🏷 Labelling#
When labelling, we generally differentiate between manual labelling and co-operative or programmatic labelling. During co-operative labelling, we use external input like rules and inference prediction to kickstart our annotation process. Manual labelling is always needed and having a good understanding of the problem is key to getting started, however, co-operative labelling can significantly reduce your time spend labelling.
An annotation guideline#
Before starting the annotation process with a team, it is important to align the different truths everyone in the team thinks they have. Because the same text is going to be annotated by multiple annotators independently or we might want to revisit an old dataset later on. Besides a set of obvious mistakes, we also often encounter uncertain grey areas. Consider the following phrase for NER-annotation Harry Potter and the prisoner of Azkaban can be interpreted in many ways. The entire phrase
is as the movie title, Harry Potter is a person, and Azkaban is location. Maybe we don´t even want to annotate fictional locations and characters. Therefore, it is important to define these assumptions beforehand and iterate over them together with the team. Take a look at this blog from our friends over at suberb.ai or this
blog from Grammarly for more context.
Manual Labelling#
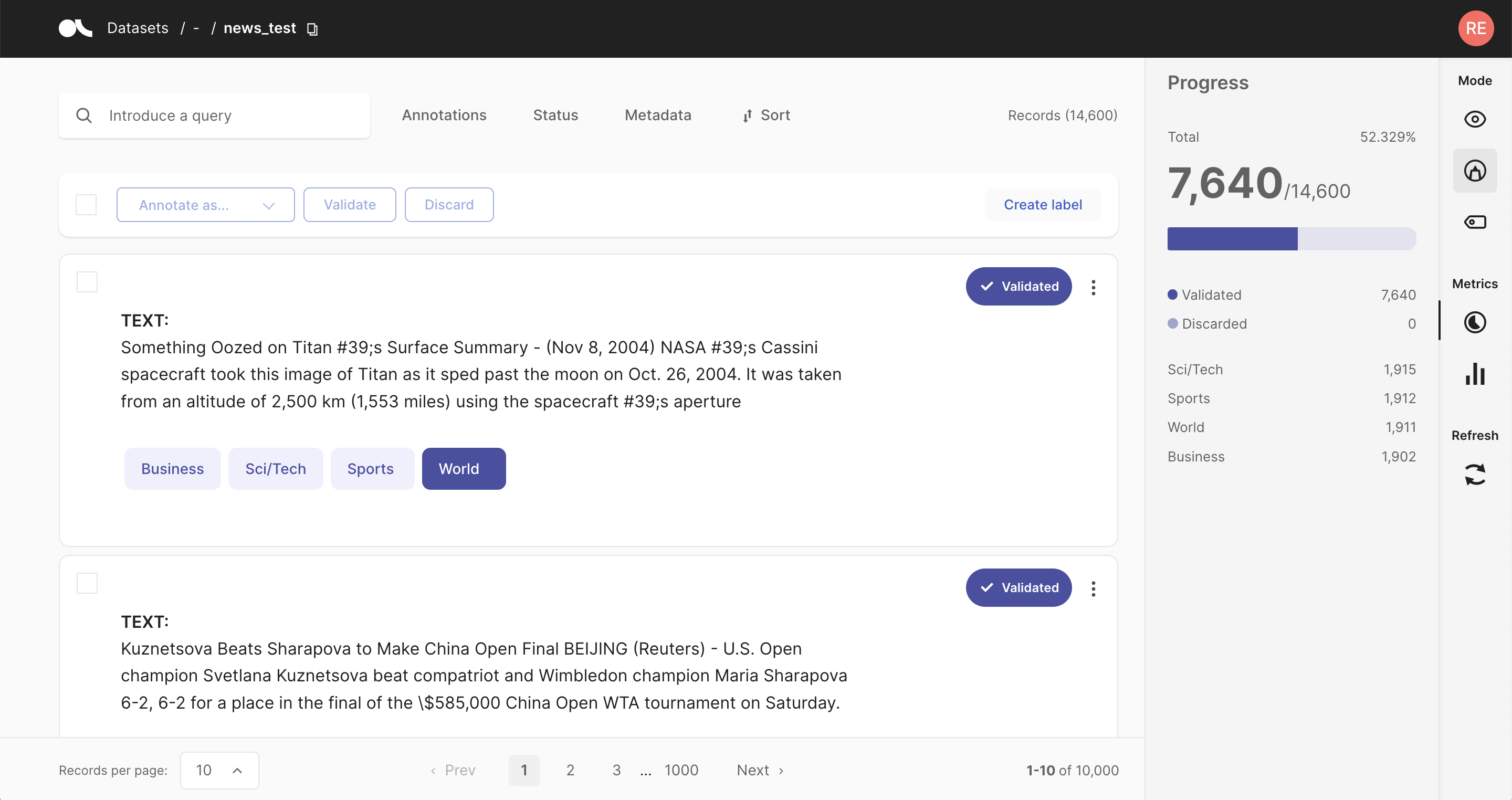
The straightforward approach of manual annotations might be necessary if you do not have a suitable model for your use case or cannot come up with good heuristic rules for your dataset. It can also be a good approach if you dispose of a large annotation workforce or require few but unbiased and high-quality labels.
Argilla tries to make this relatively cumbersome approach as painless as possible. Via an intuitive and adaptive UI, its exhaustive search and filter functionalities, and bulk annotation capabilities, Argilla turns the manual annotation process into an efficient option.
Look at our dedicated feature reference for a detailed and illustrative guide on manually annotating your dataset with Argilla for specific NLP Tasks.
Pre-annotate#
Check the introduction tutorial to learn to add predictions to the records. And our feature reference includes a detailed guide on validating predictions in the Argilla web app.
