🧑💻 Create a dataset#
Feedback Dataset#
Warning
The dataset class covered in this section is the FeedbackDataset. This fully configurable dataset will replace the DatasetForTextClassification, DatasetForTokenClassification, and DatasetForText2Text in Argilla 2.0. Not sure which dataset to use? Check out our section on choosing a dataset.
The Feedback Task datasets allow you to combine multiple questions of different kinds, so the first step will be to define the aim of your project and the kind of data and feedback you will need to get there. With this information, you can start configuring a dataset and formatting records using the Python SDK.
This guide will walk you through all the elements you will need to configure to create a FeedbackDataset and add records to it.
Note
To follow the steps in this guide, you will first need to connect to Argilla. Check how to do so in our cheatsheet.
Configure the dataset#
A record in Argilla refers to a data item that requires annotation and can consist of one or multiple fields i.e., the pieces of information that will be shown to the user in the UI in order to complete the annotation task. This can be, for example, a prompt and output pair in the case of instruction datasets. Additionally, the record will contain questions that the annotators will need to answer and guidelines to help them complete the task.
The FeedbackDataset has a set of predefined task templates that you can use to quickly set up your dataset. These templates include the fields and questions needed for the task, as well as the guidelines to provide to the annotators. Additionally, you can customize the fields, questions, and guidelines to fit your specific needs using a custom configuration.
Task Templates#
import argilla as rg
ds = rg.FeedbackDataset.for_text_classification(
labels=["positive", "negative"],
multi_label=False,
use_markdown=True,
guidelines=None,
metadata_properties=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="text", use_markdown=True)
# ],
# questions=[
# LabelQuestion(name="label", labels=["positive", "negative"])
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_summarization(
use_markdown=True,
guidelines=None,
metadata_properties=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="text", use_markdown=True)
# ],
# questions=[
# TextQuestion(name="summary", use_markdown=True)
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_translation(
use_markdown=True,
guidelines=None,
metadata_properties=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="source", use_markdown=True)
# ],
# questions=[
# TextQuestion(name="target", use_markdown=True)
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_natural_language_inference(
labels=None
use_markdown=True,
guidelines=None,
metadata_properties=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="premise", use_markdown=True),
# TextField(name="hypothesis", use_markdown=True)
# ],
# questions=[
# LabelQuestion(name="label", labels=["entailment", "neutral", "contradiction"])
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_sentence_similarity(
rating_scale=7,
use_markdown=True,
guidelines=None,
metadata_properties=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="sentence-1", use_markdown=True),
# TextField(name="sentence-2", use_markdown=True)
# ],
# questions=[
# RatingQuestion(name="similarity", values=[1, 2, 3, 4, 5, 6, 7])
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_question_answering(
use_markdown=True,
guidelines=None,
metadata_properties=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="question", use_markdown=True),
# TextField(name="context", use_markdown=True)
# ],
# questions=[
# TextQuestion(name="answer", use_markdown=True)
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_supervised_fine_tuning(
context=True,
use_markdown=True,
guidelines=None,
metadata_properties=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="prompt", use_markdown=True),
# TextField(name="context", use_markdown=True)
# ],
# questions=[
# TextQuestion(name="response", use_markdown=True)
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_preference_modeling(
number_of_responses=2,
context=False,
use_markdown=True,
guidelines=None,
metadata_properties=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="prompt", use_markdown=True),
# TextField(name="context", use_markdown=True),
# TextField(name="response1", use_markdown=True),
# TextField(name="response2", use_markdown=True),
# ],
# questions=[
# RankingQuestion(name="preference", values=["Response 1", "Response 2"])
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>"
# )
import argilla as rg
ds = rg.FeedbackDataset.for_proximal_policy_optimization(
rating_scale=7,
context=True,
use_markdown=True,
guidelines=None,
metadata_properties=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="prompt", use_markdown=True),
# TextField(name="context", use_markdown=True)
# ],
# questions=[
# TextQuestion(name="response", use_markdown=True)
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_direct_preference_optimization(
number_of_responses=2,
context=False,
use_markdown=True,
guidelines=None,
metadata_properties=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="prompt", use_markdown=True),
# TextField(name="context", use_markdown=True),
# TextField(name="response1", use_markdown=True),
# TextField(name="response2", use_markdown=True),
# ],
# questions=[
# RankingQuestion(name="preference", values=["Response 1", "Response 2"])
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# )
import argilla as rg
ds = rg.FeedbackDataset.for_retrieval_augmented_generation(
number_of_retrievals=1,
rating_scale=7,
use_markdown=False,
guidelines=None,
metadata_properties=None,
)
ds
# FeedbackDataset(
# fields=[
# TextField(name="query", use_markdown=False),
# TextField(name="retrieved_document_1", use_markdown=False),
# ],
# questions=[
# RatingQuestion(name="question_rating_1", values=[1, 2, 3, 4, 5, 6, 7]),
# TextQuestion(name="response", use_markdown=False),
# ],
# guidelines="<Guidelines for the task>",
# metadata_properties="<Metadata Properties>",
# )
After having initialized the FeedbackDataset templates, we can still alter the fields, questions, and guidelines to fit our specific needs using a custom configuration. Below you can find a quick example of how to alter them:
# Add new fields
ds = rg.FeedbackDataset.for_task()
new_fields=[
rg.Type_of_field(.,.,.),
rg.Type_of_field(.,.,.),
]
ds.fields.extend(new_fields)
# Remove a non-required field
ds.fields.pop(0)
# Add new questions
ds = rg.FeedbackDataset.for_task()
new_questions=[
rg.Type_of_question(.,.,.),
rg.Type_of_question(.,.,.),
]
ds.questions.extend(new_questions)
# Remove a non-required question
ds.questions.pop(0)
# Define new guidelines from the template
ds = rg.FeedbackDataset.for_task(
guidelines="New custom guidelines."
