🕵️ Explain predictions and bias#
Explainability and bias are becoming more and more important in the world of data. Luckily, Argilla was developed with data-centricity in mind, which means we have some nice tailormade features that deal with these topics.
Token attributions#
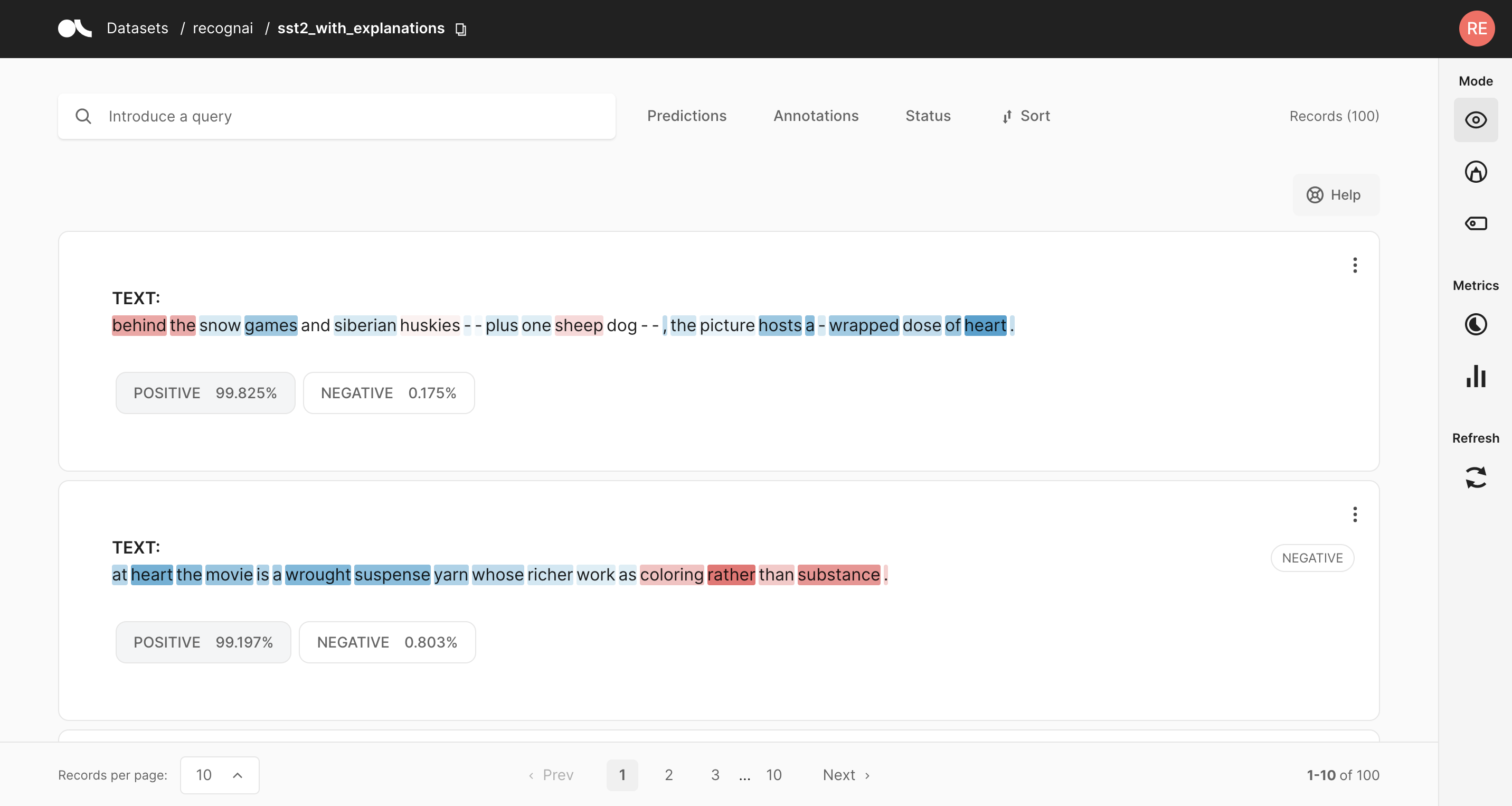
Argilla enables you to register token attributions as part of the dataset records. For getting token attributions, you can use methods such as Integrated Gradients or SHAP. These methods try to provide a mechanism to interpret model predictions. The attributions work as follows:
[0,1] Positive attributions (in blue) reflect those tokens that are making the model predict the specific predicted label.
