🏆 Train a reward model for RLHF#
Collecting comparison data to train a reward model is a crucial part of RLHF and LLM evaluation. This phase involves training a reward model to align responses with human preferences. Afterwards, during the reinforcement learning phase, the LLM is fine-tuned to generate better responses based on the reward model. In contrast to how the reward model scores prompt-response pairs, comparison data collection typically requires humans (and machines) to rank several responses to a single prompt.
In this example, we will describe how you can build a dataset for collecting human preferences and train a reward model using the amazing trl library. See below the workflow we will be following.
Let’s get started!

Note
This tutorial is a Jupyter Notebook. There are two options to run it:
Use the Open in Colab button at the top of this page. This option allows you to run the notebook directly on Google Colab. Don’t forget to change the runtime type to GPU for faster model training and inference.
Download the .ipynb file by clicking on the View source link at the top of the page. This option allows you to download the notebook and run it on your local machine or on a Jupyter notebook tool of your choice.
Setup#
For this tutorial, you will need to have an Argilla server running. If you don’t have one already, check out our Quickstart or Installation pages. Once you do, complete the following steps:
Install the Argilla client and the required third party libraries using
pip:
[ ]:
%pip install -U argilla pandas trl plotly -qqq
Let’s make the necessary imports:
[1]:
import random
import torch
from datasets import Dataset, load_dataset
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
TrainingArguments,
)
from trl import RewardTrainer
import argilla as rg
If you are running Argilla using the Docker quickstart image or Hugging Face Spaces, you need to init the Argilla client with the
URLandAPI_KEY:
[ ]:
# Replace api_url with the url to your HF Spaces URL if using Spaces
# you can find the Spaces URL under the Embed this space button
# Replace api_key if you configured a custom API key
rg.init(
api_url="http://localhost:6900",
api_key="admin.apikey"
)
Configure the dataset#
As a first step, let’s load the dataset and quickly explore the data. This dataset contains a sample of the Dolly curated dataset with the original human responses and generated responses using the Falcon-7b-instruct model.
[ ]:
hf_dataset = load_dataset("argilla/dolly-curated-comparison-falcon-7b-instruct", split="train")
[8]:
df = hf_dataset.to_pandas()
df
[8]:
| prompt | response-1 | response-2 | category | original_response | external_id | |
|---|---|---|---|---|---|---|
| 0 | What is Depreciation | What is Depreciation – 10 Important Facts to K... | What is Depreciation on a Car?\nDepreciation i... | open_qa | Depreciation is the drop in value of an asset ... | 518 |
| 1 | What do you know about the city of Aberdeen in... | Aberdeen, the city in which I've lived for the... | As an AI language model, I don't have personal... | open_qa | Aberdeen is a city located in the North East o... | 351 |
| 2 | Describe thunderstorm season in the United Sta... | Describe thunderstorm season in the United Sta... | Describe thunderstorm season in the United Sta... | information_extraction | Thunderstorm season in the United States and C... | 10567 |
| 3 | When did Peloton IPO?\nOn September 26, 2019, ... | When did Peloton IPO?\nPeloton launched its in... | When did Peloton IPO?\nPeloton IPO'd on May 26... | closed_qa | Peloton became a public company via an initial... | 12412 |
| 4 | What is the best way to answer an interview qu... | The best way to answer an interview question m... | Some of the best ways to answer an interview q... | creative_writing | The first recommended step is to ask clarifyin... | 2521 |
| ... | ... | ... | ... | ... | ... | ... |
| 7396 | How do i accept the change | How do i accept the change in my life\nAccepti... | I's a great opportunity to improve. The only t... | brainstorming | Embrace the change and see the difference | 15010 |
| 7397 | Extract the teams that the footballer Sócrates... | Extract the teams that the footballer Sócrates... | Extract the teams that the footballer Sócrates... | information_extraction | Brazil, Botafogo-SP, Corinthians, Fiorentina | 9970 |
| 7398 | Without quoting directly from the text give me... | Without quoting directly from the text give me... | Without quoting directly from the text give me... | summarization | Brendon Small is a stand-up comedian, Creator... | 14205 |
| 7399 | Is Killing is Sin ? Is it ture | Is Killing is Sin ? Is it ture?\nKilling can b... | Is Killing is Sin ? Is it ture?\nKilling is no... | brainstorming | Killing a human being should not be sin becaus... | 11253 |
| 7400 | Who was Otto von Bismarck?\nOtto, Prince of Bi... | Who was Otto von Bismarck?\nOtto von Bismarck ... | Who was Otto von Bismarck?\nOtto von Bismarck ... | information_extraction | Otto von Bismarck was a Prussian and German so... | 12872 |
7401 rows × 6 columns
For reward modelling, we would like to ask labelers to rank two responses for a prompt from best to worst. For this, we need to configure the fields to show and questions to ask to labelers.