)
# Define new guidelines for a question
ds.questions[0].description = 'New description for the question.'
# Add metadata to the dataset
ds = rg.FeedbackDataset.for_task()
metadata = rg.TermsMetadataProperty(name="metadata", values=["like", "dislike"])
ds.add_metadata_property(metadata)
# Delete a metadata property
ds.delete_metadata_properties(metadata_properties="metadata")
Custom Configuration#
Define fields#
A record in Argilla refers to a data item that requires annotation and can consist of one or multiple fields i.e., the pieces of information that will be shown to the user in the UI in order to complete the annotation task. This can be, for example, a prompt and output pair in the case of instruction datasets.
As part of the FeedbackDataset configuration, you will need to specify the list of fields to show in the record card. As of Argilla 1.8.0, we only support one type of field, TextField, which is a plain text field. We have plans to expand the range of supported field types in future releases of Argilla.
You can define the fields using the Python SDK providing the following arguments:
name: The name of the field, as it will be seen internally.title(optional): The name of the field, as it will be displayed in the UI. Defaults to thenamevalue, but capitalized.required(optional): Whether the field is required or not. Defaults toTrue. Note that at least one field must be required.use_markdown(optional): Specify whether you want markdown rendered in the UI. Defaults toFalse.
fields = [
rg.TextField(name="question", required=True),
rg.TextField(name="answer", required=True, use_markdown=True),
]
Note
The order of the fields in the UI follows the order in which these are added to the fields attribute in the Python SDK.
Define questions#
To collect feedback for your dataset, you need to formulate questions. The Feedback Task currently supports the following types of questions:
RatingQuestion: These questions require annotators to select one option from a list of integer values. This type is useful for collecting numerical scores.TextQuestion: These questions offer annotators a free-text area where they can enter any text. This type is useful for collecting natural language data, such as corrections or explanations.LabelQuestion: These questions ask annotators to choose one label from a list of options. This type is useful for text classification tasks. In the UI, the labels of theLabelQuestionwill have a rounded shape.MultiLabelQuestion: These questions ask annotators to choose all applicable labels from a list of options. This type is useful for multi-label text classification tasks. In the UI, the labels of theMultiLabelQuestionwill have a squared shape.RankingQuestion: This question asks annotators to order a list of options. It is useful to gather information on the preference or relevance of a set of options. Ties are allowed and all options will need to be ranked.
You can define your questions using the Python SDK and set up the following configurations:
name: The name of the question, as it will be seen internally.title(optional): The name of the question, as it will be displayed in the UI. Defaults to thenamevalue, but capitalized.required(optional): Whether the question is required or not. Defaults toTrue. Note that at least one question must be required.description(optional): The text to be displayed in the question tooltip in the UI. You can use it to give more context or information to annotators.
The following arguments apply to specific question types:
values: In theRatingQuestionthis will be any list of unique integers that represent the options that annotators can choose from. These values must be defined in the range [1, 10]. In theRankingQuestion, values will be a list of strings with the options they will need to rank. If you’d like the text of the options to be different in the UI and internally, you can pass a dictionary instead where the key is the internal name and the value is the text to display in the UI.labels: InLabelQuestionandMultiLabelQuestionthis is a list of strings with the options for these questions. If you’d like the text of the labels to be different in the UI and internally, you can pass a dictionary instead where the key is the internal name and the value the text to display in the UI.visible_labels(optional): InLabelQuestionandMultiLabelQuestionthis is the number of labels that will be visible in the UI. By default, the UI will show 20 labels and collapse the rest. Set your preferred number to change this limit or setvisible_labels=Noneto show all options.use_markdown(optional): InTextQuestiondefine whether the field should render markdown text. Defaults toFalse.