[-1, 0] Negative attributions (in red) reflect those tokens that can influence the model to predict a label other than the specific predicted label.
import argilla as rg
from argilla import TokenAttributions, TextClassificationRecord
token_attributions = [
TokenAttributions(
token="good", attributions={"label": 1}
),
TokenAttributions(
token="and", attributions={"label": 0}
),
TokenAttributions(
token="bad", attributions={"label": -1}
)
]
record = TextClassificationRecord(
text="good and bad",
prediction=[("label", 0)],
explanation={"text": token_attributions},
)
If you want a concise example of applying token attributions, take a look here.
Certainty filters#
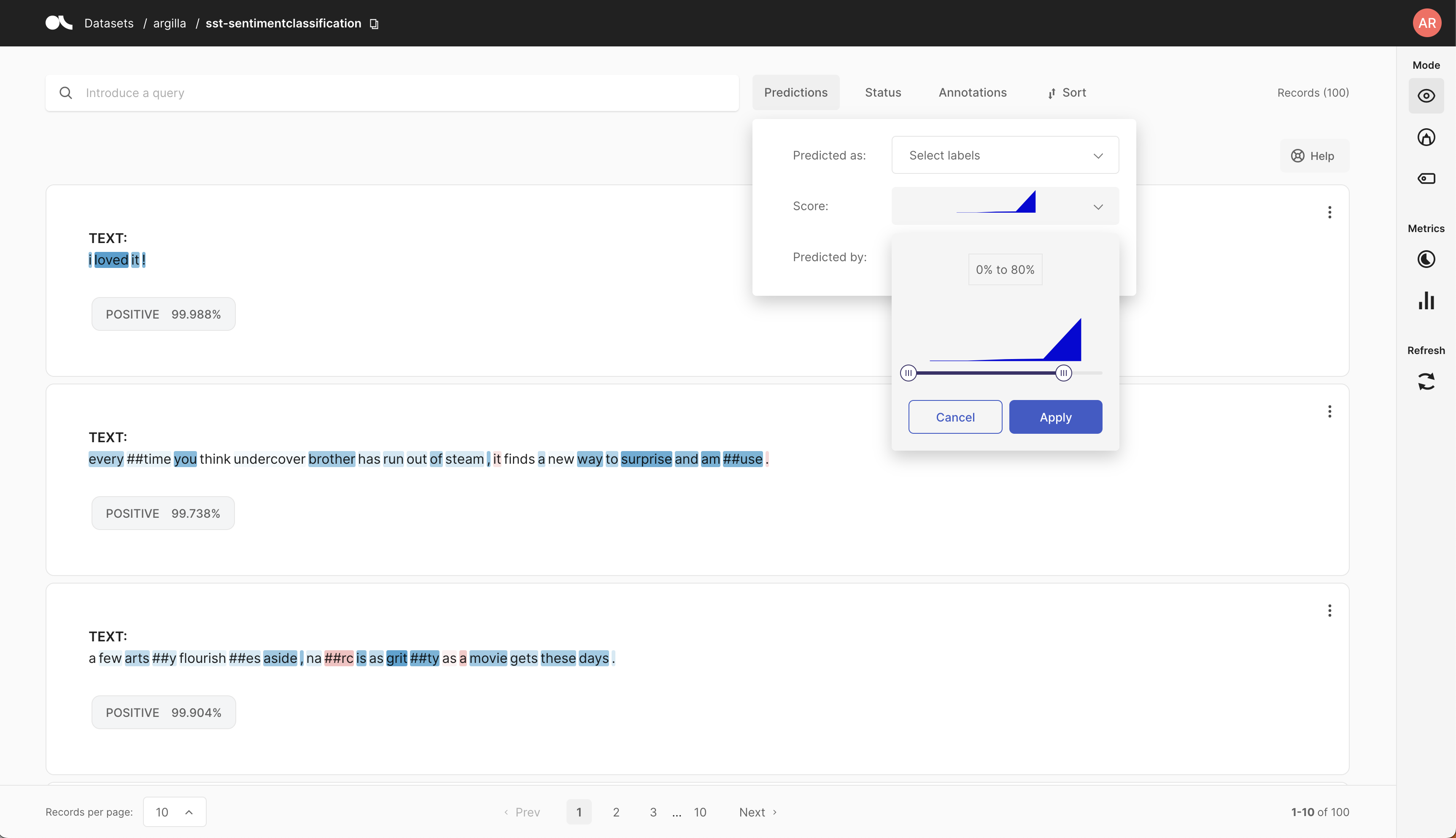
It is possible to add a certainty score to each of the logged predictions. Often, these certainty scores are already included in major packages like the predict_proba() from sklearn and the return_all_scoresfor transformers. This additional information seldom has extra significant impact on the model latency but does offer a lot of additional understanding about the performance of the model. Within our UI, it is possible to select and filter scores. We could argue that it is more relevant to start annotating less certain entries, so we could use these filters to find less certain data. Do you want a more applied example, take a look at this tutorial about TextClassification
Metrics#
The Argilla package gets shipped with build-in metrics for TextClassificationand TokenClassification. These provide insight in model performance, annotation correctness and training impact. For an overview of how to use them, take a look at our metric section.