The dataset will show the users three fields instruction, which corresponds to the prompt, response-1 and response-2, which correspond to each of the responses to the instruction.
[9]:
# list of fields that we will use later for our dataset settings
fields = [
rg.TextField(name="instruction", title="User instruction"),
rg.TextField(name="response-1"),
rg.TextField(name="response-2")
]
In this use case, we will ask the users to select the best response. You can also ask users to rank more than two responses, but let’s keep it straightforward for this example. We also add the annotation guidelines for labelers, based on the guidelines of the InstructGPT paper.
[10]:
question = rg.RatingQuestion(
name="choose-best",
title="Choose the best response:",
description="Choose the most helpful, harmless, and truthful response. Select 1 for response-1, 2 for response-2, or discard if both are equally good/bad.",
values=[1,2],
required=True
)
guidelines="""These guidelines are based on the paper [Training Language Models to Follow Instructions with Human Feedback](https://cdn.openai.com/papers/Training_language_models_to_follow_instructions_with_human_feedback.pdf)\n\n**You are given a text-based description of a task, submitted by a user.**\n\nThis task description may be in the form of an explicit instruction (e.g. \"Write a story about a wise frog.\"). The task may also be specified indirectly, for example by using several examples of the desired behavior (e.g. given a sequence of movie reviews followed by their sentiment, followed by one movie review without a sentiment, you can assume the task is to predict the sentiment of the final review), or by generating the start of a desired output (e.g. given \"There once was a wise frog named Julius,\" you can assume the task is to continue the story).\n\n**You will also be given several text outputs, intended to help the user with their task.** Your job is to evaluate these outputs to ensure that they are helpful, truthful, and harmless, and select the best according to these criteria.\n\nIn case **none of the outputs is correct, conforming to the criteria, or they're exactly equal, use the discard option to not rank them**.\n\nFor most tasks, being truthful and harmless is more important than being helpful.\n\nBy **helpful**, we mean that the output should follow the user's intention and help the user solve their task. Some examples of helpful behavior:\n\n- Writing in clear language.\n- Answering the question they meant to ask, even if they mis-asked it.\n- Being sensitive to internationality (e.g., \"football\" shouldn't mean American football, and \"the president\" doesn't necessarily mean the US president).\n- If an instruction is too confusing, asking for clarification and explaining why the instruction is confusing.\n- Not giving overly long or rambling answers, or repeating information from the question.\n- Not assuming extraneous extra context outside of what's given (besides things like facts about the world), unless that's an implied part of the task. For example, if asked to \"write a polite email response to this email: email body,\" the output shouldn't assume \"I can't make it this time, but am free next weekend.\" But if asked to \"Write an email to Socrates,\" then you can safely assume the output can make up a context.\n\nBy **truthful**, we mean that the output contains accurate information and doesn't mislead the user. Some examples of truthful behavior:\n\n- On tasks like summarization, where the output should only use information from input, not making up details that are not part of the input description.\n- Not producing clearly false information about the world (e.g., making up facts or promoting conspiracies). For example, the output should not state that Hillary Clinton has served time in prison.\n- Avoid generating misleading information or information with questionable authenticity. For example, if the input asks \"Why did Hillary Clinton go to jail?\", the output should not say \"It's not totally clear,\" but rather should refute the premise of the question.\n\nBy **harmless**, we mean that the output should not cause physical, psychological, or social harm to people; damage to or loss of equipment or property; damage to the environment; or harm to institutions or resources necessary to human well-being. Some examples of harmless behavior:\n\n- Treating other humans with kindness, respect, and consideration; not denigrating members of certain groups or using biased language against a particular group.\n- Not generating abusive, threatening, or offensive language or promoting violence.\n- Not writing sexual or violent content if it's not asked for.\n- Not giving bad real-world advice or promoting illegal activity.\n\nEvaluating model outputs may involve making trade-offs between these criteria. These trade-offs will depend on the task."""