Check out the following tabs to learn how to set up questions according to their type:
rg.LabelQuestion(
name="relevant",
title="Is the response relevant for the given prompt?",
labels={"YES": "Yes", "NO": "No"}, # or ["YES","NO"]
required=True,
visible_labels=None
)

rg.MultiLabelQuestion(
name="content_class",
title="Does the response include any of the following?",
description="Select all that apply",
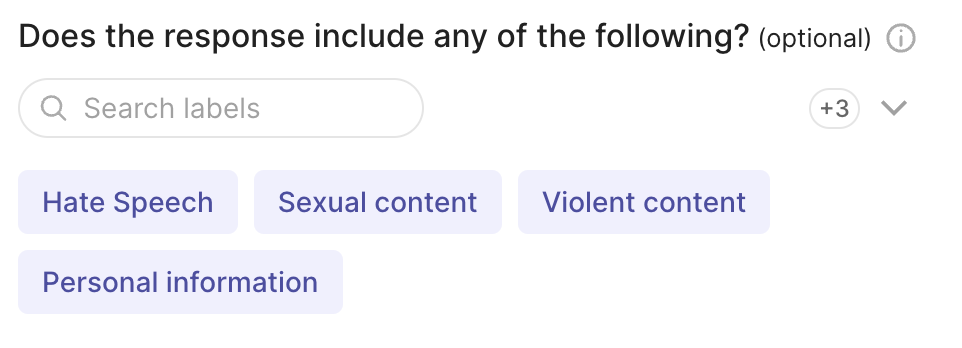
labels={"hate": "Hate Speech" , "sexual": "Sexual content", "violent": "Violent content", "pii": "Personal information", "untruthful": "Untruthful info", "not_english": "Not English", "inappropriate": "Inappropriate content"}, # or ["hate", "sexual", "violent", "pii", "untruthful", "not_english", "inappropriate"]
required=False,
visible_labels=4
)
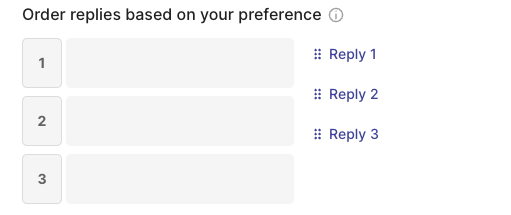
rg.RankingQuestion(
name="preference",
title="Order replies based on your preference",
description="1 = best, 3 = worst. Ties are allowed.",
required=True,
values={"reply-1": "Reply 1", "reply-2": "Reply 2", "reply-3": "Reply 3"} # or ["reply-1", "reply-2", "reply-3"]
)
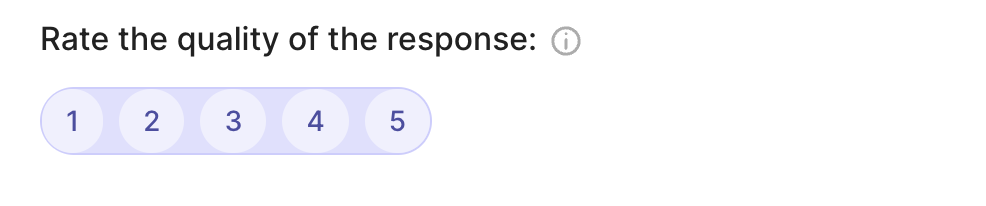
rg.RatingQuestion(
name="quality",
title="Rate the quality of the response:",
description="1 = very bad - 5= very good",
required=True,
values=[1, 2, 3, 4, 5]
)
rg.TextQuestion(
name="corrected-text",
title="Provide a correction to the response:",
required=False,
use_markdown=True
)

Define metadata properties#
Metadata properties allow you to configure the use of metadata information for the filtering and sorting features available in the UI and Python SDK.
You can define metadata properties using the Python SDK by providing the following arguments:
name: The name of the metadata property, as it will be used internally.title(optional): The name of the metadata property, as it will be displayed in the UI. Defaults to thenamevalue, but capitalized.visible_for_annotators(optional): A boolean to specify whether the metadata property will be accessible for users with anannotatorrole in the UI (True), or if it will only be visible for users withowneroradminroles (False). It is set toTrueby default.
The following arguments apply to specific metadata types:
values(optional): In aTermsMetadataProperty, you can pass a list of valid values for this metadata property, in case you want to run a validation. If none are provided, the list of values will be computed from the values provided in the records.min(optional): In anIntegerMetadataPropertyor aFloatMetadataProperty, you can pass a minimum valid value. If none is provided, the minimum value will be computed from the values provided in the records.max(optional): In anIntengerMetadataPropertyor aFloatMetadataProperty, you can pass a maximum valid value. If none is provided, the maximum value will be computed from the values provided in the records.
rg.TermsMetadataProperty(
name="groups",
title="Annotation groups",
values=["group-a", "group-b", "group-c"] #optional
)
rg.IntegerMetadataProperty(
name="integer-metadata",
title="Integers",
min=0, #optional
max=100, #optional
visible_for_annotators=False
)
rg.FloatMetadataProperty(
name="float-metadata",
title="Floats",
min=-0.45, #optional
max=1000.34, #optional
visible_for_annotators=False
)
Note
You can also define metadata properties after the dataset has been configured or add them to an existing dataset in Argilla. To do that use the add_metadata_property method as explained here.
Define guidelines#
Once you have decided on the data to show and the questions to ask, it’s important to provide clear guidelines to the annotators. These guidelines help them understand the task and answer the questions consistently. You can provide guidelines in two ways:
In the dataset guidelines: this is added as an argument when you create your dataset in the Python SDK (see below). It will appear in the dataset settings in the UI.
As question descriptions: these are added as an argument when you create questions in the Python SDK (see above). This text will appear in a tooltip next to the question in the UI.
It is good practice to use at least the dataset guidelines if not both methods. Question descriptions should be short and provide context to a specific question. They can be a summary of the guidelines to that question, but often that is not sufficient to align the whole annotation team. In the guidelines, you can include a description of the project, details on how to answer each question with examples, instructions on when to discard a record, etc.
Create the dataset#
Once the scope of the project is defined, which implies knowing the fields, questions and guidelines (if applicable), you can proceed to create the FeedbackDataset. To do so, you will need to define the following arguments:
fields: The list of fields to show in the record card. The order in which the fields will appear in the UI matches the order of this list.questions: The list of questions to show in the form. The order in which the questions will appear in the UI matches the order of this list.guidelines(optional): A set of guidelines for the annotators. These will appear in the dataset settings in the UI.metadata(optional): The list of metadata properties included in this dataset.extra_metadata_properties(optional): A boolean to specify whether this dataset will allow metadata fields in the records other than those specified undermetadata. Note that these will not be accessible from the UI for any user, only retrievable using the Python SDK.
If you haven’t done so already, check the sections above to learn about each of them.