Weak Supervision#
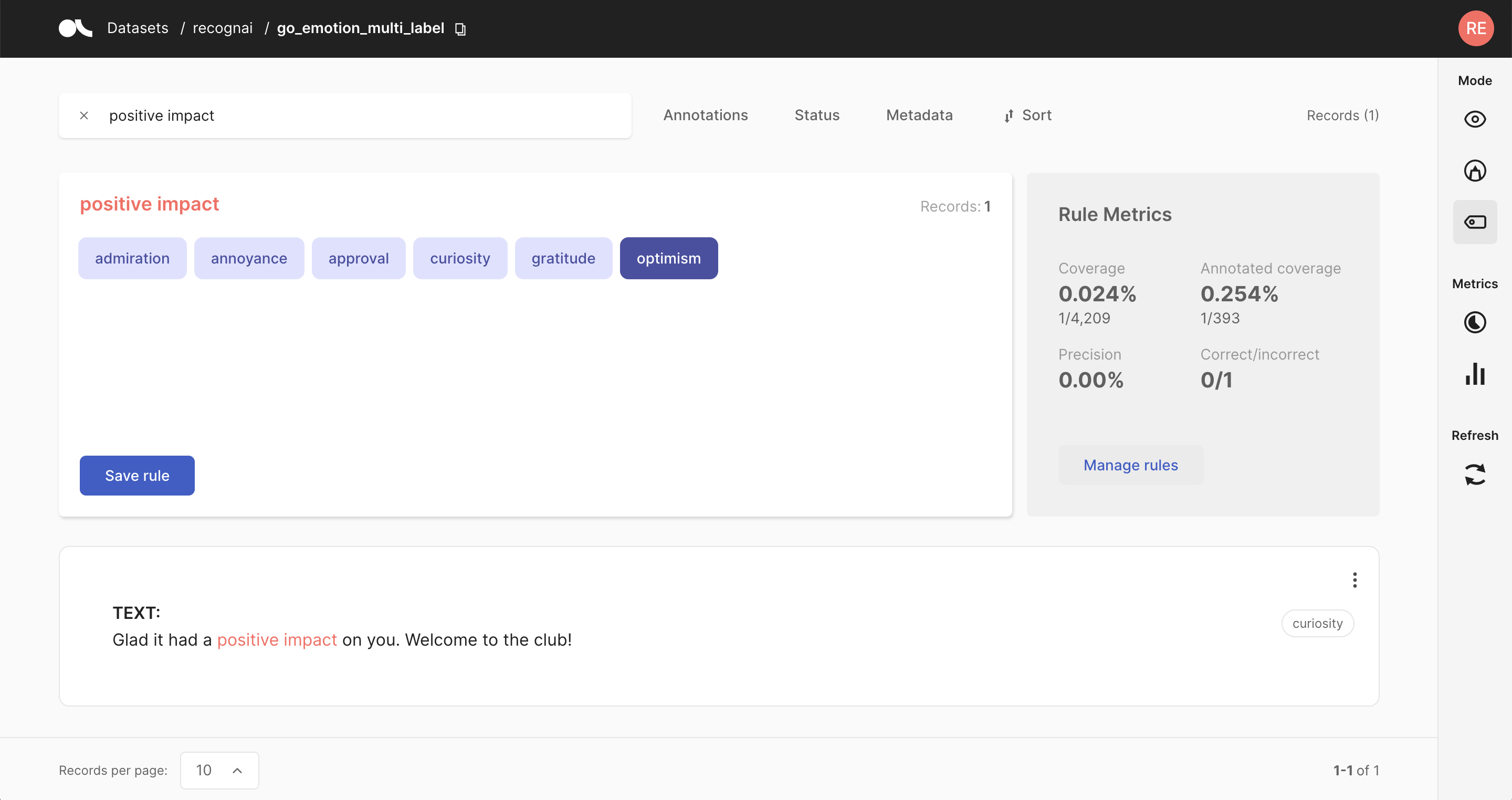
Besides our more general metrics, we also provide the option to keep track of the impact of weak supervision rules. This impact is determined by testing against verified annotated data and unannotated data, which gives you an understanding of how the rules perform in real-life and what percentage of the data is influenced by them.