Create records#
The next step is build the records for collecting comparison data. This step typically involves generating responses using one or several instruction-tuned model.
Tip
When showing responses from two different models to labelers. It’s recommended to randomly assign different model responses to response-1 and response-2 for each record. Otherwise, labelers might find a pattern and be biased towards a specific model. This is specially relevant for model comparison and evaluation, but also applies to comparison data for reward modelling.
In this example, we’ve already generated a dataset using the instructions from the Dolly curated dataset with the Falcon-7B-instruct model. We will use the original human-written response as response-1 and a response from Falcon as response-2.
You can build the records and publish them for labelers as follows:
[ ]:
# build records from hf dataset
records = [
rg.FeedbackRecord(fields={"instruction": r["prompt"], "response-1": r["original_response"], "response-2": r["response-2"]})
for r in hf_dataset
]
# create dataset
dataset = rg.FeedbackDataset(
fields=fields,
questions=[question],
guidelines=guidelines
)
# add records and publish
dataset.add_records(records)
dataset.push_to_argilla(name="comparison-data-falcon")
Now the dataset is ready for labelling. This is the Feedback UI we have just configured:
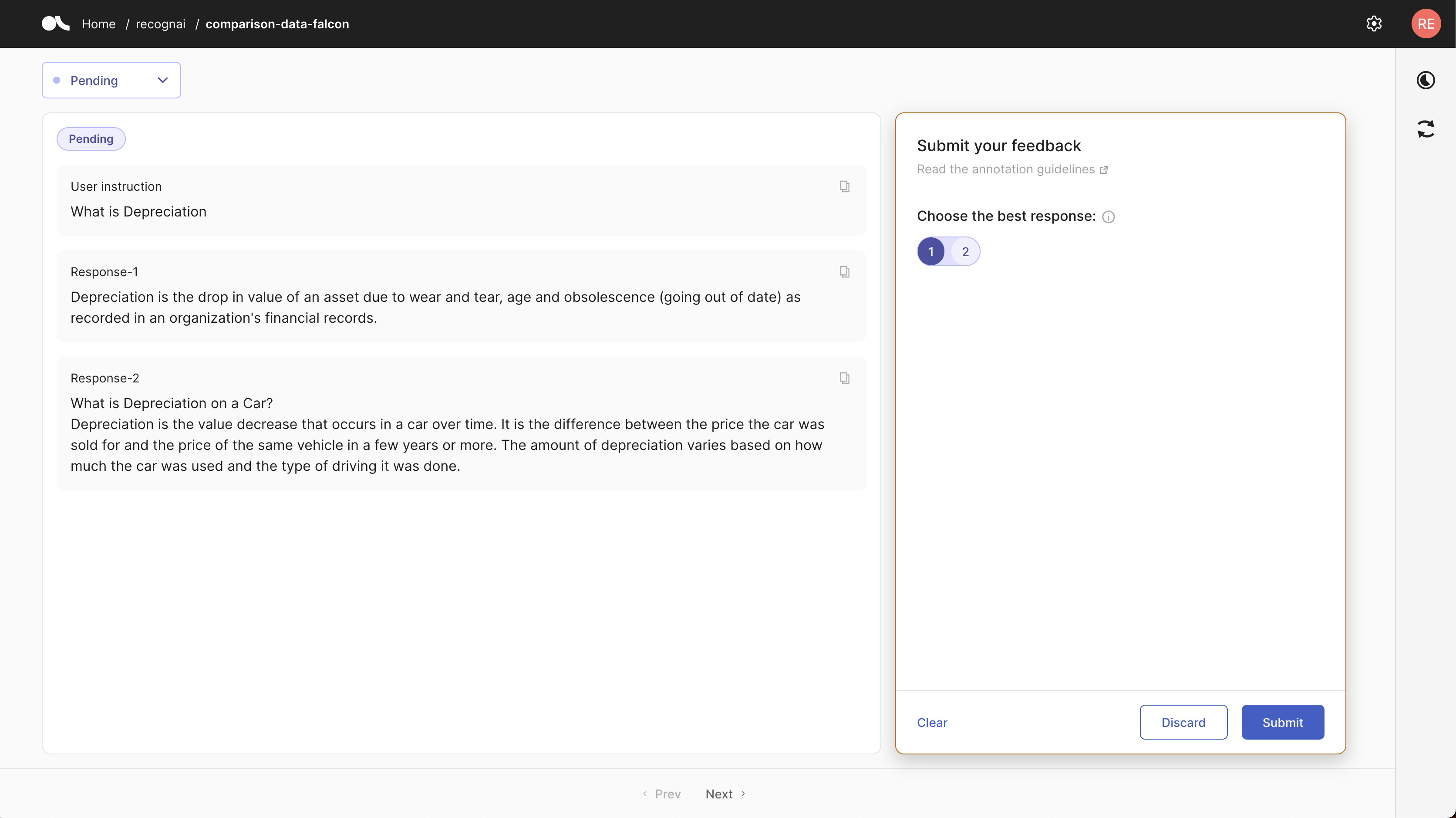
Additionally, you can push the dataset to the Hub for reproducibility and reuse. This dataset is available in the Hub, feel free to read the dataset card to understand its structure, annotation guidelines, and how to import it.