Below you can find a quick example where we create locally a FeedbackDataset to assess the quality of a response in a question-answering task. The FeedbackDataset contains two fields, question and answer, and two questions to measure the quality of the answer and to correct it if needed.
dataset = rg.FeedbackDataset(
guidelines="Please, read the question carefully and try to answer it as accurately as possible.",
fields=[
rg.TextField(name="question"),
rg.TextField(name="answer"),
],
questions=[
rg.RatingQuestion(
name="answer_quality",
description="How would you rate the quality of the answer?",
values=[1, 2, 3, 4, 5],
),
rg.TextQuestion(
name="answer_correction",
description="If you think the answer is not accurate, please, correct it.",
required=False,
),
],
metadata_properties = [
rg.TermsMetadataProperty(
name="groups",
title="Annotation groups",
values=["group-a", "group-b", "group-c"] #optional
),
rg.FloatMetadataProperty(
name="temperature",
min=-0, #optional
max=1, #optional
visible_for_annotators=False
)
],
allow_extra_metadata = False
)
Note
After configuring your dataset, you can still edit the main information such as field titles, questions, descriptions, and markdown format from the UI. More info in dataset settings.
Note
Fields and questions in the UI follow the order in which these are added to the fields and questions attributes in the Python SDK.
Hint
If you are working as part of an annotation team and you would like to control how much overlap you’d like to have between your annotators, you should consider the different workflows in the Set up your annotation team guide before configuring and pushing your dataset.
Add records#
At this point, we just need to add records to our FeedbackDataset. Take some time to explore and find data that fits the purpose of your project. If you are planning to use public data, the Datasets page of the Hugging Face Hub is a good place to start.
Tip
If you are using a public dataset, remember to always check the license to make sure you can legally employ it for your specific use case.
from datasets import load_dataset
# Load and inspect a dataset from the Hugging Face Hub
hf_dataset = load_dataset('databricks/databricks-dolly-15k', split='train')
df = hf_dataset.to_pandas()
df
Hint
Take some time to inspect the data before adding it to the dataset in case this triggers changes in the questions or fields.
The next step is to create records following Argilla’s FeedbackRecord format. These are the attributes of a FeedbackRecord:
fields: A dictionary with the name (key) and content (value) of each of the fields in the record. These will need to match the fields set up in the dataset configuration (see Define record fields).external_id(optional): An ID of the record defined by the user. If there is no external ID, this will beNone.metadata(optional): A dictionary with the metadata of the record. This can include any information about the record that is not part of the fields. If you want the metadata to correspond with the metadata properties configured for your dataset, make sure that the key of the dictionary corresponds with the metadata propertyname. When the key doesn’t correspond, this will be considered extra metadata that will get stored with the record, but will not be usable for filtering and sorting. If there is no metadata, this will beNone.suggestions(optional): A list of all suggested responses for a record e.g., model predictions or other helpful hints for the annotators. Just one suggestion can be provided for each question, and suggestion values must be compliant with the pre-defined questions e.g. if we have aRatingQuestionbetween 1 and 5, the suggestion should have a valid value within that range. If suggestions are added, they will appear in the UI as pre-filled responses.responses(optional): A list of all responses to a record. You will only need to add them if your dataset already has some annotated records. Make sure that the responses adhere to the same format as Argilla’s output and meet the schema requirements for the specific type of question being answered. Also make sure to includeuser_ids in case you’re planning to add more than one response for the same question, as only oneuser_idcan be None, later to be replaced by the current activeuser_id, while the rest will be discarded otherwise.
# Create a single Feedback Record
record = rg.FeedbackRecord(
fields={
"question": "Why can camels survive long without water?",
"answer": "Camels use the fat in their humps to keep them filled with energy and hydration for long periods of time."
},
metadata={"source": "encyclopedia"},
external_id=None
)
As an example, here is how you can transform a whole dataset into records at once, renaming the fields and optionally filtering the original dataset:
records = [rg.FeedbackRecord(fields={"question": record["instruction"], "answer": record["response"]}) for record in hf_dataset if record["category"]=="open_qa"]
Now, we simply add our records to the dataset we configured above:
# Add records to the dataset
dataset.add_records(records)
Add suggestions#
Suggestions refer to suggested responses (e.g. model predictions) that you can add to your records to make the annotation process faster. These can be added during the creation of the record or at a later stage. Only one suggestion can be provided for each question, and suggestion values must be compliant with the pre-defined questions e.g. if we have a RatingQuestion between 1 and 5, the suggestion should have a valid value within that range.
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "relevant",
"value": "YES",
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "content_class",
"value": ["hate", "violent"]
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "preference",
"value":[
{"rank": 1, "value": "reply-2"},
{"rank": 2, "value": "reply-1"},
{"rank": 3, "value": "reply-3"},
],
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "quality",
"value": 5,
}
]
)
record = rg.FeedbackRecord(
fields=...,
suggestions = [
{
"question_name": "corrected-text",
"value": "This is a *suggestion*.",
}
]
)
You can also add suggestions to existing records that have been already pushed to Argilla:
import argilla as rg
rg.init(api_url="<ARGILLA_API_URL>", api_key="<ARGILLA_API_KEY>")
dataset = rg.FeedbackDataset.from_argilla(name="my_dataset", workspace="my_workspace")
for record in dataset.records:
record.update(suggestions=[{"question_name": "question", "value": ...}]) # Directly pushes the update to Argilla
for record in dataset.records:
record.set_suggestions([{"question_name": "question", "value": ...}])
dataset.push_to_argilla() # No need to provide `name` and `workspace` as has been retrieved via `from_argilla` classmethod
Add responses#
If your dataset includes some annotations, you can add those to the records as you create them. Make sure that the responses adhere to the same format as Argilla’s output and meet the schema requirements for the specific type of question being answered. Note that just one response with an empty user_id can be specified, as the first occurrence of user_id=None will be set to the active user_id, while the rest of the responses with user_id=None will be discarded.
