use the `weak_labels.label2int` dict
label2int = {"Sports": 0, "Sci/Tech": 1, "World": 2, "Business": 3}
# extract training data
X_train = [rec.text for rec in records]
y_train = [label2int[rec.prediction[0][0]] for rec in records]
[19]:
# quick look at our training data with the weak labels from our label model
with pd.option_context("display.max_colwidth", None):
display(pd.DataFrame({"text": X_train, "label": y_train}))
| text | label | |
|---|---|---|
| 0 | Tennis: Defending champion Myskina sees off world number one <b>...</b> MOSCOW : Defending champion and French Open winner Anastasia Myskina advanced into the final of the 2.3 million dollar Kremlin Cup beating new world number one Lindsay Davenport of the United States here. | 3 |
| 1 | Britain Pays Final Respects to Beheaded Hostage British Prime Minister Tony Blair was among the hundreds of people that attended an emotional service for a man kidnapped and killed in Iraq. | 2 |
| 2 | Skulls trojan targets Symbian smartphones A new trojan on the internet attacks the Nokia 7610 smartphone and possibly other phones running Symbian Series 60 software. quot;We have located several freeware and shareware sites offering a program, called | 1 |
| 3 | Sudan Security Foils New Sabotage Plot -- Agency Sudanese authorities said Friday they foiled another plot by an opposition Islamist party to kidnap and kill senior government officials and blow up sites in the capital | 2 |
| 4 | Sony and Partners Agree To Acquire MGM Sony Corp. and several financial partners have agreed in principle to acquire movie studio Metro-Goldwyn-Mayer for about \$2.94 billion in cash, sources familiar with the talks said Monday. | 3 |
| ... | ... | ... |
| 38556 | Titan hangs on to its secrets Cassini #39;s close fly-by of Titan, Saturn #39;s largest moon, has left scientists with no clear idea of what to expect when the Huygens probe lands on the alien world, despite the amazingly detailed images they now have of the surface. | 1 |
| 38557 | Ministers deny interest in raising inheritance tax Downing Street distanced itself last night from reports that inheritance tax will rise to 50 per cent for the wealthiest families. | 2 |
| 38558 | No Frills, but Everything Else Is on Craigslist (washingtonpost.com) washingtonpost.com - Ernie Miller, a 38-year-old software developer in Silver Spring, offers a telling clue as to how www.craigslist.org became the Internet's go-to place to solve life's vexing problems. | 1 |
| 38559 | Familiar refrain as Singh leads Just when Vijay Singh thinks he can't play better, he does. Just when it seems he can't do much more during his Tiger Woods-like season, he does that, too. | 0 |
| 38560 | Cisco to acquire P-Cube for \$200m Cisco Systems has agreed to buy software developer P-Cube in a cash-and-options deal Cisco valued at \$200m (110m). P-Cube makes software to help service providers analyse and control network traffic. | 1 |
38561 rows × 2 columns
5. Train a downstream model with scikit-learn#
Now, let’s train our final model using scikit-learn:
[20]:
# define our final classifier
classifier = Pipeline([("vect", CountVectorizer()), ("clf", MultinomialNB())])
# fit the classifier
classifier.fit(
X=X_train,
y=y_train,
)
[20]:
Pipeline(steps=[('vect', CountVectorizer()), ('clf', MultinomialNB())])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Pipeline(steps=[('vect', CountVectorizer()), ('clf', MultinomialNB())])CountVectorizer()
MultinomialNB()
To test our trained model, we use the records with validated annotations, that is the original ag_news test set.
[21]:
# retrieve records with annotations
test_ds = weak_labels.records(has_annotation=True)
# you can replace this line with
# test_ds = rg.read_datasets(
# load_dataset("argilla/news_test", split="train"),
# task="TextClassification",
# )
# extract text and labels
X_test = [rec.text for rec in test_ds]
y_test = [label2int[rec.annotation] for rec in test_ds]
[22]:
# compute the test accuracy
accuracy = classifier.score(
X=X_test,
y=y_test,
)
print(f"Test accuracy: {accuracy}")
Test accuracy: 0.8176315789473684
Not too bad! 🥳
We have achieved around 0.82 accuracy without even using a single example from the original ag_news train set and with a small set of 16 rules. Also, we’ve improved over the 0.75 accuracy of our Label Model.
Finally, let’s take a look at more detailed metrics:
[23]:
# get predictions for the test set
predicted = classifier.predict(X_test)
print(metrics.classification_report(y_test, predicted, target_names=label2int.keys()))
precision recall f1-score support
Sports 0.86 0.98 0.91 1900
Sci/Tech 0.76 0.84 0.80 1900
World 0.79 0.89 0.84 1900
Business 0.89 0.56 0.69 1900
accuracy 0.82 7600
macro avg 0.83 0.82 0.81 7600
weighted avg 0.83 0.82 0.81 7600
At this point, we could go back to the UI to define more rules for those labels with less performance. Looking at the above table, we might want to add some more rules for increasing the recall of the Business label.
Summary#
In this tutorial, we saw how you can leverage weak supervision to quickly build up a large training data set, and use it for the training of a first lightweight model.
Argilla is a very handy tool to start the weak supervision process by making it easy to find a good set of starting rules, and to reiterate on them dynamically. Since Argilla also provides built-in support for the most common label models, you can get from rules to weak labels in a few straight forward steps. For more suggestions on how to leverage weak labels, you can checkout our weak supervision guide where we describe an interesting approach to jointly train the label and a transformers downstream model.
Appendix I: Log datasets to the Hugging Face Hub#
Here we will show you how we pushed our Argilla datasets (records) to the Hugging Face Hub. In this way you can effectively version any of your Argilla datasets.
[ ]:
train_rg = rg.DatasetForTextClassification(label_model.predict())
train_rg.to_datasets().push_to_hub("argilla/news")
[ ]:
test_rg = rg.load("news", query="status:Validated")
test_rg.to_datasets().push_to_hub("argilla/news_test")
Next steps#
If you want to continue learning Argilla:
🙋♀️ Join the Argilla Slack community!
⭐ Argilla Github repo to stay updated.
📚 Argilla documentation for more guides and tutorials.