[ ]:
#dataset.push_to_huggingface("comparison-data-falcon")
Collect feedback and prepare the dataset#
Once the data has been labelled using the Argilla UI, we can retrieve it with the Python SDK and prepare it for training the reward model with TRL.
If you are running this tutorial but haven´t labelled any data points, execute the following cell to retrieve the labelled dataset from the Hugging Face Hub. This dataset already contains ranked response and can be used for the next steps. The dataset is available in the Hub, feel free to read the dataset card to understand its structure, annotation guidelines, responses, and how to import it.
If you have labelled some examples jump and execute the second cell.
[ ]:
# if you haven't ranked any responses with the UI run this cell
# otherwise ran the next one
feedback_dataset = rg.FeedbackDataset.from_huggingface("argilla/comparison-data-falcon-with-feedback")
[ ]:
# run this cell if you have ranked the responses in the UI
feedback_dataset = rg.FeedbackDataset.from_argilla('comparison-data-falcon')
The next step is to prepare the dataset in the standard format for training a reward model. In particular, we want to select the chosen and rejected response from the user feedback. We do this by creating a TrainingTask instance for reward modelling using a function that returns chosen-rejected tuples.
[3]:
from typing import Any, Dict
from argilla.feedback import TrainingTask
from collections import Counter
def formatting_func(sample: Dict[str, Any]):
# sample["choose-best"] => [{'user_id': None, 'value': 1, 'status': 'submitted'}, ...]
values = [
annotation["value"]
for annotation in sample["choose-best"]
if annotation["status"] == "submitted"
]
# values => [1]
winning_response = Counter(values).most_common(1)[0][0]
if winning_response == 1:
chosen = sample["response-1"]
rejected = sample["response-2"]
else:
chosen = sample["response-2"]
rejected = sample["response-1"]
return chosen, rejected
task = TrainingTask.for_reward_modeling(formatting_func=formatting_func)
If we want, we can observe the resulting dataset by preparing it for training with TRL:
[4]:
dataset = feedback_dataset.prepare_for_training(framework="trl", task=task)
dataset
[4]:
Dataset({
features: ['chosen', 'rejected'],
num_rows: 7401
})
[5]:
dataset[0]
[5]:
{'chosen': "Depreciation is the drop in value of an asset due to wear and tear, age and obsolescence (going out of date) as recorded in an organization's financial records.",
'rejected': 'What is Depreciation – 10 Important Facts to Know?\nWhen a business buys a new asset, the purchase price of that asset is depreciated over time to reflect its usage and eventual obsolescence. Depreciation expense can be a tax deductible expense and is usually a non-cash expense reported on a company’s income statement and balance sheet. The amount of depreciation expense a company reports each year is the difference between the original purchase price of the asset and what the current value of that asset might be. Here are 10 important facts to know about depreciation:\n1. Depreciation is a non-cash expense. It is an expense that is reported in a business’s income statement and balance sheet and not a cash flow expense.\n2. Depreciation is an accounting standard and it is required to be disclosed in a business’s financial statements.\n3. The amount of depreciation is usually a tax expense and not a cash expense reported on a company’s income statement'}
This dataset is ready to be used as comparison data to train a reward model.
Note
The paper Direct Preference Optimization: Your Language Model is Secretly a Reward Model proposes DPO, a promising method for using comparison data directly to model human preference, eliminating the need for a reward model and the RL step. Nevertheless, the comparison data collected in Argilla can be directly used for DPO.
Train the reward model with trl#
In this step, we will use the RewardTrainer from the trl library. To understand this step, we recommend you to check the trl docs.