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"relevant":{
"value": "YES"
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"content_class":{
"value": ["hate", "violent"]
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"preference":{
"value":[
{"rank": 1, "value": "reply-2"},
{"rank": 2, "value": "reply-1"},
{"rank": 3, "value": "reply-3"},
],
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"quality":{
"value": 5
}
}
}
]
)
record = rg.FeedbackRecord(
fields=...,
responses = [
{
"values":{
"corrected-text":{
"value": "This is a *response*."
}
}
}
]
)
Push to Argilla#
To import the dataset to your Argilla instance you can use the push_to_argilla method from your FeedbackDataset instance. Once pushed, you will be able to see your dataset in the UI.
Note
From Argilla 1.14.0, calling push_to_argilla will not just push the FeedbackDataset into Argilla, but will also return the remote FeedbackDataset instance, which implies that the additions, updates, and deletions of records will be pushed to Argilla as soon as they are made. This is a change from previous versions of Argilla, where you had to call push_to_argilla again to push the changes to Argilla.
remote_dataset = dataset.push_to_argilla(name="my-dataset", workspace="my-workspace")
dataset.push_to_argilla(name="my-dataset", workspace="my-workspace")
Now you’re ready to start the annotation process.
Other Datasets#
Warning
The records classes covered in this section correspond to three datasets: DatasetForTextClassification, DatasetForTokenClassification, and DatasetForText2Text. These will be deprecated in Argilla 2.0 and replaced by the fully configurable FeedbackDataset class. Not sure which dataset to use? Check out our section on choosing a dataset.
Under the hood, the Dataset classes store the records in a simple Python list. Therefore, working with a Dataset class is not very different from working with a simple list of records, but before creating a dataset we should first define dataset settings and a labeling schema.
Argilla datasets have certain settings that you can configure via the rg.*Settings classes, for example, rg.TextClassificationSettings. The Dataset classes do some extra checks for you, to make sure you do not mix record types when appending or indexing into a dataset.
Configure the Dataset#
You can define your Argilla dataset, which sets the allowed labels for your predictions and annotations. Once you set a labeling schema, each time you log into the corresponding dataset, Argilla will perform validations of the added predictions and annotations to make sure they comply with the schema. You can set your labels using the code below or from the Dataset settings page in the UI.
If you forget to define a labeling schema, Argilla will aggregate the labels it finds in the dataset automatically, but you will need to validate it. To do this, go to your Dataset settings page and click Save schema.
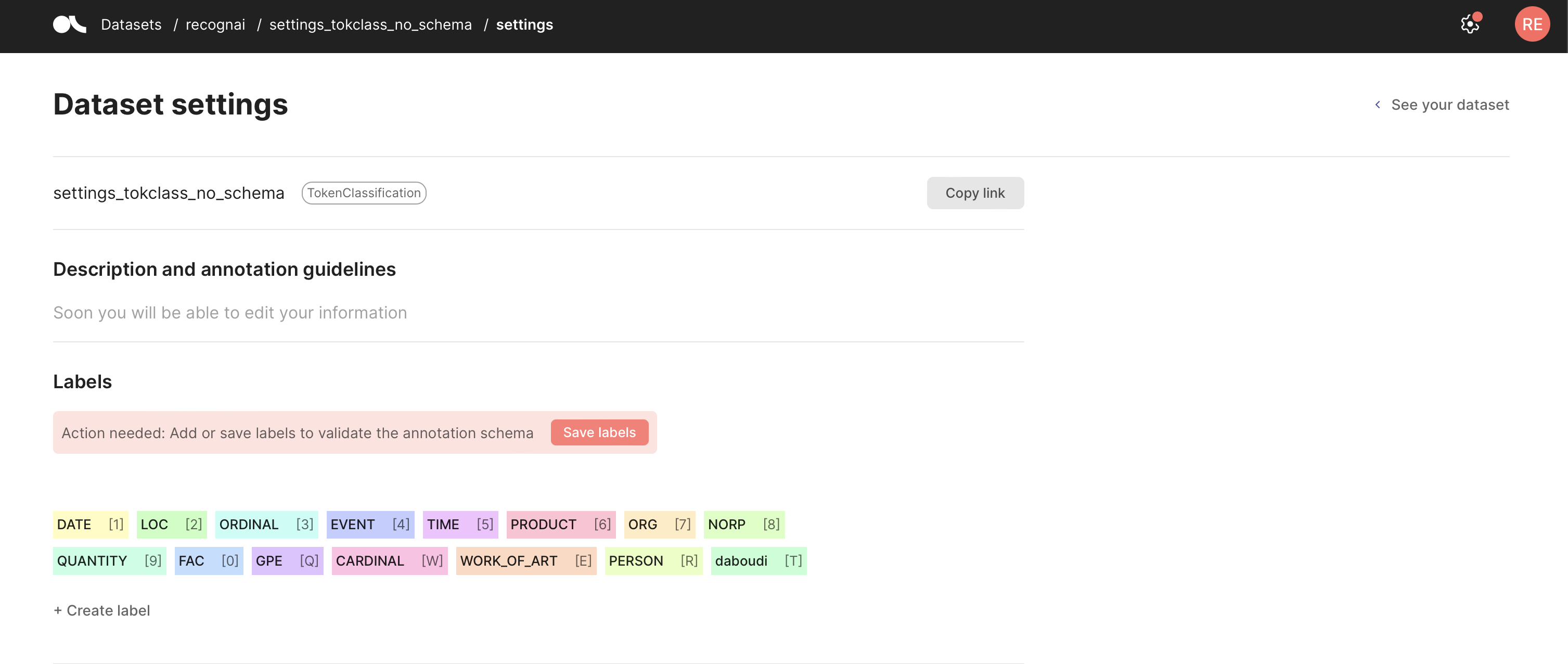
import argilla as rg
settings = rg.TextClassificationSettings(label_schema=["A", "B", "C"])
rg.configure_dataset_settings(name="my_dataset", settings=settings)
import argilla as rg
settings = rg.TokenClassificationSettings(label_schema=["A", "B", "C"])
rg.configure_dataset_settings(name="my_dataset", settings=settings)
Because we do not require a labeling schema for Text2Text, we can create a dataset by directly logging records via rg.log().