Pretrained models#
As stated previously, we can also pre-annotate our data using ML models. Within Hugging Face it is quite likely you will find a model that already suits your specific dataset task to some degree. In Argilla, you can pre-annotate your data by including predictions from these models in your records. Assuming that the model works reasonably well on your dataset, you can filter for records with high prediction scores and validate the predictions. In this way, you will rapidly annotate part of your data and alleviate the annotation process.
One downside of this approach is that your annotations will be subject to the possible biases and mistakes of the pre-trained model. When guided by pre-trained models, it is common to see human annotators get influenced by them. Therefore, it is advisable to avoid pre-annotations when building a rigorous test set for the final model evaluation.
Zero and few-shot models#
A special kind of pre-annotation models are zero and few-shot models. These models can create reasonably well predictions while requiring only a few or even zero training samples. A good example of a good few-shot model is found in our tutorial about SetFit and good examples of zero-shot models can be found on the Hugging Face model page.
Weak supervision rules#
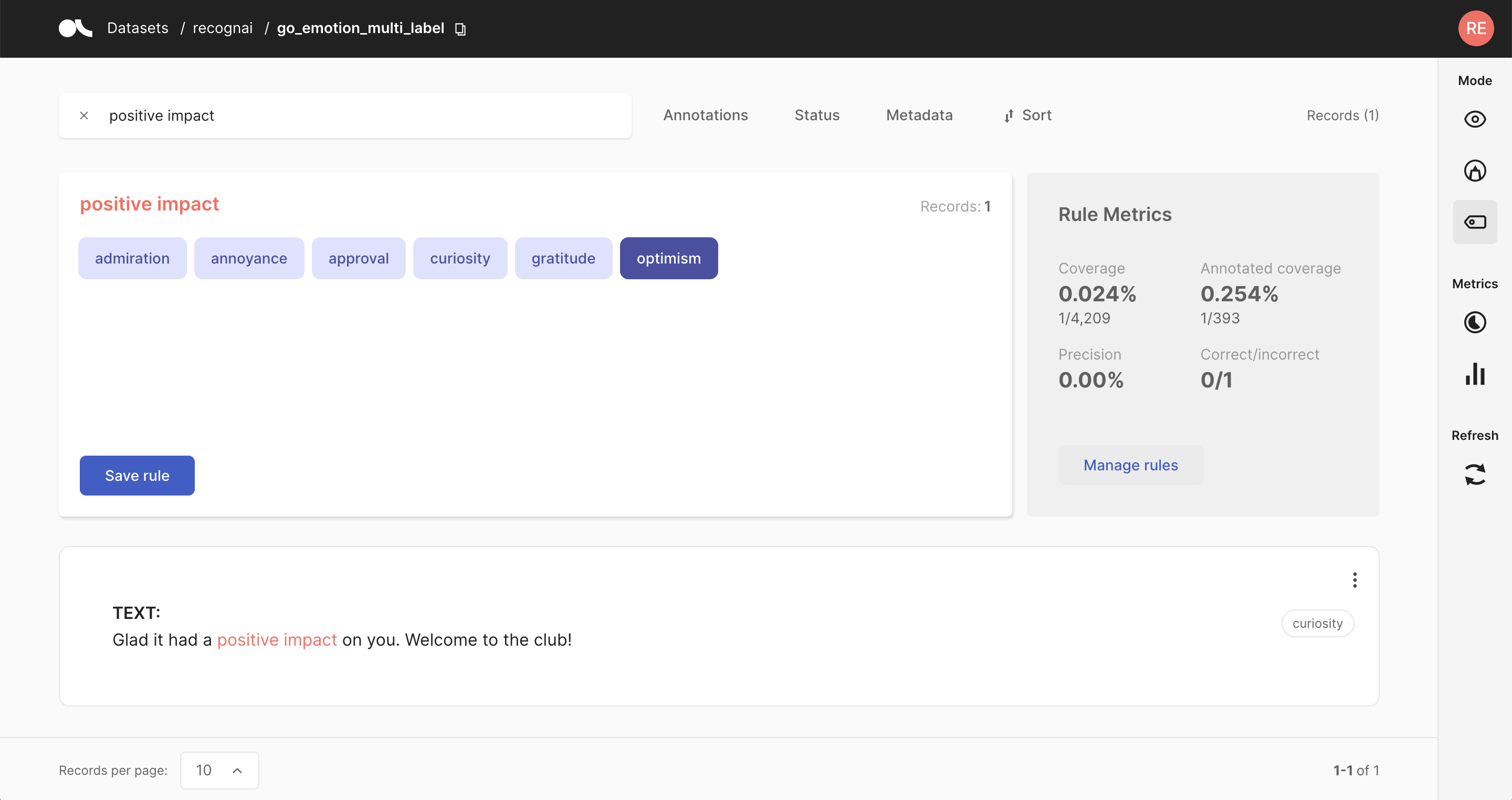
Another approach to annotating your data is to define heuristic rules tailored to your dataset. For example, let us assume you want to classify news articles into the categories of Finance, Sports, and Culture. In this case, a reasonable rule would be to label all articles that include the word “stock” as Finance.
Rules can get arbitrarily complex and can also include the record’s metadata. The downsides of this approach are that it might be challenging to come up with working heuristic rules for some datasets. Furthermore, rules are rarely 100% precise and often conflict with each other. These noisy labels can be cleaned up using weak supervision and label models, or something as simple as majority voting. It is usually a trade-off between the amount of annotated data and the quality of the labels.
Check our guide for an extensive introduction to weak supervision with Argilla. Also, check the feature reference for the Define rules mode of the web app and our various tutorials to see practical examples of weak supervision workflows.