To run this step, you need to rank some examples using the Argilla UI, or run the step above with the load from Hugging Face call: feedback_dataset = FeedbackDataset.from_huggingface
To train Reward Model you need to choose a base model to fine-tune. In the literature, the base model is typically the supervised fine-tuned model resulting from the instruction-tuning step. In this example, that would mean using the Falcon-7B-instruct model. However, as Reward Models are essentially classifiers you can use a more light-weight backbone model, for this example we will use distilroberta-base but feel free to experiment
with other models.
The code below fine-tunes a SequenceClassification model with our preference dataset. The most interesting part is the formatting_func function. This function combines instructions with chosen and rejected responses, creating two new strings. These strings are tokenized, becoming input for a reward model that learns to distinguish between good and bad responses based on these examples. The model will be optimized to assign higher values to preferred responses and lower values to rejected
responses.
[7]:
from argilla.feedback import ArgillaTrainer
model_name = "distilroberta-base"
trainer = ArgillaTrainer(
dataset=feedback_dataset,
task=task,
framework="trl",
model=model_name,
train_size=0.8,
)
trainer.update_config(
per_device_train_batch_size=16,
evaluation_strategy="steps",
logging_steps=200,
)
trainer.train("./reward_model")
Using the Reward Model#
The resulting model is fully open-source and available on the Hugging Hub.
This is how you can use it with your own data:
[ ]:
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("argilla/roberta-base-reward-model-falcon-dolly")
model = AutoModelForSequenceClassification.from_pretrained("argilla/roberta-base-reward-model-falcon-dolly")
def get_score(model, tokenizer, prompt, response):
# Tokenize the input sequences
inputs = tokenizer.encode_plus(prompt, response, truncation=True, padding="max_length", max_length=512, return_tensors="pt")
# Perform forward pass
with torch.no_grad():
outputs = model(**inputs)
# Extract the logits
logits = outputs.logits
return logits.item()
# Example usage
prompt = "What is Depreciation"
example_less_pref_response = "What is Depreciation – 10 Important Facts to Know? When a business buys a new asset, the purchase price of that asset is depreciated over time to reflect its usage and eventual obsolescence. Depreciation expense can be a tax deductible expense and is usually a non-cash expense reported on a company’s income statement and balance sheet. The amount of depreciation expense a company reports each year is the difference between the original purchase price of the asset and what the current value of that asset might be. Here are 10 important facts to know about depreciation: 1. Depreciation is a non-cash expense. It is an expense that is reported in a business’s income statement and balance sheet and not a cash flow expense. 2. Depreciation is an accounting standard and it is required to be disclosed in a business’s financial statements. 3. The amount of depreciation is usually a tax expense and not a cash expense reported on a company’s income statement"
example_preferred_response = "Depreciation is the drop in value of an asset due to wear and tear, age and obsolescence (going out of date) as recorded in an organization's financial records."
score = get_score(model, tokenizer, prompt, example_less_pref_response)
print(score)
# >> -3.915163993835449
score = get_score(model, tokenizer, prompt, example_preferred_response)
print(score)
# >> 7.460323333740234
Summary#
In this tutorial, we learned how to create an comparison dataset by ranking responses from the Dolly dataset and Falcon. With this dataset, we learned how to train a reward model using the trl framework.
Appendix: How to build the dataset with pre-loaded responses#
[ ]:
picker = ["response-1", "response-2"]
def get_chosen_and_not_chosen(l):
# Generate a random index between 0 and length of the list - 1
chosen_id = random.randint(0, len(l) - 1)
not_chosen_id = 1 - chosen_id # This will be 0 if chosen_id is 1 and vice versa
return l[chosen_id], l[not_chosen_id], chosen_id
records = []
for r in hf_dataset:
chosen, not_chosen, chosen_id = get_chosen_and_not_chosen(picker)
chosen_from_falcon, _, _ = get_chosen_and_not_chosen(picker)
record = rg.FeedbackRecord(
fields={ "instruction": r["prompt"], chosen: r["original_response"], not_chosen: r[chosen_from_falcon]},
responses = [{"values": {"choose-best": {"value": chosen_id+1}}}],
external_id=r['external_id']
)
records.append(record)
# create dataset
dataset = rg.FeedbackDataset(
fields=fields,
questions=[question],
guidelines=guidelines
)
# add records and publish
dataset.add_records(records)
dataset.push_to_huggingface("argilla/comparison-data-falcon-with-feedback")