Add records#
The main component of the Argilla data model is called a record. A dataset in Argilla is a collection of these records. Records can be of different types depending on the currently supported tasks:
TextClassificationRecordTokenClassificationRecordText2TextRecord
The most critical attributes of a record that are common to all types are:
text: The input text of the record (Required);annotation: Annotate your record in a task-specific manner (Optional);prediction: Add task-specific model predictions to the record (Optional);metadata: Add some arbitrary metadata to the record (Optional);
Some other cool attributes for a record are:
vectors: Input vectors to enable semantic search.explanation: Token attributions for highlighting text.
In Argilla, records are created programmatically using the client library within a Python script, a Jupyter notebook, or another IDE.
Let’s see how to create and upload a basic record to the Argilla web app (make sure Argilla is already installed on your machine as described in the setup guide).
We support different tasks within the Argilla eco-system focused on NLP: Text Classification, Token Classification and Text2Text.
import argilla as rg
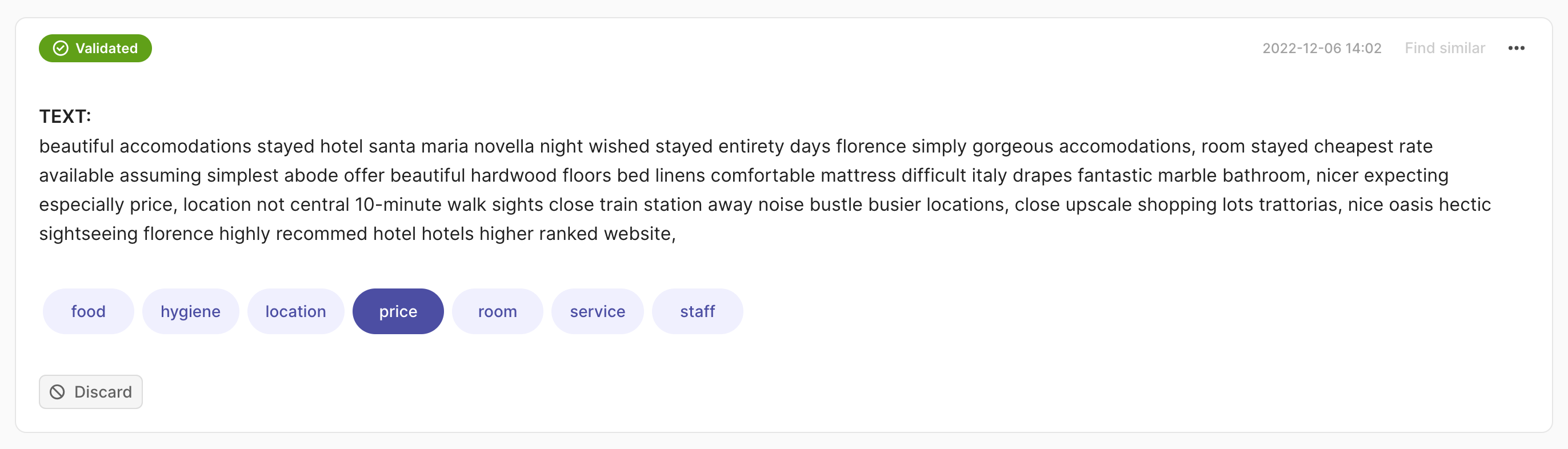
rec = rg.TextClassificationRecord(
text="beautiful accomodations stayed hotel santa... hotels higer ranked website.",
prediction=[("price", 0.75), ("hygiene", 0.25)],
annotation="price"
)
rg.log(records=rec, name="my_dataset")
import argilla as rg
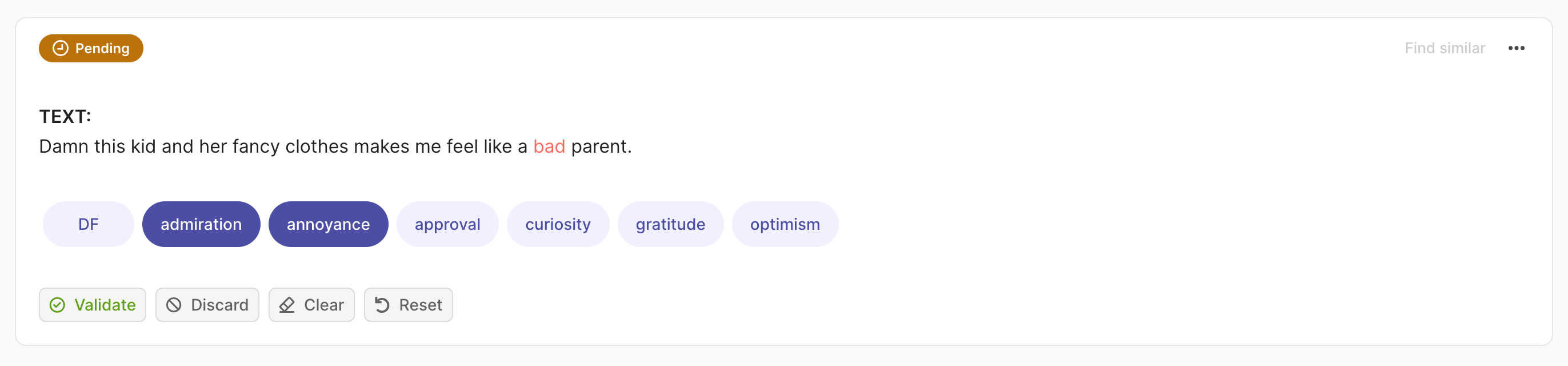
rec = rg.TextClassificationRecord(
text="damn this kid and her fancy clothes make me feel like a bad parent.",
prediction=[("admiration", 0.75), ("annoyance", 0.25)],
annotation=["price", "annoyance"],
multi_label=True
)
rg.log(records=rec, name="my_dataset")
import argilla as rg
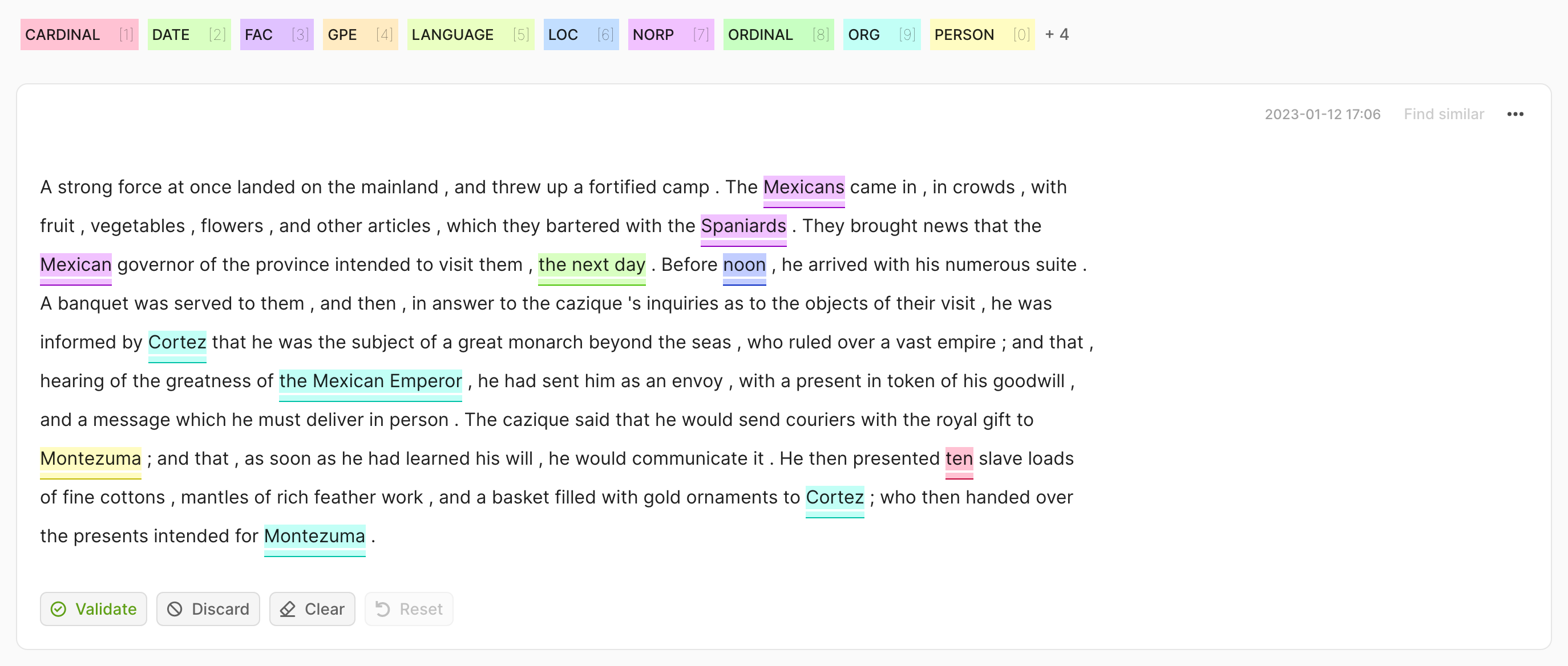
rec = rg.TokenClassificationRecord(
text="Michael is a professor at Harvard",
tokens=["Michael", "is", "a", "professor", "at", "Harvard"],
prediction=[("NAME", 0, 7, 0.75), ("LOC", 26, 33, 0.8)],
annotation=[("NAME", 0, 7), ("LOC", 26, 33)],
)
rg.log(records=rec, name="my_dataset")
import argilla as rg
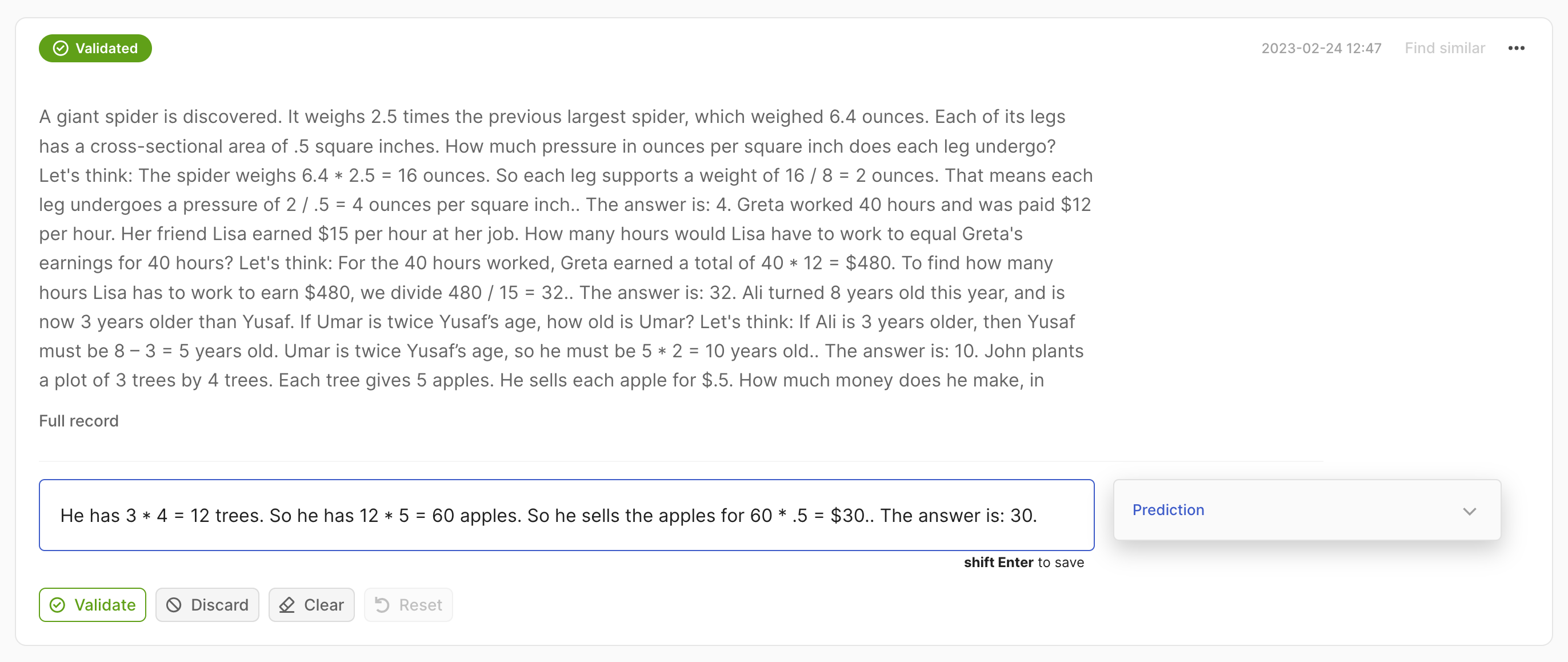
rec = rg.Text2TextRecord(
text="A giant giant spider is discovered... how much does he make in a year?",
prediction=["He has 3*4 trees. So he has 12*5=60 apples."],
)
rg.log(records=rec, name="my_dataset")
Add suggestions#
Suggestions refer to suggested responses (e.g. model predictions) that you can add to your records to make the annotation process faster. These can be added during the creation of the record or at a later stage. We allow for multiple suggestions per record.
In this case, we expect a List[Tuple[str, float]] as the prediction, where the first element of the tuple is the label and the second the confidence score.
import argilla as rg
rec = rg.TextClassificationRecord(
text=...,
prediction=[("label_1", 0.75), ("label_2", 0.25)],
)
In this case, we expect a List[Tuple[str, float]] as the prediction, where the second element of the tuple is the confidence score of the prediction. In the case of multi-label, the multi_label attribute of the record should be set to True.
import argilla as rg
rec = rg.TextClassificationRecord(
text=...,
prediction=[("label_1", 0.75), ("label_2", 0.75)],
multi_label=True
)
In this case, we expect a List[Tuple[str, int, int, float]] as the prediction, where the second and third elements of the tuple are the start and end indices of the token in the text.
import argilla as rg
rec = rg.TokenClassificationRecord(
text=...,
tokens=...,
prediction=[("label_1", 0, 7, 0.75), ("label_2", 26, 33, 0.8)],
)
In this case, we expect a List[str] as the prediction.
import argilla as rg
rec = rg.Text2TextRecord(
text=...,
prediction=["He has 3*4 trees. So he has 12*5=60 apples."],
)
Add annotations#
If your dataset includes some annotations, you can add those to the records as you create them. Make sure that the responses adhere to the same format as Argilla’s output and meet the schema requirements.
In this case, we expect a str as the annotation.
import argilla as rg
rec = rg.TextClassificationRecord(
text=...,
annotation="label_1",
)
In this case, we expect a List[str] as the annotation. In case of multi-label, the multi_label attribute of the record should be set to True.
import argilla as rg
rec = rg.TextClassificationRecord(
text=...,
annotation=["label_1", "label_2"],
multi_label=True
)
In this case, we expect a List[Tuple[str, int, int]] as the annotation, where the second and third elements of the tuple are the start and end indices of the token in the text.
import argilla as rg
rec = rg.TokenClassificationRecord(
text=...,
tokens=...,
annotation=[("label_1", 0, 7), ("label_2", 26, 33)],
)
In this case, we expect a str as the annotation.
import argilla as rg
rec = rg.Text2TextRecord(
text=...,
annotation="He has 3*4 trees. So he has 12*5=60 apples.",
)
Push to Argilla#
We can push records to Argilla using the rg.log() function. This function takes a list of records and the name of the dataset to which we want to push the records.
import argilla as rg
rec = rg.TextClassificationRecord(
text="beautiful accomodations stayed hotel santa... hotels higer ranked website.",
prediction=[("price", 0.75), ("hygiene", 0.25)],
annotation="price"
)
rg.log(records=rec, name="my_dataset")